小林网站mysql基础篇 执行器
执行器
上篇我们总结到查询缓存作为一个鸡肋的功能,对于频繁更新的表,查询缓存可能还没有等到被利用,就被清除掉了,所以在mysql8之后,之前将这个模块去掉了;对于解析器,词法解析将关键词以及构建sql语法树,语法分析根据词法分析的结果,判断这个sql语句是否满足语法。对于满足语法的sql语句,将由优化器进行判断,如何执行更有效率,生成执行计划,后面的任务就交给了执行器。
在执行的过程中,执行器就会和存储引擎交互了,交互是以记录为单位的。
后面以分析三种执行过程为例,执行器与存储引擎的交互过程
- 主键索引查询
- 全部扫描
- 索引下推
主键索引查询
select * from emp where id =2;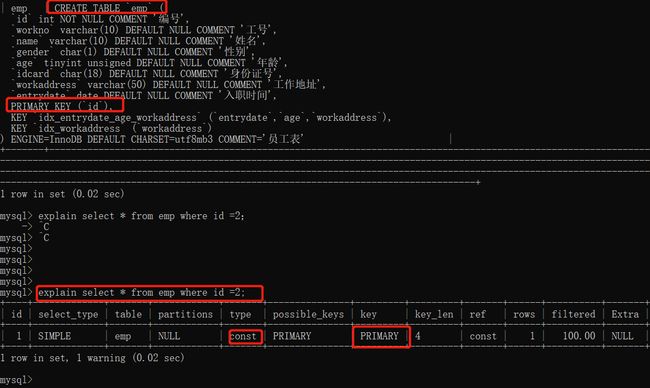
查询条件中用到了主键索引,而且是等值查询,对于主键来说唯一,不同有id相同的记录,所以优化器决定选用访问类型为const进行查询,也就是主键索引查询一条记录。执行器与存储引擎的交互流程是这样的。
- 执行器第一次查询,会调用read_first_record 函数指标指向的函数,因为优化器选择的访问类型为const,这个函数的指针被指向为InnDB引擎的索引查询的接口,把条件id=1交给存储引擎,让存储引擎定位到符合条件的第一条记录
- 存储引擎通过主键索引的B+树结构定位到id=1的第一条记录,如果记录不存在,就会向执行器上报找不到记录的错误,然后结束查询,如果记录存在,返回记录给执行器。
- 执行器从存储引擎读到记录之后,会接着判断记录是否符合其他的查询条件,如果符合则发送给客户端,如果不符合则跳过该记录。
- 执行器的查询过程是一个do while循环,所以还是会再查一次,但是因为不会第一次查询,所以会调用read_record函数指针指向的函数,还是因为优化器选择的访问类型为const, 这个函数指针被指向为永远返回-1的函数,所以调用函数的时候,执行器就会推出循环,也就是结束查询
全表扫描
select * from emp where name='张三';
执行这条语句没有用到索引,所以优化器决定选用的访问类型为ALl进行查询,也就是全表扫描,那么这时执行器与存储引擎的执行流程是这样。
- 执行器第一次查询,会调用read_first_record函数指针指向的函数,因为优化器选择的访问类型为All,让存储引擎读取表的第一条记录
- 执行器会判断读取的这条记录的name是不是张三,如果不是则跳过,如果是则将记录发送给客户端(server 层没从存储引擎读到一条记录就会发送给客户端,之所以客户端的显示的时候直接显示所有记录,是因为客户端等查询语句完成后,才会显示出所有记录)
- 执行器查询是一个do while循环,还是会继续调用read_record函数指针指向的函数,存储引擎把下一条记录取出后就将其返回执行器,然后判断如果符合条件,就返回客户端,如果不符合就跳过该记录,重复这个过程,直到存储引擎把表里记录读完。
- 执行器收到存储引擎报告的所有记录,推出循环,停止查询
索引下推
案例1:
select * from emp where entrydate='2020-12-23' and name ='张三'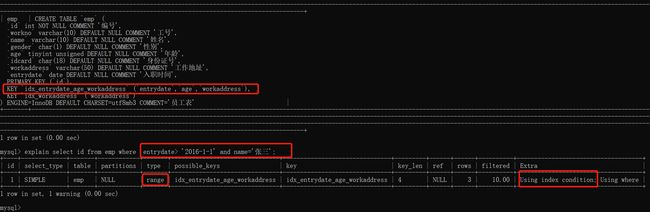
explain select * from user1 where name like '黄%' and age =12;案例2: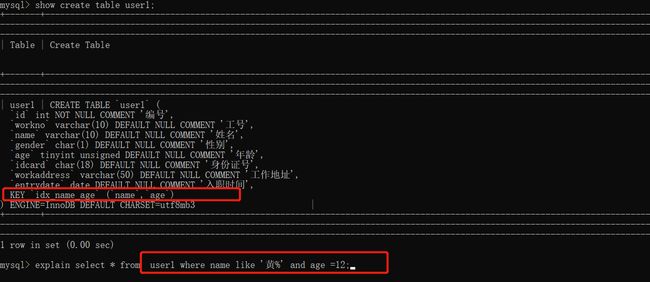
案例3:
索引下推能够减少二级索引(普通索引或者联合索引)在查询是的回表操作,提高查询的效率,因为它将server层负责处理的事情交给了引擎层去处理了。
使用ICP的情况下,查询过程:(只有符合条件去做回表的操作,不符合条件的就跳过)
- 存储引擎读取索引记录(不是完整的行记录);
- 判断条件部分能否用索引中的列来做检查,条件不满足,则处理下一行索引记录;
- 条件满足,使用索引中的主键去定位并读取完整的行记录(就是所谓的回表);
- 存储引擎把记录交给server层,server层检测该记录是否满足条件的其余部分。
在没有ICP的情况下,查询过程如下,MySQL的查询:(每条记录都要进行回表的操作)
- 存储引擎读取索引记录;
- 根据索引中的主键值,定位并读取完整的行记录;
- 存储引擎把记录交给Server层去检测该记录是否满足WHERE条件。
索引下推使用条件
- 只能用于range、 ref、 eq_ref、ref_or_null访问方法;
- 只能用于InnoDB和 MyISAM存储引擎及其分区表;
- 对存储引擎来说,索引下推只适用于二级索引(也叫辅助索引);
索引下推的系统参数
设置索引下推的开关参数
set ="index_condition_pushdown=off";
set ="index_condition_pushdown=on";