python基础爬虫篇
本文为新人自我学习的经验总结。有问题欢迎指出。
目录
(常用库)
基础库
分析库
数据库
(传统爬虫基础流程 )
示例代码
拓展库详情:
(常用库)
基础库
requests库
urllib库
urllib.request
urllib.error
分析库
re库
lxml库
bs4库
数据库
pymysql库
(传统爬虫基础流程 )
下列流程都以京东举例
链接:京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!
1. html分析
通过于浏览器F12 或者右键通过检查打开开发者界面来查看网页的后台源码。
图1-1
![]()
其中 我们关注 元素, 源代码 , 网络 三个板块。
图1-2

元素板块一般就是网页的源码,网页源码由无数标签嵌套组合成的。在这一区域我们只能观察和分析网页的静态内容,但也是我们用于抓取网页内容的重要环节。
图1-3

通过这个按键可以选择网页中的元素进行审查
图1-4

图1-5
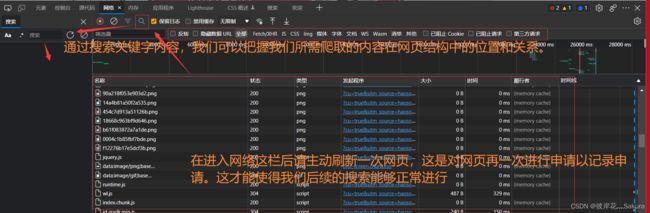
图1-6 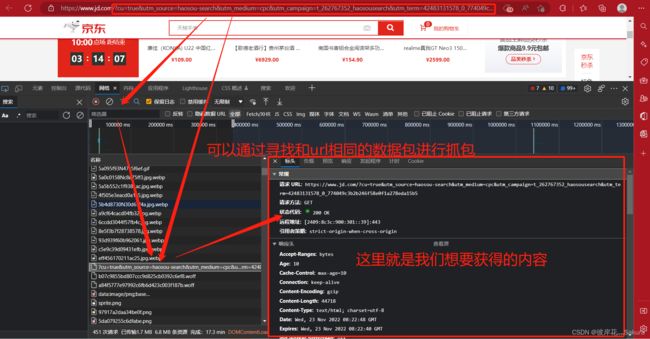
在随后的流程中,我们将通过上述方法获得headers和url以及param
代码阶段
url = 'https://www.jd.com/?'获取url,为后续的网页申请做准备。
param = {
'cu':'true',
'utm_source':'haosou-search',
'utm_medium':'cpc',
'utm_campaign': 't_262767352_haosousearch',
'utm_term': '42483131578_0_b67b44dc2ccd45d7be54a655fdf3b473',
}根据图1-6中的负载一栏,我们可以找到该url的所有参数,虽说可以通过完整复制链接去申请,但为了后面方便复用和翻页功能,我们一般采用字典去存储这部分参数,以便随时调整。 由这两个变量我们可以构造一个完整的url链接。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.56',
'Cookie': '__jdu=1649251728; shshshfpa=a1e88f76-fbbc-0539-d712-7d947d6d8068-1662289515; shshshfpb=iI4caT8FwMh-DsDeJeqiaMA; pin=jd_5a06919cedbdc; unick=jd_5a06919cedbdc; _tp=QSiDtMYw%2FzALW9tIezUjNyiRz1NXxREP%2F%2FocapoBNY4%3D; _pst=jd_5a06919cedbdc; ipLoc-djd=13-1032-1039-57817; mt_xid=V2_52007VwMVV1VbVloZShBsDDUFRVNbXlJGFx4YXxliCkdXQQtXD0tVTg9SYgQbUglfWlkbeRpdBmQfElJBWFJLH0ASWQFsAhRiX2hSahZMH18NYQoXUltoUV0W; o2State={%22webp%22:true%2C%22avif%22:false%2C%22lastvisit%22:1668328918027}; PCSYCityID=CN_370000_370700_0; unpl=JF8EAJpnNSttC0xSVh4HTkATGQ8BW1ldTURXa2JVU1lcHAFSGVEeFBJ7XlVdXhRLFx9sZRRUVFNOVQ4aAysSEXteU11bD00VB2xXXAQDGhUQR09SWEBJJVhXW1QKSxUDa2EMZG1bS2QFGjIbFRVDXlBeWwtCJwJfYDVkbVFCVgweBSsTIEptFgoBAU0QAWxvSFRaXUNXARsEGBsgSm1X; __jda=76161171.1649251728.1662289512.1669191318.1669200003.37; __jdb=76161171.1.1649251728|37.1669200003; __jdc=76161171; __jdv=76161171|haosou-search|t_262767352_haosousearch|cpc|42483131578_0_b67b44dc2ccd45d7be54a655fdf3b473|1669200002523; shshshfp=d6dfcddddeb54656a8395f9b063be160; shshshsID=8b234138d17ed9d758353fce82f61f57_1_1669200004640; 3AB9D23F7A4B3C9B=DYOVDHQM4YVTBF6R3ONTHENUOFTW2TITFZ5U4F56ROJMJQ5X7F5DQ6SWK7C2HVEUFAVWU7MWION457PNFCMHAQ3NVM',
}headers是头文件,常见的网页一般都需要用headers进行一定程度的伪装,user-agent参数可以被视为必加内容,这是证明你从浏览器发出的请求而非从python中发出的请求,而cookie是用于维持你登录状态的一个参数,如果该网页没有登录状态需要维持,那么也可以选择不加,只添加user-agent参数就好。
import requests
url = 'https://www.jd.com/?'
param = {
'cu':'true',
'utm_source':'haosou-search',
'utm_medium':'cpc',
'utm_campaign': 't_262767352_haosousearch',
'utm_term': '42483131578_0_b67b44dc2ccd45d7be54a655fdf3b473',
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.56',
'Cookie': '__jdu=1649251728; shshshfpa=a1e88f76-fbbc-0539-d712-7d947d6d8068-1662289515; shshshfpb=iI4caT8FwMh-DsDeJeqiaMA; pin=jd_5a06919cedbdc; unick=jd_5a06919cedbdc; _tp=QSiDtMYw%2FzALW9tIezUjNyiRz1NXxREP%2F%2FocapoBNY4%3D; _pst=jd_5a06919cedbdc; ipLoc-djd=13-1032-1039-57817; mt_xid=V2_52007VwMVV1VbVloZShBsDDUFRVNbXlJGFx4YXxliCkdXQQtXD0tVTg9SYgQbUglfWlkbeRpdBmQfElJBWFJLH0ASWQFsAhRiX2hSahZMH18NYQoXUltoUV0W; o2State={%22webp%22:true%2C%22avif%22:false%2C%22lastvisit%22:1668328918027}; PCSYCityID=CN_370000_370700_0; unpl=JF8EAJpnNSttC0xSVh4HTkATGQ8BW1ldTURXa2JVU1lcHAFSGVEeFBJ7XlVdXhRLFx9sZRRUVFNOVQ4aAysSEXteU11bD00VB2xXXAQDGhUQR09SWEBJJVhXW1QKSxUDa2EMZG1bS2QFGjIbFRVDXlBeWwtCJwJfYDVkbVFCVgweBSsTIEptFgoBAU0QAWxvSFRaXUNXARsEGBsgSm1X; __jda=76161171.1649251728.1662289512.1669191318.1669200003.37; __jdb=76161171.1.1649251728|37.1669200003; __jdc=76161171; __jdv=76161171|haosou-search|t_262767352_haosousearch|cpc|42483131578_0_b67b44dc2ccd45d7be54a655fdf3b473|1669200002523; shshshfp=d6dfcddddeb54656a8395f9b063be160; shshshsID=8b234138d17ed9d758353fce82f61f57_1_1669200004640; 3AB9D23F7A4B3C9B=DYOVDHQM4YVTBF6R3ONTHENUOFTW2TITFZ5U4F56ROJMJQ5X7F5DQ6SWK7C2HVEUFAVWU7MWION457PNFCMHAQ3NVM',
}
response = requests.get(url = url, param = param, headers = headers)以上,我们就成功对京东首页发出了申请, response的返回值为200,证明申请通过。如果返回的是其他值,详见结尾。

我们在这里查看一下内容的类型是什么,如果是text就用下述方式获得。
html = response.text如果是json型

则采用 当字典使就完事了。
content = response.json()['xx']['xx']以上,我们就拿到了这个页面想要拿到的全部内容了。
但还没有结束,我们仍旧需要对这下数据进行分析,全拿等于没拿。
接下来使用分析库的手段进行分析
re库
import re
import requests
html = response.text
find_xx = re.compile('正则体',re.S)
xx = re.findall(find_xx,html)compile构建了一个正则表达式的对象,主要是用来优化代码结构的。通过compile就可以复用这个正则体,而后面的re.S则表明可以跨行匹配。
而findall则是匹配了html内的所有可匹配的内容,并全部存入了xx中。
xx就是我们需要的内容了,反复通过这样的方式获取到各种内容,用一定的数据处理的方式整理一下,存储起来就好了。
接下来再通过 xpath的方式走一遍
import requests
from lxml import etree
html = response.text
html = etree.HTML(html)
xx = html.xpath("xpath体")然后就是随心所欲的数据处理和整理环节,这一部分不涉及爬虫,所以先跳过了。
数据库存储
因为我所使用的是mysql,数据存储环节可以存储成任意形式的文件,这里就走一下mysql。
import pymysql
db = pymysql.connect(host = 'localhost', user = 'root', password = xxxx, port=3306, db = '数据库名')
cursor = db.cursor
sql = 'CREATE TABLE IF NOT EXISTS XXX (ONE VARCHAR(255) NOT NULL, TWO INT NOT NULL)'
cursor.execute(sql)
db.commit()connect用于连接mysql数据库。
sql变量用于输入sql语句,这样就完成了一次sql语句命令的执行。
通过这样的方式我们可以建立表和将数据导入到数据库中。接下来看一个完整的示例代码。
示例代码
(萌新求大佬们下手轻点,有可改进的可以留言私我,我感谢各位大佬的提携,我会努力学习的!OVO!)
import requests
from lxml import etree
import re
import pymysql
db = pymysql.connect(host="localhost", user="root", pa**word="*******", port=3306, db="spiders")
cursor = db.cursor()
class 京东爬虫(object):
def __init__(self):
self.headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.42',
'cookie': '__jdu=1649251728; shshshfpa=a1e88f76-fbbc-0539-d712-7d947d6d8068-1662289515; shshshfpb=iI4caT8FwMh-DsDeJeqiaMA; qrsc=3; pin=jd_5a06919cedbdc; unick=jd_5a06919cedbdc; _tp=QSiDtMYw%2FzALW9tIezUjNyiRz1NXxREP%2F%2FocapoBNY4%3D; _pst=jd_5a06919cedbdc; areaId=13; ipLoc-djd=13-1032-1039-57817; mt_xid=V2_52007VwMVV1VbVloZShBsDDUFRVNbXlJGFx4YXxliCkdXQQtXD0tVTg9SYgQbUglfWlkbeRpdBmQfElJBWFJLH0ASWQFsAhRiX2hSahZMH18NYQoXUltoUV0W; pinId=AqLM46Wql4wsXXBc6E8qybV9-x-f3wj7; PCSYCityID=CN_370000_370700_0; unpl=JF8EAJpnNSttXhgAUB9XG0EWS1UBW1sPHx4EaTdSBlxQTlQBEgtJG0J7XlVdXhRLFx9vbhRVVFNIVg4aAisSEXteU11bD00VB2xXXAQDGhUQR09SWEBJJVhXW1QKSxUDa2EMZG1bS2QFGjIbFRVDXlBeWwtCJwJfYDVkbV5NVwwfAisTIEptFgoBAUkWAWtmSFRaXUNXARsEGBsgSm1X; __jdv=76161171|haosou-search|t_262767352_haosousearch|cpc|42483131578_0_7bed5d1b719d476e867afc0941588c8c|1668730984645; jsavif=0; jsavif=0; shshshfp=404d28c03f8fc0bcf135f7184db79c8a; __jda=122270672.1649251728.1662289512.1668691588.1668730985.33; __jdc=122270672; rkv=1.0; wlfstk_smdl=3dc99gktsfz06w26xbyrnzunbzasrzcu; logintype=qq; npin=jd_5a06919cedbdc; thor=063EB1D891F4B6E7661AA7F808704D6590AC77F714A2DD088A0F50829BEA883B01A30064059B68D3BF93D95F3FF2F71B489C5D15AC85AFAF87EB557EDF6426B2F534BF9EFCF7D9AA3BD0C134FAA74246D06C35DAD244185A991BBEC671230FC7D33F0C5EA4E52C2D14E7FE8FA0C8D8AEEA744F6B4552F2BB67E58CB125C5064A460A27916B1842E2CC489E9DDA27EC31B2D3D7E8ABDEE2316B7FEA4C9BB370D6; shshshsID=6810582fbcea7818a98c269293e0c8dc_22_1668733741192; __jdb=122270672.26.1649251728|33.1668730985; 3AB9D23F7A4B3C9B=DYOVDHQM4YVTBF6R3ONTHENUOFTW2TITFZ5U4F56ROJMJQ5X7F5DQ6SWK7C2HVEUFAVWU7MWION457PNFCMHAQ3NVM' }
self.品牌地址字典 = {}
self.参数特征收集 = []
def 主函数(self):
self.首页品牌地址爬取(self.首页申请())
self.首页品牌地址申请及爬取skuID()
def 首页申请(self):
url = 'https://search.jd.com/search?'
data ={
'keyword': '显卡',
'cid3': '679',
'_':'1668733485371',
'callback': 'jQuery1851236',
'page': 1,
'adType':7
}
response = requests.get(url=url, params=data, headers=self.headers)
if response.status_code == 200 :
html = response.text
response.close()
return html
else:
print("首页申请失败。错误地址:", url+"&"+"keyword="+data['keyword'])
def 首页品牌地址爬取(self, htmls):
html = etree.HTML(htmls)
print("开始获取该商品所有品牌详情信息地址")
hrefs = html.xpath('//ul[@class="J_valueList v-fixed"]/li/a/@href')
title = html.xpath('//ul[@class="J_valueList v-fixed"]/li/a/@title')
self.品牌地址字典 = dict(zip(title, self.品牌url组合(hrefs)))
print("品牌信息地址存储完毕")
def 品牌url组合(self,params):
list = []
for i in params:
base_url = 'https://search.jd.com/'
url = base_url+i
list.append(url)
return list
def 首页品牌地址申请及爬取skuID(self):
for i in self.品牌地址字典.keys():
url = self.品牌地址字典[i]
response = requests.get(url=url, headers=self.headers)
if response.status_code == 200:
html = response.text
response.close()
品牌商品 = self.翻页器(url, self.获取页数(html))
self.品牌建表(i)
self.数据存储(品牌商品, i)
else:
print("申请错误,错误地址:", url)
def 获取页数(self,htmls):
html = etree.HTML(htmls)
总页数 = html.xpath('//div[@id="J_topPage"]//i/text()')
return int(总页数[0])
def 翻页器(self, url, sum_page):
sum_page_list = []
for i in range(1, (sum_page*2)+1):
data = {
'page': i,
's': 1+((i-1)*30),
'click':1
}
response = requests.get(url=url, params=data, headers=self.headers)
if response.status_code == 200:
html = response.text
response.close()
sum_page_list.append(self.获取skuID(html))
print(f"完成{i}页信息爬取")
else:
print("翻页器申请错误")
print("完成该品牌全部商品爬取。")
return sum_page_list
def 获取skuID(self, htmls):
html = etree.HTML(htmls)
skuID_list = html.xpath('//ul[@class="gl-warp clearfix"]/li/@data-sku')
page_data_list =[]
for i in skuID_list:
url = 'https://item.jd.com/'+i+'.html'
page_data_list.append(self.详情页申请(url))
return page_data_list
def 详情页申请(self, url):
response = requests.get(url, headers=self.headers)
if response.status_code == 200:
html = response.text
response.close()
return self.信息爬取(html)
else:
print("详情页申请错误,地址:", url)
def 信息爬取(self, htmls):
html = etree.HTML(htmls)
商品参数 = html.xpath('//ul[@class="parameter2 p-parameter-list"]/li/text()')
商品数据字典 = self.商品参数数据规整(商品参数)
print("商品数据规整完毕")
return 商品数据字典
def 商品参数数据规整(self, 商品参数):
dict_s = {}
for i in 商品参数:
list = i.split(":")
list_title=[]
list_values=[]
#list_title.append(list[0])
if re.search("\W*",list[1]) == None:
list_values.append(list[1])
else:
content = list[1]
list_values.append(f'`{content}`')
if re.search("\W*",list[0]) == None:
list_title.append(list[0])
self.参数特征收集.append(list[0])
else:
content = list[0]
list_title.append(f'`{content}`')
self.参数特征收集.append(f'`{content}`')
字典化 = dict(zip(list_title, list_values))
dict_s.update(字典化)
return dict_s
def 品牌建表(self, name):
特征去重 = set(self.参数特征收集)
特征去重 = list(特征去重)
特征 = ' VARCHAR(255),'.join(特征去重)
特征 = 特征+" VARCHAR(255)"
sql = f'CREATE TABLE IF NOT EXISTS {name}({特征})'
cursor.execute(sql)
db.commit()
print("建表完成")
def 数据存储(self,品牌商品们, name):
for 页数 in range(len(品牌商品们)):
for 商品 in 品牌商品们[页数]:
索引字 =list(商品.keys())
特征值 =list(商品.values())
索引 = ",".join(索引字)
特征=""
for i in 特征值:
特征 +=f' "{i}",'
特征 = 特征[:-1]
sql=f"INSERT INTO {name}({索引}) VALUES ({特征})"
cursor.execute(sql)
db.commit()
print("单页存储完毕")
print(f"第{页数}页存储完毕")
if __name__ == "__main__":
京东爬虫().主函数()拓展库详情:
requests
re
lxml
bs4
urllib
补充
网络响应代码(转载自ddhsea的博客记录)