paddleocr部署训练全流程
paddleocr部署训练全流程
1.GPU及环境配置
GPU:GTX1050TI
环境:win11+anaconda
paddleocr版本:PaddleOCR-release-2.4
2.paddle安装
2.1快速开始安装方法(为后续使用标注工具做准备)
能够快速的使用paddleocr
创建conda虚拟环境
conda create -n paddle_quickstart python=3.8
接下来按照下述参考链接安装paddleocr
参考:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.4/doc/doc_ch/quickstart.md
Windows的系统需要我们注意安装shapely时,需要手动下载对应python版本的whl包,在安装
最后在使用参考链接中的代码便可以使用paddleocr进行文字识别工作
tips:如果使用上述步骤不能正常使用,需要下载源码,在conda虚拟环境中通过pip安装requirements.txt
cd PaddleOCR-release-2.4
pip install -r requirements.txt
2.2源码使用安装
参考:https://blog.csdn.net/weixin_42708301/article/details/119864744
参考链接就能够正常安装使用
这里推荐使用另外一个虚拟环境,方便后续标注工具的使用
官方安装:https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/conda/windows-conda.html
安装GPU版本时需要查看自己机器的CUDA版本

3.官方模型使用
3.1快速开始方法模型更改
在这里我们不能确定使用pip安装的paddleocr使用的模型版本,我们对程序进行修改,更换我们所使用的模型
参考:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.4/doc/doc_ch/whl.md
根据参考链接中自定义模型,对使用模型进行修改
3.2源码使用模型方法
3.2.1源码目录构建

新建inference文件夹用来保存下载的模型并解压
新建train_data文件夹保存训练及测试数据
3.2.2模型下载及测试
参考:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.4/doc/doc_ch/models_list.md
根据连接进行模型下载
参考:https://blog.csdn.net/weixin_42708301/article/details/119864744
参考链接模型测试
测试期间推荐使用命令进行测试,单张图片测试见参考链接
python tools/infer/predict_system.py --image_dir="E:\\work\\python\\OCR\\imgs_3000\\img_1495.jpg"
--det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/"
--rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/"
--cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/"
--use_angle_cls=True --use_space_char=True
使用windows批处理命令进行多张图片测试
@echo off
for %I in (1,2,3) do (python tools/infer/predict_system.py --image_dir="E:\\work\\python\\OCR\\imgs_62\\img_%I.jpg"
--det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/"
--rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/"
--cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/"
--use_angle_cls=True --use_space_char=True)
pause
(1,2,3)代表图片序号,批处理的范围命令没有找到,如果100就使用笨办法括号内为(1,2,4,5,···,100)
使用上述命令运行tools/infer/predict_system.py时,就同时进行了det,rec,cls。在py文件中查看识别结果保存路径。
如果想单独运行则单独运行tools/infer/下的对应py文件即可。
单独运行可能会报错,如遇到下述错误:
Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
则在对应py文件中加入下述代码:
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
4.训练自己的模型
4.1数据准备(图片)
参考:https://blog.csdn.net/weixin_42708301/article/details/119868531
参考:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.4/doc/doc_ch/training.md
4.1.1PPOCRLabel标注工具使用
参考:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.4/PPOCRLabel/README_ch.md
推荐在快速开始虚拟环境下安装标注工具以及进行标注
4.2.2构建train_data文件夹
参考:https://blog.csdn.net/weixin_42708301/article/details/119868531
4.2下载训练模型
参考:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.4/doc/doc_ch/models_list.md
4.3修改模型配置文件
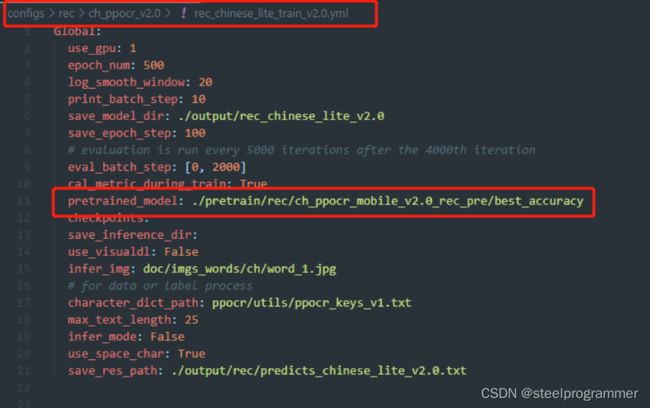

4.4训练模型(在源码安装虚拟环境中)
参考:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.4/doc/doc_ch/training.md
python tools/train.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml
推荐使用gpu训练,我的1050ti在1000张图片时将无法运行
4.5训练结果转换为inferencre模型
# -c 后面设置训练算法的yml配置文件
# -o 配置可选参数
# Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。
# Global.save_inference_dir参数设置转换的模型将保存的地址。
python tools/export_model.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model=./output/rec_chinese_lite_v2.0/latest Global.save_inference_dir=./inference/rec_crnn/
5.使用自训练模型进行识别
可使用3中方法进行使用