分布式可视化作业调度平台 DolphinScheduler:MasterServer
1、导读
Apache DolphinScheduler 是一个分布式易扩展的可视化 DAG 工作流任务调度平台,致力于解决数据处理流程中错综复杂的依赖关系,使得调度系统在数据处理流程中开箱即用。自 2019 年开源以来,得益于其自身的稳定性、易用性、扩展性和完备的功能备受关注,笔者收集了一些业界案例:
-
有赞:全面从 Airflow 迁移到 DolphinScheduler,日均调度 6w+ 任务实例;
-
360数科:全面从 Azkaban 迁移到 DolphinScheduler,日均调度 1w+ 任务实例;
-
Fordeal:全面从 Azkaban 迁移到 DolphinScheduler,日均调度 3500+ 工作流实例、1.5w+ 任务实例;
-
新网银行:借助 DolphinScheduler 调度实时跑批、准实时跑批和指标管理系统的离线跑批,日均 9000+ 任务实例;
-
中国联通:借助 DolphinScheduler 调度处理 Spark/Flink/SeaTunnel 等作业,业务涵盖稽核、收入分摊、计费业务,日均调度 300+ 工作流实例、5000+ 任务实例,业务覆盖 3 地 4 集群;
-
T3出行:结合 DolphinScheduler + Kyuubi on Spark,日均处理 3w+ 离线调度任务、300+ Spark Streaming 任务、100+ Flink 任务、500+ Kylin、ClickHouse 和 Shell 任务;
-
联通数科:借助 DolphinScheduler 调度大数据调度任务和数仓计算任务(如 Spark/Flink 等),日均调度 1w+ 工作流实例、7w+ 个任务实例、集群规模 80+ 个节点;
-
联通医疗:基于 DolphinScheduler 构建了涵盖数据采集、同步、处理和治理为一体的大数据平台,日均调度 6000+ 任务实例;
-
伊利集团:借助 DolphinScheduler 构建了一个统一的数据集成、开发、调度和运维的多云大数据平台,日均调度任务数达到 1.3 万个,每日搬迁 8000+ 张表,集群规模 15 个节点,涉及 4 朵云(阿里云+腾讯云+京东云+自建云),80 多个业务系统;
本文是基于 3.0.0-release 正式版本分析讨论,笔者水平有限,若有不当之处,请不吝指正。
2、业界主流产品对比
| DolphinScheduler |
XXL-JOB |
Azkaban |
Airflow |
Hera |
||
| 开源社区 |
组织 |
Apache |
美团点评 |
|
Airbnb |
基于阿里开源调度系统(zeus)二次开发 |
| 活跃度 |
极高 |
高 |
低 |
低 |
极低 |
|
| 文档 |
完善 |
完善 |
完善 |
完善 |
完善 |
|
| Github热度 |
9.9k Stars |
22.7k Stars |
4.1k Stars |
27.8k Stars |
600 Stars |
|
| 开发语言 |
Java |
Java |
Java |
Python |
Java |
|
| 稳定性 |
单点问题 |
✕ |
✕ |
✕ |
✓ |
✓ |
| 高可用 |
✓ |
✓ |
✓ |
✓ |
✓ |
|
| 过载处理 |
任务队列机制。任务数超过队列容量时阻塞,起到反压作用,单机队列容量可配置; |
任务队列机制 |
Executor负载过高可能导致任务积压;分钟级和小时级任务容易漏调度; |
任务队列机制 |
任务队列机制 |
|
| 特性 |
可视化 |
支持可视化绘制DAG、任务详情、任务执行详情、监控告警信息、机器信息等 |
不支持可视化绘制DAG,创建和修改DAG需通过代码开发; |
只能通过代码绘制DAG,不适用于编码水平不足的用户;DAG运行后仅能看到任务状态 |
只能通过代码绘制DAG,不适用于编码水平不足的用户;DAG运行后无法直观区分任务类型 |
可视化任务详情、任务执行详情、监控告警信息、机器信息等 |
| 第三方集成 |
提供RESTful API,支持跨语言 |
提供RESTful API,支持跨语言 |
开发复杂度高 |
开发复杂度高,Python技术栈,运维迭代成本高 |
提供RESTful API,支持跨语言 |
|
| 暂停、恢复 |
✓ |
✓ |
✕ |
✕ |
✓ |
|
| 多租户 |
✓ |
✕ |
✕ |
✕ |
✓ |
|
| 权限控制 |
✓ |
✓ |
✓ |
✕ |
✓ |
|
| 补数据 |
✓ |
✕ |
✕ |
✓ |
✕ |
|
| 作业告警 |
✓ |
✓ |
✓ |
✓ |
✓ |
|
| 定时调度 |
✓ |
✓ |
✓ |
✓ |
✓ |
|
| 任务类型 |
Shell批处理任务、大数据调度任务(MR、Spark、Flink、Pigeon、SQL、Python、DataX、Amazon EMR等) |
Shell、Python、NodeJS、PHP、PowerShell等 |
Shell、Spark、Pig、Java、Hive等 |
Bash、MySQL、Hive、Email、HTTP等 |
shell、python、SQL、Spark、Hive、MR、Sqoop等 |
|
| 扩展性 |
支持自定义任务 |
✓ |
✓ |
✓ |
✓ |
✓ |
| 支持水平扩缩 |
✓ |
✓ |
✓ |
✓ |
✓ |
|
| 支持集群扩展 |
支持K8S/Docker,支持无状态水平扩缩 |
支持Docker,支持无状态水平扩缩 |
复杂 |
复杂 |
复杂 |
|
| 缺陷 |
MasterServer 维护较多任务实例的线程跟踪任务状态,可能导致单机CPU负载高 |
1、无法满足大数据体系的调度 2、节点注册和心跳探测是基于周期性HTTP请求,性能和可靠性相比ZooKeeper弱; |
1、工作流上的任务只能在一个Executor执行,不能分发至多个Executor上执行,这点限制了调度能力,可能导致资源分布不均衡; 2、稳定性低。Executor负载过高时,任务经常会出现积压,小时级别或分钟级别的任务容易出现漏调度; 3、不支持可视化编排DAG,使用门槛高; 4、集群化部署繁琐; |
1、DAG任务并发度低; 2、不满足实时性要求高的场景; 3、不支持可视化编排DAG,使用门槛高; 4、集群化部署繁琐; |
社区规模相对小众,用户体量少,活跃度低,问题修复和新特性支持面临局限 |
|
3、架构设计
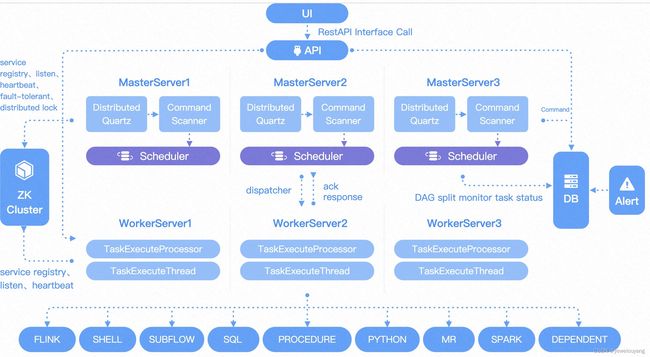
图片来源:Apache DolphinScheduler官网首页
核心组件包括如下:
-
ApiServer:对外统一提供 RESTful API,涵盖工作流的增删改查、上下线、启动、暂停、恢复、从指定节点开始执行、任务执行状态的查看等;
-
AlertServer:一方面负责对外提供告警接口,另一方面负责定时发送集群级别和用户业务级别的告警信息;
-
MasterServer:采用分布式去中心化设计,内部集成Quartz服务,主要负责工作流DAG的任务切分、监听任务提交情况、监听其它MasterServer/WorkerServer的健康状态;启动时主动向ZooKeeper注册临时节点,并通过监听ZooKeeper进行容错;
-
WorkerServer:采用分布式去中心化设计,主要负责DAG任务的执行和提供日志查询服务;启动时主动向ZooKeeper注册临时节点,并周期性上报心跳信息;
4、MasterServer 设计要点
4.1、核心服务
MasterServer 的核心服务如下:
-
Scheduler:分布式调度组件,主要负责Quartz定时任务的启动,当Quartz调度任务后,MasterServer内部任务线程池负责处理任务的后续操作;
-
MasterRegistryClient:ZooKeeper客户端,封装了MasterServer与ZooKeeper相关的操作,例如注册、监听、删除、注销等;
-
MasterConnectionStateListener:监听MasterServer和ZooKeeper连接状态,一旦断连则触发MasterServer的自杀逻辑;
-
MasterRegistryDataListener:监听ZooKeeper的MasterServer临时节点事件,一旦发生节点移除事件,则先移除ZooKeeper上的临时节点,再触发MasterServer的故障转移(过程和FailoverExecuteThread一致);
-
-
MasterSchedulerBootstrap:调度线程,每隔一段时间扫描DB,按照分片策略批量取出Command,封装成工作流任务执行线程(WorkflowExecuteThread),投放至缓冲队列中,等待下一个线程消费;
-
FailoverExecuteThread:故障转移线程,每隔一段时间扫描DB,筛选出分配到故障节点的工作流实例,向WorkerServer发送TaskKillRequestCommand请求杀死运行中的任务;向Command表写入RECOVER_TOLERANCE_FAULT_PROCESS记录,等待MasterServer消费;
-
EventExecuteService:工作流的执行线程,包含两部分:
-
ProcessInstanceExecCacheManager:工作流实例的缓冲队列。MasterSchedulerBootstrap按照分片策略取出Command,封装成工作流实例执行线程(WorkflowExecuteThread)后投放;
-
WorkflowExecuteThreadPool:从缓冲队列中取出WorkflowExecuteThread,并监听线程的执行情况(执行前先检查是否已经被其它线程启动);
-
-
TaskPriorityQueueConsumer:任务队列消费线程,根据负载均衡算法将任务分发至Worker;
-
TaskPluginManager:任务插件管理器,启动时会将TaskChannelFactory的所有实现类持久化到t_ds_plugin表中;因此,如果开发者需要自定义任务插件,只需集成实现TaskChannelFactory即可;
-
MasterRPCServer:MasterServer RPC服务端,封装了Netty服务端创建等通用逻辑,并注册了各种消息处理器:
-
CacheProcessor:接收来自ApiServer的CacheExpireCommand请求,强制刷新缓存;
-
LoggerRequestProcessor:接收来自ApiServer的GetLogBytesRequestCommand、ViewLogRequestCommand、RollViewLogRequestCommand、RemoveTaskLogRequestCommand请求,操作日志;
-
StateEventProcessor:接收StateEventChangeCommand请求,处理工作流实例/任务实例的状态变更,包括工作流实例/任务实例的提交成功、运行中、成功、失败、超时、杀死、准备暂停、暂停、准备停止、停止、准备阻塞、阻塞、故障转移等;
-
TaskEventProcessor:接收TaskEventChangeCommand请求,处理任务实例的状态变更,包括:强制启动、唤醒;
-
TaskKillResponseProcessor:接收来自WorkerServer的TaskKillResponseCommand请求,请求内容是杀死任务实例请求的响应结果;
-
TaskExecuteRunningProcessor:接收来自WorkerServer的TaskExecuteRunningCommand请求,请求内容是任务实例的运行信息(工作流实例ID、任务实例ID、运行状态、执行机器信息、开始时间、程序运行目录、日志目录等);
-
TaskExecuteResponseProcessor:接收来自WorkerServer的TaskExecuteResultCommand请求,请求内容是任务实例的运行结果信息(工作流实例ID、任务实例ID、开始时间、结束时间、运行状态、执行机器信息、程序运行目录、日志目录等);
-
WorkflowExecutingDataRequestProcessor:接收来自ApiServer的WorkflowExecutingDataRequestCommand请求,向指定的WorkerServer查询执行中的工作流实例信息;
-
4.2、自治去中心化
分布式系统的架构设计基本分为“中心化”和“去中心化”两种,取决于业务用途,各有优劣:
4.2.1、中心化的设计思想
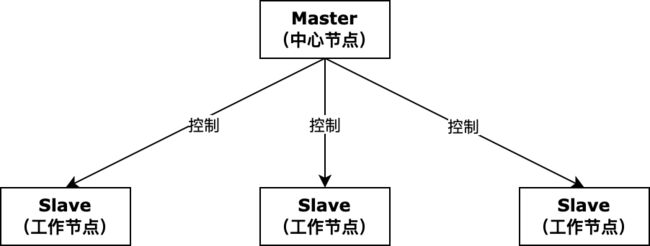
通常采用Master/Slave主从模式,分布式集群中的节点机器按照角色分工,Master节点通常负责均衡分发任务并监听Slave节点的健康状态,当某个Slave节点宕机,Master节点往往会剔除该节点,并将该节点上的任务转移至其它Slave节点执行;中心化的设计思想存在两个主要问题:
-
单点故障:如果Master节点宕机则集群就会崩溃,为了解决这问题,大多数中心化系统都采用Master主备切换的设计方案,可以是热备或者冷备,也可以是自动切换或者手动切换,越来越多的中心化系统都具备自动选举切换Master的能力,以提升系统的高可用性;
-
Master过载:如果系统设计和实现不完善,例如Master节点上的任务并发量过大、业务逻辑过于复杂,可能会导致Master节点负载过高,那么系统性能瓶颈就卡在Master节点上;
4.2.2、去中心化设计思想

相对于中心化设计,在去中心的系统网络中,没有“主”、“从”节点的角色区分,每个节点都是平等且自由的关系,没有谁依赖谁,全球互联网就是一个典型的去中心化的分布式系统,联网的任意节点设备宕机,都只会影响很小范围的功能;去中心化设计的核心设计在于整个分布式系统中不存在一个区别于其他的Master节点,因此不存在单点故障问题。
在中心化设计中,Master节点存储着系统中所有的节点信息,并可以实时将这些信息同步到其它节点,同时可以利用诸如Raft、Paxos等算法达到一致性。但在去中心化设计中,由于不存在Master节点,所以每个节点都需要跟其他节点不断通信才能获取整个系统的节点信息,而分布式系统间网络通信的不可靠性,则大大增加了上述功能的实现难度;
去中心化设计中最难解决的是“脑裂”问题,这种情况的发生概率低,但影响很大。脑裂指一个集群由于网络通信故障,被分为至少两个彼此无法通信的单独集群,此时如果两个集群都各自工作,则可能产生数据冲突;
4.2.3、DolphinScheduler 的设计思想
DolphinScheduler 在架构设计初期,考虑到如果采用中心化设计,除了单点故障问题,还会面临DAG分发的问题,如果调度器(Scheduler)在Master上,虽然可以支持一个DAG中不同的任务分发到不同的机器上,但是可能会导致Master的高负载;而如果调度器(Scheduler)在Slave上,则一个DAG中所有的任务都只能在某一台机器上进行作业提交,当并行任务数比较多时,Slave的压力可能会很大;
最终 DolphinScheduler 采用去中心化设计,其架构设计思路是MasterServer/WorkerServer各自注册到Zookeeper,实现MasterServer/WorkerServer集群无中心。另外由于网络抖动,可能会使得节点短时间内失去和ZooKeeper的心跳,从而发生znode临时节点的移除事件,触发脑裂问题(MasterServer节点假死,仍在分发工作流),对于这种场景,直接将对应的MasterServer/WorkerServer节点服务停掉;
4.3、缓存策略
MasterServer 调度过程中,有大量的数据库读操作,例如t_ds_user、t_ds_tenant、t_ds_process_definition、t_ds_task_definition表等,考虑到这部分业务数据是读多写少的场景,开发者引入缓存机制,一方面减少DB读压力,另一方面加快核心调度流程;
-
缓存管理:采用 caffeine,可调整缓存相关配置,例如缓存大小、过期时间等;
-
缓存读取:采用 spring-cache 机制,可直接在Spring配置文件中决定是否开启(默认关闭),配置在相关的 Java Mapper 层;
-
缓存刷新:通过 AOP 切面 @CacheEvict 监听 ApiServer 接口的业务数据更新,当有数据更新时会通过 Netty 发送 CacheExpireCommand 请求通知 MasterServer 进行缓存驱逐;
4.4、任务分发
4.4.1、分片机制
分片策略是为了保证密集调度的高效性,以及解决任务重复分发执行的问题。调度密集或者耗时任务可能会导致任务阻塞,在分布式集群场景下,调度组件会小概率重复分发,针对这种情况,通常结合 “单机路由策略(如:一致性哈希)” + “阻塞策略(如:丢弃后续调度)” 来规避,最终避免任务重复执行;
无论是用户手动触发,还是定时调度器触发的工作流任务,都会先封装成命令并持久化至元数据DB中,随后等待MasterServer分发调度,MasterServer中的MasterSchedulerBootstrap线程会每隔一段时间扫描Command表,取出命令、封装后投放至任务队列,等待线程消费;
由于采用去中心化的设计思想,DolphinScheduler集群会有一定数量的MasterServer节点在同时工作,意味着同一时刻可能会有多个MasterServer节点在扫描Command表,如果多个MasterServer都取到同一条Command则会导致工作流任务被执行若干次,这显然是不合理的,为了保证单条命令只能由一个MasterServer接管,开发者设计了分片机制,原理比较简单,MasterServer从Command表分页获取满足 Id % MasterCount = MasterSlotId 的记录行,其中:
-
Id:Command表中的记录ID;
-
MasterCount:分片总数,成功注册在ZooKeeper的MasterServer总数;
-
MasterSlotId:分片序号,当前MasterServer在ZooKeeper的位置索引;
例如集群有3个MasterServer,按照分片策略,Command表记录会公平分配到每个MasterServer。值得说明的是,分片是以 MasterServer 为维度,动态扩容 MasterServer 以增加分片数量,在进行大数据量业务操作时可有效提升任务处理能力和速度:
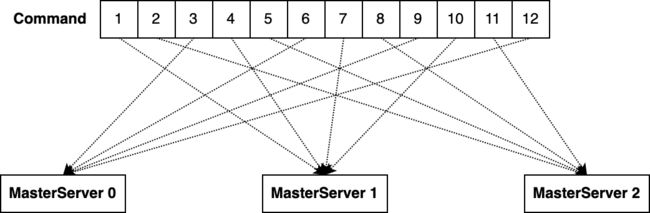
下面思考一个问题,如何保证同一个命令只被一个MasterServer执行?在任务分片路由的过程中,假如 MasterServer 正在做水平扩缩,由于 MasterServer 的分片总数和分片索引发生变化,可能会导致同一个命令被分发至不同的 MasterServer 中,如下图例子,扩容了1台 MasterServer,id=6的命令根据哈希计算又分配给了MasterServer 3,为了避免同一个命令被重复执行,MasterServer 在领取到命令后,会通过数据库事务完成命令和工作流实例的转换、删除命令等操作,如果删除操作失败便回滚事务,意味着命令已经被其它MasterServer认领,则丢弃调度,这样即可保证同一个命令只能被一个MasterServer执行;

4.4.2、负载均衡策略
MasterServer将DAG任务下发至WorkerServer前,会根据负载均衡策略选出合适的WorkerServer节点,而负载均衡策略有如下三种:
-
加权随机(Random):随机选择一个节点;算法缺点是所有节点被访问到的概率是相同的,具有不可预测性,在一次完整的轮询中,有可能负载低的完全没被选中,而负载高的频繁被选中;
-
加权轮询(LowerWeight):默认策略。WorkerServer节点每隔一段时间向ZooKeeper上报心跳信息(包含cpuload、可用物理内存、启动时间、线程数量等信息),MasterServer分发任务时根据WorkerServer节点的CPU Load平均值、可用物理内存、系统平均负载、服务启动耗时计算节点权重值,值越大意味着节点负载越低,选中的优先级越高;算法缺点是在某些特殊的权重下,会生成不均匀的序列,这种不平滑的负载可能会导致节点出现瞬间高负载的现象,导致节点存在宕机风险;
-
平滑加权轮询(RoundRobin):节点宕机时降低有效权重值,节点正常时提高有效权重值;降权起到缓慢剔除宕机节点的效果,提权起到缓冲恢复宕机节点的效果;
所有的负载均衡算法都是基于WorkerServer节点的权重进行加权计算的,权重影响分发结果,考虑到JIT优化,Worker在启动后会低功率地运行一段时间(默认十分钟),随后逐渐达到最佳性能,此过程称为“JVM 预热”,预热期间WorkerServer节点的权重会缓慢动态调整,实现代码可参见 HostWeight 类;
private double calculateWeight(double cpu, double memory, double loadAverage, long startTime) {
double calculatedWeight = cpu * CPU_FACTOR + memory * MEMORY_FACTOR + loadAverage * LOAD_AVERAGE_FACTOR;
long uptime = System.currentTimeMillis() - startTime;
if (uptime > 0 && uptime < Constants.WARM_UP_TIME) {
// If the warm-up is not over, add the weight
return calculatedWeight * Constants.WARM_UP_TIME / uptime;
}
return calculatedWeight;
}4.4.3、召回策略
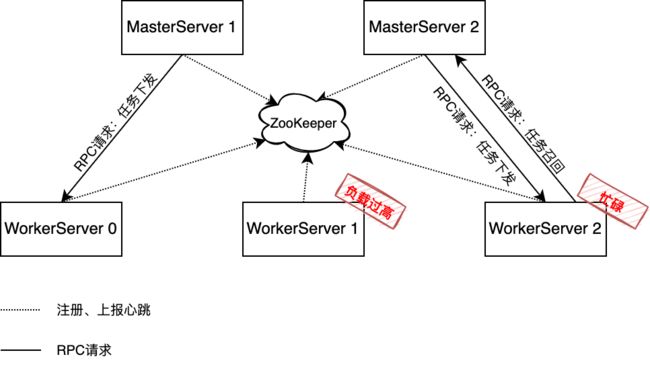
在 2.0.6 版本以前,当集群有多个 WorkerServer 节点时,比如3个 WorkerServer 节点,所对应的负载分别是 0.1, 0.2, 0.2,如果按照默认的负载均衡策略 LowerWeight 来分配任务,若一次启动100个任务,在启动任务的心跳周期内,可能导致任务会直接分配到负载为0.1的 WorkerServer 中,而其他两个 WorkerServer 分配不到任务,当 WorkerServer 的并发数是10个任务时,另外90个任务在同一个节点排队,这就拉长了任务整体运行的时间。基于此问题,2.0.6+ 版本增加了 MasterServer 的召回策略:
-
WorkerServer 的队列有:
-
等待分配队列:org.apache.dolphinscheduler.server.worker.runner.WorkerManagerThread#waitSubmitQueue,无边界的阻塞队列,负责接收来自MasterServer的DAG任务,此队列会延迟执行队列;
-
执行队列:org.apache.dolphinscheduler.server.worker.runner.WorkerExecService,线程池(大小默认100),可通过worker.exec-threads参数调整;
-
等待执行队列:同执行队列,其中未分配到空闲线程而阻塞的任务数,即为等待执行的任务数;
-
-
WorkerServer 会周期性更新 ZooKeeper 中的心跳信息,其中包括等待执行队列的大小,假如在一次心跳周期内启动了大量的任务(本次心跳周期内等待队列还未更新),WorkerServer 获取到任务时先放到等待分配队列,等待分配队列会将任务给执行队列,执行队列满时,会放到等待执行队列,当执行队列、等待执行队列都满时,等待分配队列则无法分配任务,就会触发 MasterServer 召回策略,WorkerServer 把任务返回给 MasterServer,MasterServer 会重新分配;
4.5、容错机制
4.5.1、脑裂问题
脑裂是指一个集群由于网络故障,被分为至少两个彼此无法通信的单独集群,此时如果两个集群各自工作,则可能会产生严重的数据冲突和错误。由于网络抖动,可能会使得MasterServer节点短时间内失去和ZooKeeper的心跳,从而发生znode临时节点的移除事件,触发脑裂问题(节点假死,但仍在分发工作流),对于这种场景,开发者通过监听器监听节点和ZooKeeper的连接情况,一旦断连则直接触发自杀逻辑:
public class MasterConnectionStateListener implements ConnectionListener {
...
@Override
public void onUpdate(ConnectionState state) {
switch (state) {
...
case DISCONNECTED:
logger.warn("registry connection state is {}, ready to stop myself", state);
registryClient.getStoppable().stop("registry connection state is DISCONNECTED, stop myself");
break;
default:
}
}
}4.5.2、宕机容错
依赖ZooKeeper的监听机制,MasterServer/WorkerServer各自在启动时会向ZooKeeper注册临时节点,并监听临时节点的remove事件,一旦节点被移除,则持久化告警信息,等待发送;
关键实现类方法:
-
MasterDataListener:监听ZK路径 /dolphinscheduler/nodes/master,若发生临时节点移除事件,则发送告警;
-
WorkerDataListener:监听ZK路径 /dolphinscheduler/nodes/worker/${WorkerGroup},若发生临时节点移除事件,则发送告警;
ZooKeeper注册路径:
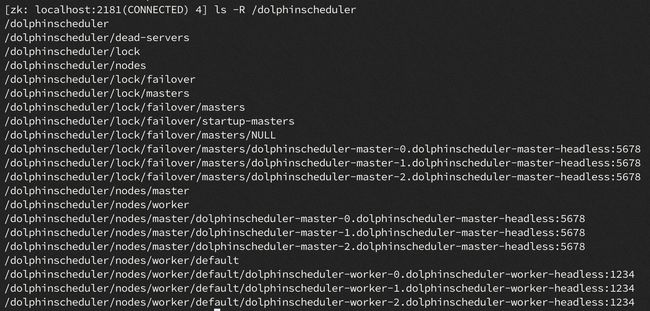
4.5.3、故障转移
故障转移发生在调度阶段,假如某个 MasterServer 节点在执行中途宕机或者假死,导致ZooKeeper上的znode被移除,则需要将原本由此节点代理的工作流任务,重新转移至其它存活状态的 MasterServer 节点上,否则会导致任务无法下发,或者 WorkerServer 执行完任务后无法向任务关联的 MasterServer 发送RPC请求;
org.apache.dolphinscheduler.server.master.runner.FailoverExecuteThread 线程随着 MasterServer 一起启动,负责周期性巡检元数据,筛选出分配到故障节点的工作流实例,向WorkerServer发送TaskKillRequestCommand请求杀死运行中的任务;向Command表写入RECOVER_TOLERANCE_FAULT_PROCESS记录,等待MasterServer消费;
感谢阅读!笔者水平有限,若有不当之处,请不吝指正!