TTS | 语音合成论文概述
综述系列
2021_A Survey on Neural Speech Synthesis
论文:2106.15561.pdf (arxiv.org)
论文从两个方面对神经语音合成领域的发展现状进行了梳理总结(逻辑框架如图1所示):
核心模块:分别从文本分析(textanalysis)、声学模型(acoustic model)、声码器(vocoder)、完全端到端模型(fully end-to-end model)等方面进行介绍。
进阶主题:分别从快速语音合成(fast TTS)、低资源语音合成(low-resourceTTS)、鲁棒语音合成(robust TTS)、富有表现力的语音合成(expressive TTS)、可适配语音合成(adaptive TTS)等方面进行介绍。
TTS 核心模块
研究员们根据神经语音合成系统的核心模块提出了一个分类体系。每个模块分别对应特定的数据转换流程:
1)文本分析模块将文本字符转换成音素或语言学特征;
2)声学模型将语言学特征、音素或字符序列转换成声学特征;
3)声码器将语言学特征或声学特征转换成语音波形;
4)完全端到端模型将字符或音素序列转换成语音波形。

2021_A Survey on Audio Synthesis and Audio-Visual Multimodal Processing(音频合成与视听多模态处理综述)
论文:2108.00443.pdf (arxiv.org)
SOTA
2022_NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
论文:2205.04421v2.pdf (arxiv.org)
TTS经典论文
2016_WAVENET: A GENERATIVE MODEL FOR RAW AUDIO
论文:1609.03499.pdf (arxiv.org)
【3,4】本文的四大特点如下:
WaveNet 直接生成自然的语音波形。
提出了一种可以学习和生成长语音波形的新结构。
训练的模型可以产生各种特征语音,因为状态建模。
它在各种语音生成(包括音乐)中也表现出色。
WaveNet模型结构
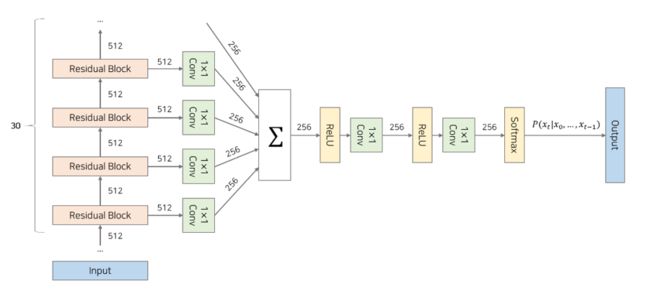
WaveNet 具有 30 个救援块的结构。 将整数数组作为输入,从第一个区域块到第 30 个区域性块依次进入。 从每个区域块生成的输出通过 Skip 连接合并,并将其用作模型的输出。
2018_NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS
论文:2108.00443.pdf (arxiv.org)
随着深度学习方法(如 WaveNet 和 Tacotron)的应用,TTS (TTS) 发展迅速。 因此,现在无需复杂的工作流程即可训练数据,从而从文本中生成高质量的语音【1,2】。
论文的三大特点如下:
基于 Attention 的 Seq-to-Seq提出了TTS模型结构。
<端到端模型>,只需对<语句、语音和对的数据即可进行训练,无需执行任何操作。
在语音合成质量测试 (MOS) 中得分较高。合成质量好。
2017.3_Deep Voice: Real-time Neural Text-to-Speech
论文:https://arxiv.org/abs/1702.07825
2017.5_Deep Voice 2: Multi-Speaker Neural Text-to-Speech
2018_DEEP VOICE 3: SCALING TEXT-TO-SPEECH WITH CONVOLUTIONAL SEQUENCELEARNING
论文:
参考文献
【1】[논문리뷰]Tacotron2 - 새내기 코드 여행 (joungheekim.github.io)
【2】[Speech Synthesis] Tacotron 논문 정리 (hcnoh.github.io)
【3】[논문리뷰]WaveNet - 새내기 코드 여행 (joungheekim.github.io)
【4】Understanding WaveNet architecture | by Satyam Kumar | Medium
References
[1] Sercan Ömer Arik, Mike Chrzanowski, Adam Coates, Gregory Frederick Diamos, Andrew Gibiansky, Yongguo Kang, Xian Li, John Miller, Andrew Y. Ng, Jonathan Raiman, Shubho Sengupta, Mohammad Shoeybi: Deep Voice: Real-time Neural Text-to-Speech. ICML 2017: 195-204
[2] Wei Ping, Kainan Peng, Andrew Gibiansky, Sercan O.Arık, Ajay Kannan, Sharan Naran: DEEP VOICE 3: 2000-SPEAKER NEURAL TEXT-TO-SPEECH. CoRR abs/1710.07654 (2017)
[3] Sercan Ömer Arik, Gregory F. Diamos, Andrew Gibiansky, John Miller, Kainan Peng, Wei Ping, Jonathan Raiman, Yanqi Zhou: Deep Voice 2: Multi-Speaker Neural Text-to-Speech. CoRR abs/1705.08947 (2017)
[4] Aäron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew W. Senior, Koray Kavukcuoglu: WaveNet: A Generative Model for Raw Audio. CoRR abs/1609.03499 (2016)
[5] Soroush Mehri, Kundan Kumar, Ishaan Gulrajani, Rithesh Kumar, Shubham Jain, Jose Sotelo, Aaron C. Courville, Yoshua Bengio: SampleRNN: An Unconditional End-to-End Neural Audio Generation Model. CoRR abs/1612.07837 (2016)
[6] Sotelo, J., Mehri, S., Kumar, K., Santos, J. F., Kastner, K., Courville, A., & Bengio, Y. (2017). Char2Wav: End-to-end speech synthesis.
[7] Yuxuan Wang, R. J. Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc V. Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous: Tacotron: A Fully End-to-End Text-To-Speech Synthesis Model. CoRR abs/1703.10135 (2017)
[8] Wang, W., Xu, S., & Xu, B. (2016). First Step Towards End-to-End Parametric TTS Synthesis: Generating Spectral Parameters with Neural Attention. INTERSPEECH.