itextpdf5.x实现合同签署盖章预览功能
文章目录
- 1.背景
- 2.E签宝产品接入使用
- 3.技术选型
-
- 3.1 iText
- 3.2 JFreeReport
- 3.3 PJX
- 3.3 Apache FOP
- 3.4 gnujpdf
- 3.5 PDF Box
- 3.6 Connla
- 3.7 PDF Split & Merge
- 3.8 PDF Clown for Java
- 3.9 iText toolbox
- 3.10 PDFjet
- 3.11 ICEpdf
- 3.12 JSignPdf
- 3.13 PDF Renderer
- 3.14 OFD Reader & Writer
- 3.15 图表简单对比
- 4.依赖
- 5.工具代码
- 6.业务接入
- 7.最终效果
- 8.总结
1.背景
由于之前做了一个xxx驾考的项目,里面有合同签字盖章的这样一个功能,接入的是E签宝的产品,项目之前是外包做的,技术和代码基本写的都很戳眼睛,后面接手过来,把里面的各种坑都填了,然后搞上线了,然后他们居然说E签宝太贵,差不多一份合同签署下来要2块多,不想用E签宝想用自己的,那个时候哪里有自己的东西,调试对接E签宝就花了我半个多月的时间,真的是费了九牛二虎之力,那一分钟心中真是有一万xxx奔腾,用付费的不好吗?就想着白嫖,用专业的不好嘛?吃力不讨好的玩意,没办法还是得硬着头皮的搞,于是乎我就上gitHub上面和网上找了些能实现这个功能的项目和代码去尝试,后面采用了这种曲线救国的方式实现了这个功能。
2.E签宝产品接入使用
先说说专业第三方公司的接入流程:就拿E签宝来说就是他们有会给他们的用户提供一个开放平台,你需要注册后台开发者账号,然后添加企业和法人,会给添加的企业生成各个种类的电子签章,给法人生成签名的电子章,这些章得生成还是一些电子签章权威机构生成的,配置一个生产和测试的应用,这个应用会有一个secretKey和appId还有就是调用白名单等配置,会给开发者提供他们平台的开发文档,去看接入流程和接口文档基本也是很简单的,大致流程如下:
1)开发接入的时候会给用户注册一个E签宝的账号和访问凭证用于给调用E签宝接口,这个E签宝的账号和token需要使用发自行接入和维护。
2)在后台没有配置一个模板的时候需要使用Adobe Acrobat DC自己制作一个pdf模板,然后把模本放在项目中,先上传模板文件,在代码中上传模板模板文件需要带名称+.pdf后缀不然上传的模板在E签宝那边是损坏打不开的,然后填充模板字段会生成一个临时文件,E签宝的文件存储用的也是OSS。
3)创建一个流程,然后添加文档,添加文档成功后,添加手动签署区域,添加平台自动盖章签署区域,然后启动这个流程,这些接口的调用返回信息根据自己业务的需要进行关键字段的保存入库。
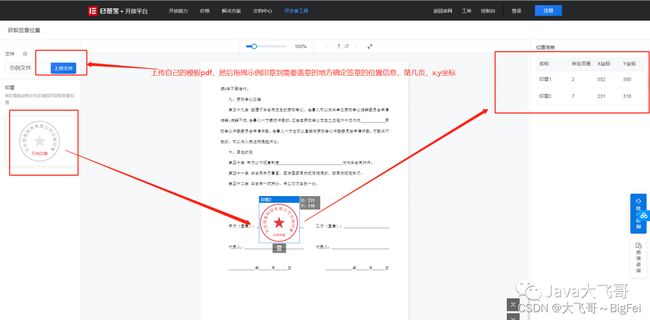
4)流程一旦开启就会收到E签宝的短信然后点击短信链接就跳到支付宝上的E签宝,然后用户点击签署,用户点击签署就会触发用户的签名和平台相应的盖章都会自动填写到签名合同中,然后完成签署流程,这个pdf合同文件就签署好了,在E签宝后台可以看到,在签署的这个流程中还会有一些权限的校验,比如用户注册E签宝账号的名字填错了,到用户收到短息打开支付宝中的E签宝进行签署的时候会提示支付宝E签宝账号和待签署人的名字不匹配,签署不了,此时需要调用E签宝的修改E签宝的账户信息的接口修改用户的名字,这个名字需要跟身份证上的一致才可以,这个也是一个很坑的问题,还有一个很肯的问题就是,添加手动签署区域,添加平台自动盖章签署区域,代码中指定的签署区域和盖章区域的位置,在第几页的(x,y)的坐标位置的确定,页数的确定不用说,就是这个坐标位置的确定,需要用到下面的这个E签宝的网页工具,上传pdf模板然后拖拽一个页面上的签章,右侧页面会显示当前拖拽的签章在当前也的页数和坐标位置,这个还是跟那边的开发对接才知道是这种确定的,不是用截图工具的测量的,不然签署的时候会报:签署区域超出文件范围的错误:
https://open.esign.cn/tools/seal-position
5)E签宝还有一个其它的接口可以使用代码封装一个方法调用或者直接使用PostMan调用,比如:修改E签宝账号信息、添加平台放自动盖章区签署区、查询签署区列表、签署流程撤销等,header都是如下方式,然后填写好url和body参数即可,具体如何搞的去看E签宝的开发文档,他们官网有对应的文档,可以去查看。

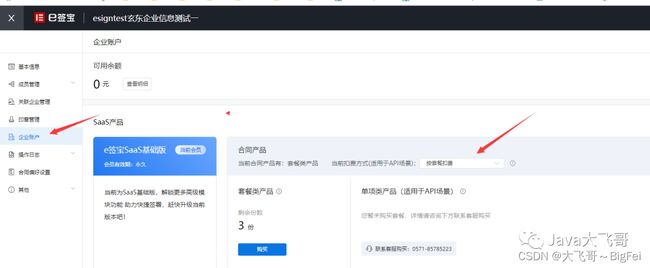
6)最重要的一点,了解了上面的流程后,需要对接他们的开发和商务,最好是拉一个微信群方便沟通,最最最重要的一点就是要购买他们的套餐生产的应用才可以使用,一般新注册的企业应用E签宝赠送2份合同的使用份数,使用完就没有了,就需要购买套餐的,不然会启动流程失败,提示:企业账户中电子合同份数不足,请联系管理员,如果你购买了套餐了,还报这个合同份数不足是后台套餐设置的问题,要设置成按套餐扣费不是按单项扣费:
7) 如果你在一个合同的模板中有一个用户签署(用户手写签字–这个是甲方)、乙方盖章(合作的第三个公司)和丙方盖章(公司属于丙方),这种在E签宝后台,一开始注册的公司是我方公司(丙方公司),所以你需要把乙方公司也在E签宝后台的企业管理里面添加进入,新添加企业需要公司法人的身份证正反面信息和公司的营业执照信息,只要是新添加的公司都会生成法人签署章和各种公司的电子章,新增企业是在控制台里面的签约平台里面的全部企业的按钮,所以这个时候就需要修改乙方公司的公司电子章的授权,然后进行如下操作就可以将乙方公司的合同章授权给我方公司使用,这个过程会有一个协议签署(签章授权协议),签署完成就可以在我方应用中既可以使用我方公司的章也可以使用其他公司的章。

最后,像E签宝之中产品也很多,根据自己的需求和实力去选择。
3.技术选型
3.1 iText
iText是一个能够快速产生PDF文件的java类库。iText的java类对于那些要产生包含文本,表格,图形的只读文档是很有用的。它的类库尤其与java Servlet有很好的给合。使用iText与PDF能够使你正确的控制Servlet的输出。
该项目主页:http://www.lowagie.com/iText/
3.2 JFreeReport
JFreeReport的数据继承自Swing组件的TableModel接口。JFreeReport生成的报表可以分页预览、打印或者保存为多种格式的文件包括pdf、Excel、html等。
该项目主页:http://www.jfree.org/jfreereport/
3.3 PJX
PJX支持读取,组合,处理,和生成PDF文档(注意:PJX需要 J2SE 1.4.0 或更高版本)。
该项目主页:http://www.etymon.com/epub.html
3.3 Apache FOP
FOP是由James Tauber发起的一个开源项目,原先的版本是利用xsl-fo将xml文件转换成pdf文件。但最新的版本它可以将xml文件转换成pdf,mif,pcl,txt等多种格式以及直接输出到打印机,并且支持使用SVG描述图形。
该项目主页:http://xml.apache.org/fop/
3.4 gnujpdf
gnujpdf是一个java类包(gnu.jpdf.*),它提供了一个简单的API来创建与打印PDF文件。遵循LGPL开源协议。
该项目主页:http://gnujpdf.sourceforge.net/
3.5 PDF Box
PDFBox是一个开源的可以操作PDF文档的Java PDF类库。它可以创建一个新PDF文档,操作现有PDF文档并提取文档中的内容。
它具有以下特性:
- 将一个PDF文档转换输出为一个文本文件。
- 可以从文本文件创建一个PDF文档。
- 加密/解密PDF文档。
- 向已有PDF文档中追加内容。
- 可以从PDF文档生成一张图片。
- 可以与Jakarta Lucene搜索引擎的整合。
该项目主页:http://www.pdfbox.org/
3.6 Connla
Connla是一个Java包用于创建可导成TXT,CSV,HTML,XHTML,XML,PDF和XLS等格式的数据集。
该项目主页:http://connla.sourceforge.net/
3.7 PDF Split & Merge
PDF Split&Merge是一款实用基于GPL许可协议发布的PDF文件分割与合并工具。您可以指定页码范围将一个PDF文件分割为若干PDF 文件(支持单页和多页混合),或将多个PDF文件按指定顺序合并成一个PDF文件。其转换速度非常快。它采用Java Swing开发,运用到的第三方组件包括:iText,jcmdline和JGoodies界面包。
该项目主页:http://pdfsam.sourceforge.net/
3.8 PDF Clown for Java
PDF Clown for Java是一个基于Java1.5用于读,写和操作PDF文档的Java类包。它提供多个抽象层来满足不同的编程风格:从底层(PDF对象模型)到高级(PDF文档结构和内容流)。
该项目主页:http://www.stefanochizzolini.it/en/projects/clown/
3.9 iText toolbox
iText toolbox是一个Java Swing应用程序,其起初是iText类库的一部分。iText toolbox既可以作为一个可执行的Jar,也可作为Java Webstart应用程序运行。对于完成各种类型的PDF相关文件操作,iText toolbox是一个非常有用的工具比如:把一个目录下的所有图片转换成一个PDF文档,合并现有PDF文档等。此外开发人员可以把它当成一个学习iText类库各项功能的工具。
该项目主页:http://itexttoolbox.sourceforge.net/
3.10 PDFjet
PDFjet是一个用于动态生成PDF文档的Java类库。支持绘制点、线、方框、圆、贝塞尔曲线(Bezier Curves) 、多边形、星形、复杂路径和形状。支持unicode,文本间距调整,嵌入超链接等。
该项目主页:http://pdfjet.com/os/edition.html
3.11 ICEpdf
ICEpdf是一个开源Java PDF引擎,用于展示/查看PDF文档,转换和抽取PDF文档的内容。可以集成到Java桌面应用程序或Web服务器中使用。
该项目主页:http://www.icepdf.org/
3.12 JSignPdf
JSignPdf是一个用于为PDF文档添加数字签名的Java应用程序。它既可以单独使用,也可以作为OpenOffice.org的插件使用。支持设置验证级别,PDF加密和设置权限,添加签名图标,批量转换(通过命令行参数控制)。
该项目主页:http://jsignpdf.sourceforge.net/
3.13 PDF Renderer
PDF Renderer是一个采用纯Java实现的PDF阅读器和渲染器。 可以利用它实现在你的应用中查看PDF文件;在导出PDF文件之前进行预览;在服务器端Web应用中将PDF转成PNGs图片;在一个3D场景中查看PDF。
该项目主页:https://pdf-renderer.dev.java.net/
3.14 OFD Reader & Writer
FD Reader & Writer 开源的OFD处理库,支持文档生成、数字签名、文档保护、文档合并、转换等功能。本项目采用Apache 2.0许可,请尊重开源项目作者,在软件中附带OFDRW开源软件许可。根据《GB/T 33190-2016 电子文件存储与交换格式版式文档》标准实现版式文档OFD库(含有书签)。
该项目主页:
https://gitee.com/ofdrw/ofdrw#https://gitee.com/link?target=https%3A%2F%2Fgithub.com%2Froy19831015%2FOfdiumEx
3.15 图表简单对比
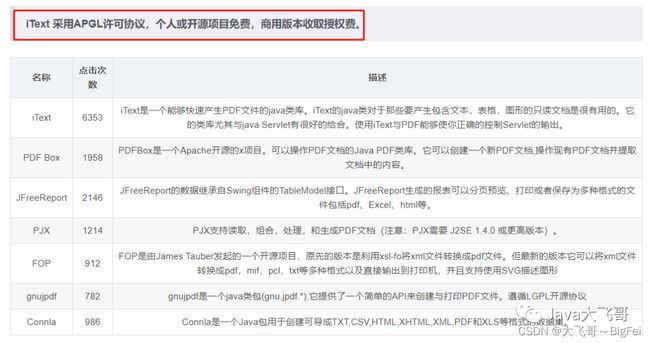
最终选择iText5.x,说明:上面的项目地址有访问不到的请自行百度查找,也可以探索其它的一些开源实现。
4.依赖
<dependency>
<groupId>com.itextpdfgroupId>
<artifactId>itextpdfartifactId>
<version>5.5.10version>
dependency>
<dependency>
<groupId>com.itextpdfgroupId>
<artifactId>itext-asianartifactId>
<version>5.2.0version>
dependency>
<dependency>
<groupId>com.aliyun.ossgroupId>
<artifactId>aliyun-sdk-ossartifactId>
<version>3.11.0version>
dependency>
5.工具代码
ItextPDFUtil:pdf填充字段、签字盖章,签字盖章可以根据关键字定位到需要签字盖章的那一页pdf关键字的坐标位置,然后把签字和盖章的图片插入到指定的位置即可。
package com.xxxx.xxxxx.tool;
import com.itextpdf.awt.geom.Rectangle2D;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.Image;
import com.itextpdf.text.pdf.*;
import com.itextpdf.text.pdf.parser.*;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.io.IOUtils;
import org.apache.commons.lang3.exception.ExceptionUtils;
import java.io.*;
import java.rmi.RemoteException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
/**
* pdf操作工具类
*
* @author zlf
*/
@Slf4j
public class ItextPDFUtil {
public static final float defaultHeight = 16;
public static final float fixHeight = 10;
/**
* @param templatePdfIn 模板pdf读入的IO流
* @param generatePdfPath 生成pdf路径
* @param data 数据
*/
public static String generatePDF(InputStream templatePdfIn, String generatePdfPath, Map<String, String> data) {
OutputStream fos = null;
ByteArrayOutputStream bos = null;
try {
PdfReader reader = new PdfReader(templatePdfIn);
bos = new ByteArrayOutputStream();
/* 将要生成的目标PDF文件名称 */
PdfStamper ps = new PdfStamper(reader, bos);
/* 使用中文字体 */
BaseFont bf = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);
ArrayList<BaseFont> fontList = new ArrayList<BaseFont>();
fontList.add(bf);
/* 取出报表模板中的所有字段 */
AcroFields fields = ps.getAcroFields();
fields.setSubstitutionFonts(fontList);
fillData(fields, data);
/* 必须要调用这个,否则文档不会生成的 如果为false那么生成的PDF文件还能编辑,一定要设为true*/
ps.setFormFlattening(true);
ps.close();
fos = new FileOutputStream(generatePdfPath);
fos.write(bos.toByteArray());
fos.flush();
return generatePdfPath;
} catch (Exception e) {
e.printStackTrace();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bos != null) {
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (templatePdfIn != null) {
try {
templatePdfIn.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return null;
}
/**
* @param fields
* @param data
* @throws IOException
* @throws DocumentException
*/
private static void fillData(AcroFields fields, Map<String, String> data) throws IOException, DocumentException {
List<String> keys = new ArrayList<String>();
Map<String, AcroFields.Item> formFields = fields.getFields();
for (String key : data.keySet()) {
if (formFields.containsKey(key)) {
String value = data.get(key);
fields.setField(key, value); // 为字段赋值,注意字段名称是区分大小写的
keys.add(key);
}
}
Iterator<String> itemsKey = formFields.keySet().iterator();
while (itemsKey.hasNext()) {
String itemKey = itemsKey.next();
if (!keys.contains(itemKey)) {
fields.setField(itemKey, " ");
}
}
}
public static void pdfSignSeal(String inputFilePath, String outFilePath, InputStream imgeFileIo, String keyword) {
log.info("pdfSignSeal.params:inputFilePath:{},outFilePath:{},imgFilePath:{},keyword:{}", inputFilePath, outFilePath, imgeFileIo, keyword);
FileOutputStream fileOutputStream = null;
try {
//查找位置
float[] position = ItextPDFUtil.getAddImagePositionXY(inputFilePath, keyword);
//Read file using PdfReader
PdfReader pdfReader = new PdfReader(inputFilePath);
log.info("pdfSignSeal===>x:" + position[1] + " y:" + position[2]);
//Modify file using PdfReader
fileOutputStream = new FileOutputStream(outFilePath);
PdfStamper pdfStamper = new PdfStamper(pdfReader, fileOutputStream);
byte[] imageData = IOUtils.toByteArray(imgeFileIo);
Image image = Image.getInstance(imageData);
//Fixed Positioning
//image.scaleToFit(100, 50);
image.scaleAbsolute(100, 80);
//Scale to new height and new width of image
image.setAbsolutePosition(position[1], position[2]);
log.info("pages:" + pdfReader.getNumberOfPages());
// pdfStamper.getUnderContent 让图片位于内容的底层
//pdfStamper.getOverContent 让图片位于内容的顶层
PdfContentByte content = pdfStamper.getOverContent((int) position[0]);
content.addImage(image);
pdfStamper.close();
pdfReader.close();
} catch (Exception ex) {
ex.getStackTrace();
log.error("pdf签名盖章异常:{}", ExceptionUtils.getMessage(ex));
} finally {
if (fileOutputStream != null) {
try {
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* @description: 查找插入签名图片的最终位置,因为是插入签名图片,所以之前的关键字应只会出现一次
* 这里直接使用了第一次查找到关键字的位置,并返回该关键字之后的坐标位置
* @return: float[0]:页码,float[1]:最后一个字的x坐标,float[2]:最后一个字的y坐标
*/
public static float[] getAddImagePositionXY(String inputFilePath, String keyword) throws IOException {
float[] temp = new float[3];
List<float[]> positions = findKeywordPostions(inputFilePath, keyword);
if (positions.size() == 0) {
throw new RemoteException("没有找到关键字位置坐标!");
}
temp[0] = positions.get(0)[0];
temp[1] = positions.get(0)[1] + positions.get(0)[3] + 20;
temp[2] = positions.get(0)[2] - (positions.get(0)[3] / 2) - 10;
return temp;
}
/**
* findKeywordPostions
* 返回查找到关键字的首个文字的左上角坐标值
*
* @param pdfName
* @param keyword
* @return List : float[0]:pageNum float[1]:x float[2]:y
* @throws IOException
*/
public static List<float[]> findKeywordPostions(String pdfName, String keyword) throws IOException {
File pdfFile = new File(pdfName);
byte[] pdfData = new byte[(int) pdfFile.length()];
FileInputStream inputStream = new FileInputStream(pdfFile);
//byte[] pdfData = IOUtils.toByteArray(inputFileIo);
//从输入流中读取pdfData.length个字节到字节数组中,返回读入缓冲区的总字节数,若到达文件末尾,则返回-1
inputStream.read(pdfData);
inputStream.close();
List<float[]> result = new ArrayList<>();
List<PdfPageContentPositions> pdfPageContentPositions = getPdfContentPostionsList(pdfData);
for (PdfPageContentPositions pdfPageContentPosition : pdfPageContentPositions) {
List<float[]> charPositions = findPositions(keyword, pdfPageContentPosition);
if (charPositions == null || charPositions.size() < 1) {
continue;
}
result.addAll(charPositions);
}
return result;
}
/**
* findKeywordPostions
*
* @param pdfData 通过IO流 PDF文件转化的byte数组
* @param keyword 关键字
* @return List : float[0]:pageNum float[1]:x float[2]:y
* @throws IOException
*/
public static List<float[]> findKeywordPostions(byte[] pdfData, String keyword) throws IOException {
List<float[]> result = new ArrayList<float[]>();
List<PdfPageContentPositions> pdfPageContentPositions = getPdfContentPostionsList(pdfData);
for (PdfPageContentPositions pdfPageContentPosition : pdfPageContentPositions) {
List<float[]> charPositions = findPositions(keyword, pdfPageContentPosition);
if (charPositions == null || charPositions.size() < 1) {
continue;
}
result.addAll(charPositions);
}
return result;
}
private static List<PdfPageContentPositions> getPdfContentPostionsList(byte[] pdfData) throws IOException {
PdfReader reader = new PdfReader(pdfData);
List<PdfPageContentPositions> result = new ArrayList<PdfPageContentPositions>();
int pages = reader.getNumberOfPages();
for (int pageNum = 1; pageNum <= pages; pageNum++) {
float width = reader.getPageSize(pageNum).getWidth();
float height = reader.getPageSize(pageNum).getHeight();
PdfRenderListener pdfRenderListener = new PdfRenderListener(pageNum, width, height);
//解析pdf,定位位置
PdfContentStreamProcessor processor = new PdfContentStreamProcessor(pdfRenderListener);
PdfDictionary pageDic = reader.getPageN(pageNum);
PdfDictionary resourcesDic = pageDic.getAsDict(PdfName.RESOURCES);
try {
processor.processContent(ContentByteUtils.getContentBytesForPage(reader, pageNum), resourcesDic);
} catch (IOException e) {
reader.close();
throw e;
}
String content = pdfRenderListener.getContent();
List<CharPosition> charPositions = pdfRenderListener.getcharPositions();
List<float[]> positionsList = new ArrayList<float[]>();
for (CharPosition charPosition : charPositions) {
float[] positions = new float[]{charPosition.getPageNum(), charPosition.getX(), charPosition.getY(), charPosition.getWidth(), charPosition.getHeight()};
positionsList.add(positions);
}
PdfPageContentPositions pdfPageContentPositions = new PdfPageContentPositions();
pdfPageContentPositions.setContent(content);
pdfPageContentPositions.setPostions(positionsList);
result.add(pdfPageContentPositions);
}
reader.close();
return result;
}
private static List<float[]> findPositions(String keyword, PdfPageContentPositions pdfPageContentPositions) {
List<float[]> result = new ArrayList<float[]>();
String content = pdfPageContentPositions.getContent();
List<float[]> charPositions = pdfPageContentPositions.getPositions();
for (int pos = 0; pos < content.length(); ) {
int positionIndex = content.indexOf(keyword, pos);
if (positionIndex == -1) {
break;
}
float[] postions = charPositions.get(positionIndex);
//此处较为关键通过第一个关键字计算出整个关键字的宽度
for (int i = 1; i < keyword.length(); i++) {
float[] postionsNew = charPositions.get(positionIndex + i);
postions[3] = postions[3] + postionsNew[3];
}
result.add(postions);
pos = positionIndex + 1;
}
return result;
}
private static class PdfPageContentPositions {
private String content;
private List<float[]> positions;
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public List<float[]> getPositions() {
return positions;
}
public void setPostions(List<float[]> positions) {
this.positions = positions;
}
}
private static class PdfRenderListener implements RenderListener {
private int pageNum;
private float pageWidth;
private float pageHeight;
private StringBuilder contentBuilder = new StringBuilder();
private List<CharPosition> charPositions = new ArrayList<CharPosition>();
public PdfRenderListener(int pageNum, float pageWidth, float pageHeight) {
this.pageNum = pageNum;
this.pageWidth = pageWidth;
this.pageHeight = pageHeight;
}
public void beginTextBlock() {
}
public void renderText(TextRenderInfo renderInfo) {
List<TextRenderInfo> characterRenderInfos = renderInfo.getCharacterRenderInfos();
for (TextRenderInfo textRenderInfo : characterRenderInfos) {
String word = textRenderInfo.getText();
if (word.length() > 1) {
word = word.substring(word.length() - 1, word.length());
}
Rectangle2D.Float rectangle = textRenderInfo.getAscentLine().getBoundingRectange();
float x = (float) rectangle.getX();
float y = (float) rectangle.getY();
// float x = (float)rectangle.getCenterX();
// float y = (float)rectangle.getCenterY();
// double x = rectangle.getMinX();
// double y = rectangle.getMaxY();
//这两个是关键字在所在页面的XY轴的百分比
float xPercent = Math.round(x / pageWidth * 10000) / 10000f;
float yPercent = Math.round((1 - y / pageHeight) * 10000) / 10000f; //
//CharPosition charPosition = new CharPosition(pageNum, xPercent, yPercent);
CharPosition charPosition = new CharPosition(pageNum, x, y - fixHeight, (float) rectangle.getWidth(), (float) (rectangle.getHeight() == 0 ? defaultHeight : rectangle.getHeight()));
charPositions.add(charPosition);
contentBuilder.append(word);
}
}
public void endTextBlock() {
}
public void renderImage(ImageRenderInfo renderInfo) {
}
public String getContent() {
return contentBuilder.toString();
}
public List<CharPosition> getcharPositions() {
return charPositions;
}
}
private static class CharPosition {
private int pageNum = 0;
private float x = 0;
private float y = 0;
private float width;
private float height;
public CharPosition(int pageNum, float x, float y, float width, float height) {
this.pageNum = pageNum;
this.x = x;
this.y = y;
this.width = width;
this.height = height;
}
public int getPageNum() {
return pageNum;
}
public float getX() {
return x;
}
public float getY() {
return y;
}
public float getWidth() {
return width;
}
public float getHeight() {
return height;
}
@Override
public String toString() {
return "CharPosition{" +
"pageNum=" + pageNum +
", x=" + x +
", y=" + y +
", width=" + width +
", height=" + height +
'}';
}
}
}
ColumnUtil:获取类的字段名字工具类
package com.xxxx.common.tool;
import java.io.Serializable;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import java.lang.invoke.SerializedLambda;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.util.function.Function;
/**
* Java8通过Function函数获取字段名称(获取实体类的字段名称)
*
* @Author: zlf
* @Date: 2023/3/3
*/
public class ColumnUtil {
/**
* 使Function获取序列化能力
*/
@FunctionalInterface
public interface SFunction<T, R> extends Function<T, R>, Serializable {
}
/**
* 字段名注解,声明表字段
*/
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface TableField {
String value() default "";
}
//默认配置
static String defaultSplit = "";
static Integer defaultToType = 0;
/**
* 获取实体类的字段名称(实体声明的字段名称)
*/
public static <T> String getFieldName(SFunction<T, ?> fn) {
return getFieldName(fn, defaultSplit);
}
/**
* 获取实体类的字段名称
*
* @param split 分隔符,多个字母自定义分隔符
*/
public static <T> String getFieldName(SFunction<T, ?> fn, String split) {
return getFieldName(fn, split, defaultToType);
}
/**
* 获取实体类的字段名称
*
* @param split 分隔符,多个字母自定义分隔符
* @param toType 转换方式,多个字母以大小写方式返回 0.不做转换 1.大写 2.小写
*/
public static <T> String getFieldName(SFunction<T, ?> fn, String split, Integer toType) {
SerializedLambda serializedLambda = getSerializedLambda(fn);
// 从lambda信息取出method、field、class等
String fieldName = serializedLambda.getImplMethodName().substring("get".length());
fieldName = fieldName.replaceFirst(fieldName.charAt(0) + "", (fieldName.charAt(0) + "").toLowerCase());
Field field;
try {
field = Class.forName(serializedLambda.getImplClass().replace("/", ".")).getDeclaredField(fieldName);
} catch (ClassNotFoundException | NoSuchFieldException e) {
throw new RuntimeException(e);
}
// 从field取出字段名,可以根据实际情况调整
TableField tableField = field.getAnnotation(TableField.class);
if (tableField != null && tableField.value().length() > 0) {
return tableField.value();
} else {
//0.不做转换 1.大写 2.小写
switch (toType) {
case 1:
return fieldName.replaceAll("[A-Z]", split + "$0").toUpperCase();
case 2:
return fieldName.replaceAll("[A-Z]", split + "$0").toLowerCase();
default:
return fieldName.replaceAll("[A-Z]", split + "$0");
}
}
}
private static <T> SerializedLambda getSerializedLambda(SFunction<T, ?> fn) {
// 从function取出序列化方法
Method writeReplaceMethod;
try {
writeReplaceMethod = fn.getClass().getDeclaredMethod("writeReplace");
} catch (NoSuchMethodException e) {
throw new RuntimeException(e);
}
// 从序列化方法取出序列化的lambda信息
boolean isAccessible = writeReplaceMethod.isAccessible();
writeReplaceMethod.setAccessible(true);
SerializedLambda serializedLambda;
try {
serializedLambda = (SerializedLambda) writeReplaceMethod.invoke(fn);
} catch (IllegalAccessException | InvocationTargetException e) {
throw new RuntimeException(e);
}
writeReplaceMethod.setAccessible(isAccessible);
return serializedLambda;
}
}
OssConfig:阿里OSS的配置类
package com.xxx.xxxx.xxxx.conifg;
import lombok.Data;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.context.config.annotation.RefreshScope;
import org.springframework.stereotype.Component;
/**
* @author: zlf
* @date: 2022/02/18
* @description: oos参数维护在nacos配置文件中
* @modified:
* @version: 1.0
*/
@Component
@Data
@RefreshScope
public class OssConfig {
@Value("${oos.endpoint}")
private String endpoint;
@Value("${oos.accessKeyId}")
private String accessKeyId;
@Value("${oos.accessKeySecret}")
private String accessKeySecret;
@Value("${oos.bucketName}")
private String bucketName;
}
OssUploadDTO:OSS上传返回信息类
@Data
public class OssUploadDTO implements Serializable {
private String url;
private String bucketName;
private String endpoint;
private String objectName;
}
AliyunOosUtil:阿里OSS上传,小文件上传、大文件断点续传、获取临时文件访问地址,小文件和大文件上传可以根据文件大小组合使用
package com.xxx.xxx.web.utils;
import com.alibaba.fastjson.JSON;
import com.aliyun.oss.OSS;
import com.aliyun.oss.OSSClientBuilder;
import com.aliyun.oss.model.*;
import com.xxx.xxx.OssUploadDTO;
import com.xxx.financial.web.conifg.OssConfig;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.io.FileUtils;
import org.springframework.util.StopWatch;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
/**
* @author: zlf
* @date: 2022/02/18
* @description: 阿里云oos工具类
* @modified:
* @version: 1.0
*/
@Slf4j
public class AliyunOosUtil {
private OSS ossClient;
private OssConfig ossConfig;
public AliyunOosUtil() {
ossConfig = (OssConfig) SpringUtils.getBean("ossConfig");
ossClient = new OSSClientBuilder().build(ossConfig.getEndpoint(), ossConfig.getAccessKeyId(), ossConfig.getAccessKeySecret());
}
/**
* 小文件 上传文件到oss
* name = xxx.xx
* fileDir = xxxx/xxx
* dto = util.uploadFile2OSSResult(inputStream, name, fileDir + "/", "dyyy-financial");
*
* @param instream 文件上传流
* @param fileName 文件名
* @param filedir 上传相对路径
* @param bucketName 上传bucket
* @return
*/
public OssUploadDTO smallFileUpload(InputStream instream, String fileName, String filedir, String bucketName) {
StopWatch stopWatch = new StopWatch();
// 开始时间
stopWatch.start();
OssUploadDTO result = new OssUploadDTO();
// 判断bucket是否已经存在,不存在进行创建
if (!doesBucketExist(bucketName)) {
createBucket(bucketName);
}
try {
String objectName = filedir + fileName;
//上传文件
ossClient.putObject(bucketName, objectName, instream);
// 封装 url 路径
result.setUrl("http://" + bucketName + "." + ossConfig.getEndpoint() + "/" + objectName);
result.setBucketName(bucketName);
result.setEndpoint(ossConfig.getEndpoint());
result.setObjectName(objectName);
} catch (Exception e) {
log.error(e.getMessage(), e);
} finally {
try {
if (instream != null) {
instream.close();
}
if (null != ossClient) {
// 关闭OSSClient。
ossClient.shutdown();
}
} catch (IOException e) {
e.printStackTrace();
}
}
// 结束时间
stopWatch.stop();
log.info("smallFileUpload()返回:{}", JSON.toJSONString(result));
log.info("smallFileUpload()执行时长:{}秒", stopWatch.getTotalTimeSeconds());
return result;
}
/**
* 判断Bucket是否存在
*
* @return 存在返回true
*/
public boolean doesBucketExist(String bucketName) {
return ossClient.doesBucketExist(bucketName);
}
/**
* 创建Bucket
*/
public void createBucket(String bucketName) {
CreateBucketRequest createBucketRequest = new CreateBucketRequest(bucketName);
// 设置bucket权限为公共读,默认是私有读写
createBucketRequest.setCannedACL(CannedAccessControlList.PublicRead);
// 设置bucket存储类型为低频访问类型,默认是标准类型
createBucketRequest.setStorageClass(StorageClass.IA);
boolean exists = ossClient.doesBucketExist(bucketName);
if (!exists) {
try {
ossClient.createBucket(createBucketRequest);
} catch (Exception e) {
log.error(e.getMessage());
}
}
}
/**
* 大文件分片上传OSS
* name = xxx.xx
* fileDir = xxxx/xxx
* dto = util.bigFileMultipartUpload(inputStream, name, fileDir + "/", "dyyy-financial");
*
* @param is
* @param fileName
* @param filedir
* @param bucketName
* @return
*/
public OssUploadDTO bigFileMultipartUpload(InputStream is, String fileName, String filedir, String bucketName) {
StopWatch stopWatch = new StopWatch();
// 开始时间
stopWatch.start();
OssUploadDTO result = new OssUploadDTO();
String objectName = filedir + fileName;
String osType = System.getProperty("os.name");
String tmPath = "";
if (osType.toLowerCase().startsWith("win")) {
log.info("系统是windows系统!");
tmPath = "D:\\bigDir";
} else {
log.info("系统是Linux系统!");
tmPath = File.separator + "bigDir";
}
File dirs = new File(tmPath);
if (!dirs.exists()) {
dirs.mkdirs();
log.info("临时文件夹成功!");
}
File file = new File(tmPath + File.separator + fileName);
if (file.exists()) {
try {
FileUtils.forceDeleteOnExit(file);
file.createNewFile();
} catch (Exception e) {
e.printStackTrace();
log.error("删除临时文件1出错!");
}
log.info("删除已经存在的文件后,重新创建文件成功!");
}
log.info("临时文件路径:{}", file.getAbsolutePath());
try {
FileUtils.copyToFile(is, file);
} catch (IOException e) {
e.printStackTrace();
log.error("拷贝临时文件出错");
}
// 判断bucket是否已经存在,不存在进行创建
if (!doesBucketExist(bucketName)) {
createBucket(bucketName);
}
InitiateMultipartUploadRequest request = new InitiateMultipartUploadRequest(bucketName, objectName);
// 初始化分片。
InitiateMultipartUploadResult upresult = ossClient.initiateMultipartUpload(request);
// 返回uploadId,它是分片上传事件的唯一标识,您可以根据这个uploadId发起相关的操作,如取消分片上传、查询分片上传等。
String uploadId = upresult.getUploadId();
// partETags是PartETag的集合。PartETag由分片的ETag和分片号组成。
List<PartETag> partETags = new ArrayList<PartETag>();
// 计算文件有多少个分片。
// 100MB
final long partSize = 100 * 1024 * 1024L;
// 我这里读取的是本地的一个文件
long fileLength = file.length();
int partCount = (int) (fileLength / partSize);
if (fileLength % partSize != 0) {
partCount++;
}
// 遍历分片上传。
for (int i = 0; i < partCount; i++) {
long startPos = i * partSize;
long curPartSize = (i + 1 == partCount) ? (fileLength - startPos) : partSize;
InputStream instream = null;
try {
instream = new FileInputStream(file);
// 跳过已经上传的分片。
instream.skip(startPos);
} catch (Exception e) {
log.error("=========bigFileMultipartUpload读取文件流或skip出错==========");
e.printStackTrace();
}
UploadPartRequest uploadPartRequest = new UploadPartRequest();
uploadPartRequest.setBucketName(bucketName);
uploadPartRequest.setKey(objectName);
uploadPartRequest.setUploadId(uploadId);
uploadPartRequest.setInputStream(instream);
// 设置分片大小。除了最后一个分片没有大小限制,其他的分片最小为100KB。
uploadPartRequest.setPartSize(curPartSize);
// 设置分片号。每一个上传的分片都有一个分片号,取值范围是1~10000,如果超出这个范围,OSS将返回InvalidArgument的错误码。
uploadPartRequest.setPartNumber(i + 1);
// 每个分片不需要按顺序上传,甚至可以在不同客户端上传,OSS会按照分片号排序组成完整的文件。
UploadPartResult uploadPartResult = ossClient.uploadPart(uploadPartRequest);
// 每次上传分片之后,OSS的返回结果包含PartETag。PartETag将被保存在partETags中。
partETags.add(uploadPartResult.getPartETag());
}
// 创建CompleteMultipartUploadRequest对象。
// 在执行完成分片上传操作时,需要提供所有有效的partETags。OSS收到提交的partETags后,会逐一验证每个分片的有效性。当所有的数据分片验证通过后,OSS将把这些分片组合成一个完整的文件。
CompleteMultipartUploadRequest completeMultipartUploadRequest = new CompleteMultipartUploadRequest(bucketName, objectName, uploadId, partETags);
// 如果需要在完成文件上传的同时设置文件访问权限,请参考以下示例代码。
// completeMultipartUploadRequest.setObjectACL(CannedAccessControlList.PublicRead);
CompleteMultipartUploadResult completeMultipartUploadResult = ossClient.completeMultipartUpload(completeMultipartUploadRequest);
// 封装 url 路径
result.setUrl("http://" + bucketName + "." + ossConfig.getEndpoint() + "/" + objectName);
result.setBucketName(bucketName);
result.setEndpoint(ossConfig.getEndpoint());
result.setObjectName(objectName);
if (null != ossClient) {
// 关闭OSSClient。
ossClient.shutdown();
}
if (null != file) {
try {
FileUtils.forceDeleteOnExit(file);
file.createNewFile();
} catch (Exception e) {
e.printStackTrace();
log.error("删除临时文件2出错!");
}
}
// 结束时间
stopWatch.stop();
log.info("bigFileMultipartUpload()返回:{}", JSON.toJSONString(result));
log.info("bigFileMultipartUpload()执行时长:{}秒", stopWatch.getTotalTimeSeconds());
return result;
}
/**
* @param bucketName bucket
* @param objectName OSS上保存文件buckke后面的相对路径URI,包含文件名
* @param expire 过期时间秒 s
* @description: 生成临时oss访问URL
* @return: String 临时访问URL
*/
public String generatePresignedUrl(String bucketName, String objectName, long expire) {
// 设置URL默认过期时间为1小时。
Date expiration = new Date(System.currentTimeMillis() + (expire > 0 ? expire : 3600) * 1000);
// 生成以GET方法访问的签名URL,访客可以直接通过浏览器访问相关内容。
URL url = ossClient.generatePresignedUrl(bucketName, objectName, expiration);
return url.toString();
}
/**
* 解析oss的url获取一个临时的访问路劲
*
* @param ossPrivateUrl
* @return
*/
public static String getTemporaryUrl(String ossPrivateUrl) {
String[] sp1 = ossPrivateUrl.split("//");
String s1_1 = sp1[1];
String[] s1_2 = s1_1.split("\\.");
String s1_3 = s1_2[0];
String bucketName = s1_3;
log.info("bucketName:{}", bucketName);
String s1 = sp1[1];
String s2 = s1.substring(s1.indexOf("/") + 1);
String objectName = s2;
log.info("objectName:{}", objectName);
AliyunOosUtil aliyunOosUtil = new AliyunOosUtil();
String url = aliyunOosUtil.generatePresignedUrl(bucketName, objectName, -1);
return url;
}
}
6.业务接入
业务场景:比如在用户报名支付完成后前端可以引导用户去签署合同这样一个操作,用户支付完后端就生成了一条合同签署的记录,用户id和合同code状态为待签署,等用户点击签署,前端使用一些前端开源的签名组件,如下:
https://avuejs.com/default/sign/#&gid=1&pid=1

生成一张手写的签名图片,然后根据用户id和合同code传入后端,后端根据合同code和用户id查询填充信息组装数据,然后调用ItextPDFUtil的填充方法,做项目中配置好模板文件然后加载到项目中使用,之后调用ItextPDFUtil的签名盖章方法,大致代码步骤如下:
//1.参数校验、前置条件判断
//2.查询组装合同填充参数的业务数据
//3.从项目的Resource路径下加载模板文件
//4.创建文件路径和pdf1文件,填充模板字段,生成临时pdf1文件
//5.创建pdf2,用pdf1跟传入的手写签名图片调用签字接口,传入关键字1,生成pdf2
//6.创建pdf3,用pdf2和加载项目中我方公司的章在调用签字盖章接口,传入关键字2,生成pdf3
//7.创建pdf4,用pdf3和加载项目中乙方公司的章在调用签字盖章接口,传入关键字3,生成pdf4
//8.用pdf4上传OSS,返回oss访问地址
//9.报存oss预览地址,更改合同状态为已签署
//10.清理以上几步生产的pdf文件,pdf的名称都是用code结尾,每次生成的文件名为code,然后code加一个一,code1.pdf,code2.pdf,code3.pdf,code4.pdf,In和Out的流必须要关闭,不然生成的临时pdf文件被jvm占用无法删除
//11.前端可以使用开源预览组件预览OSS上的合同文件了
//三个关键字就是模板中的签字和盖章前面的文字:
//关键字1:甲方(签名):
//关键字2:乙方(盖章):
//关键字3:丙方(盖章):
本案例中使用的手写签名图片和公司章的图片大小和像素如下,如果大小太大最终插入pdf中的图片就会很大:

本案例中给用户和公司生成证书,用java生产的证书不具有权威性,赶脚没有啥卵用,还得维护一堆用户和关联公司的签章证书,所以采用在需要签名和盖章的地方直接插入手写签名图片和公司印章图片,这种就可以实现这个功能,如果你想生成证书也是可以的,请参看如下的项目链接:
https://github.com/xfreng/fui-itext
本案例使用Adobe Acrobat DC制作pdf模板文件,软件下载链接如下:
adobe安装
https://www.aliyundrive.com/s/4ccJfmuZv8V
点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视频原画倍速播放。

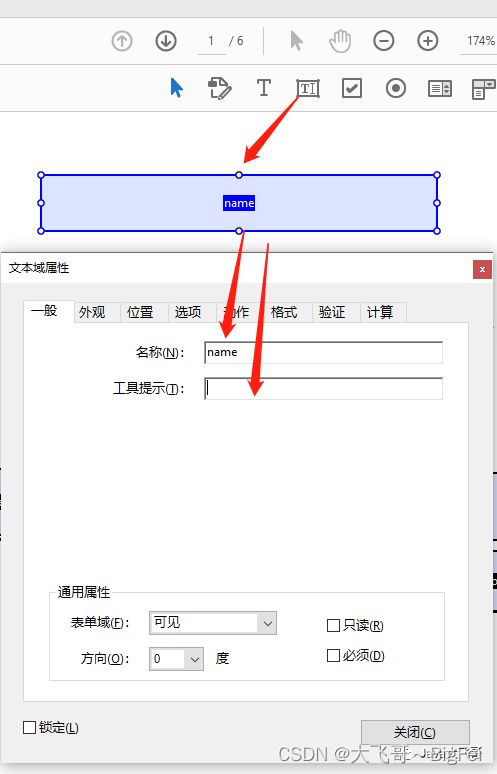
点击准备表单,选择一个pdf文件导入,点击拖动上方的添加文本域到指定的位置,然后编辑文本域的字段名字和说明,然后保存就制作好了pdf模板文件了。
![]()
7.最终效果

8.总结
未来是建立在开源之上的,只有开源才能繁荣,在实现某个功能的时候没有思路不妨去gitHub、gitee等开源的社区和平台上看看,多动手多思考,喜欢的老铁请一键三连:关注、点赞加收藏。