Mysql主从机制及高可用集群架构
需要查看更多的数据库相关的知识?点击这里
文章目录
-
- MySQL是怎么保证主备一致的?
- Mysql主从同步原理
- Mysql主从同步方式
-
- 异步复制(默认)
- 全同步复制
- 半同步复制
- 组复制
- Mysql高可用集群架构
-
- 一主多从
- MMM架构(双主多从)
- MHA架构(多主多从)
- MGR(Mysql Group Replication)
MySQL是怎么保证主备一致的?
在了解了Mysql日志系统后,我们知道,Mysql就是利用其日志系统中的binlog来保证主备的一致性的。
Mysql主从同步原理
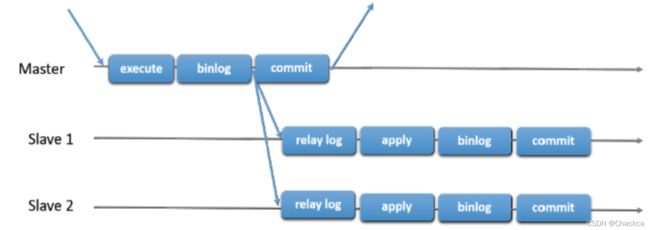
Slave从Master获取binlog二进制日志文件,然后再将日志文件解析成相应的SQL语句在从服务器上重新执行一遍主服务器的操作,Mysql通过这种方式来保证数据的一致性。由于主从复制的过程是异步复制的,因此Slave和Master之间的数据有可能存在延迟的现象,只能保证数据最终的一致性。在master和slave之间实现整个复制过程主要由三个线程来完成:
- Slave SQL thread线程:创建用于读取relay log中继日志并执行日志中包含的更新,位于slave端
- Slave I/O thread线程:读取 master 服务器Binlog Dump线程发送的内容并保存到slave服务器的relay log中继日志中,位于slave端
- Binlog dump thread线程(也称为IO线程):将bin-log二进制日志中的内容发送到slave服务器,位于master端
注意:如果一台主服务器配两台从服务器那主服务器上就会有两个Binlog dump 线程,而每个从服务器上各自有两个线程
随着从库数量的增加,主库的IO压力和网络压力也会随之增加,这时,多级复制架构应运而生。
多级复制架构只是在一主多从的基础上,在主库和各个从库之间增加了一个二级主库Master2,这个二级主库仅仅用来将一级主库推送给它的Binlog日志再推送给各个从库,以此来减轻一级主库的推送压力。
但它的缺点就是Binlog日志要经过两次复制才能到达从库,增加了复制的延时。
我们可以通过在二级从库上应用Blackhol存储引擎(黑洞引擎)来解决这一问题,降低多级复制的延时。
“黑洞引擎”就是写入Blackhole表中数据并不会写到磁盘上,所以这个Blackhole表永远是个空表,对数据的插入/更新/删除操作仅在Binlog中记录,并复制到从库中去。
主从复制具体流程如下:
- master提交完事务后,写⼊binlog
- slave连接到master,获取binlog
- master创建dump线程,推送binlog到slave
- slave启动⼀个IO线程读取同步过来的master的binlog,记录到relay log中继⽇志中
当Slave服务器的IO线程获取到Master服务器上IO线程发送的日志内容、日志文件及位置点后,会将binlog日志内容依次写到Slave端自身的Relay Log(即中继日志)文件(Mysql-relay-bin.xxx)的最末端,并将新的binlog文件名和位置记录到master-info文件中,以便下一次读取master端新binlog日志时能告诉Master服务器从新binlog日志的指定文件及位置开始读取新的binlog日志内容
- slave再开启⼀个sql线程读取relay log事件并在slave执⾏,完成同步
同步同时会在relay-log.info中记录当前应用中继日志的文件名和位置点
SQL线程执行完Relay log中的事件后,会将当前的中继日志Relay log删除,避免它占用更多的磁盘空间 - slave记录⾃⼰的binlog
为保证从库重启后,仍然知道从哪里开始复制,从库默认会创建两个文件master.info和relay-log.info,分别记录了从库的IO线程当前读取主库binlog的进度和SQL线程应用Relay-log的进度。可通过show slave status \G命令查看从库当前复制的状态

由于mysql默认的复制⽅式是异步的,主库把⽇志发送给从库后不关⼼从库是否已经处理,这样会产⽣⼀个问题就是假设主库挂了,从库处理失败了,这时候从库升为主库后,⽇志就丢失了。因此Mysql设计了其他的复制模型,继续往下看~
Mysql主从同步方式
异步复制(默认)
主库在执行完客户端提交的事务后会立即将结果返回给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主上已经提交的事务可能并没有传到从库上,如果此时,强行将从提升为主,可能导致新主上的数据不完整。
全同步复制
当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,主库完成一个事务的时间会被拉长,性能降低。
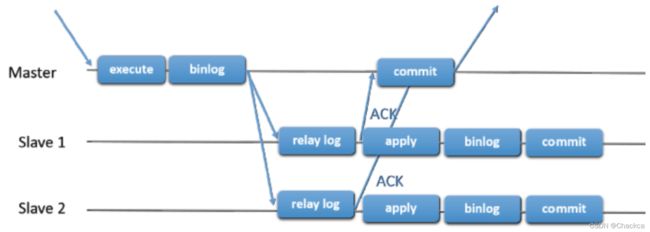
半同步复制
是介于全同步复制与全异步复制之间的一种,主库只需要等待至少一个从库节点收到并且 Flush Binlog 到 Relay Log 文件即可,主库不需要等待所有从库给主库反馈。同时,这里只是一个收到的反馈,而不是已经完全完成并且提交的反馈,如此,节省了很多时间。(从MySQL5.5开始,MySQL以插件的形式支持半同步复制)
组复制
基于传统异步复制和半同步复制的缺陷——数据的一致性问题无法保证,MySQL官方在5.7.17版本正式推出组复制(MySQL Group Replication,简称MGR)。
由若干个节点共同组成一个复制组,一个事务的提交,必须经过组内大多数节点(N / 2 + 1)决议并通过,才能得以提交。如上图所示,由3个节点组成一个复制组,Consensus层为一致性协议层,在事务提交过程中,发生组间通讯,由2个节点决议(certify)通过这个事务,事务才能够最终得以提交并响应。
引入组复制,主要是为了解决传统异步复制和半同步复制可能产生数据不一致的问题。组复制依靠分布式一致性协议(Paxos协议的变体),实现了分布式下数据的最终一致性,提供了真正的数据高可用方案(是否真正高可用还有待商榷)。其提供的多写方案,给我们实现多活方案带来了希望。
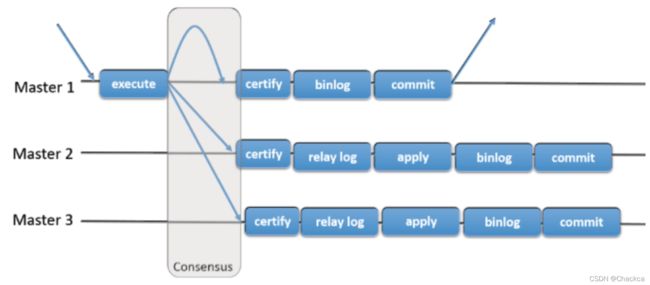
组复制脱离了传统的主从模式结构,是一个具有容错功能的集群架构,在组复制的架构中,有多个 server成员构成,并且每个成员都可以独立执行事务,也就意味着多写的功能,但是所有的读写事务必须在冲突校验完成后才能提交,如果是只读型的事务那么会直接提交。当某个节点上发出一个读写的事务准备提交时,那么这个节点就会向整个集群开始广播这次读写的变更和对应的一个校验标识符,然后会针对这个事务产生一个全局的顺序号,由于是有顺序号的,所以集群中的每个成员都会按照顺序去执行事务的变更从而保证了数据的一致性。
如果在不同的 server 上执行了相同的操作,并且产生了事务冲突,那么校验机制就会做成相应的判断,通常先提交的事务先执行,后提交的回滚。所以从某种程度上来说,组复制是一种伪同步复制模式。
Mysql高可用集群架构
Mysql高可用架构都有如下特点:
- 对主从复制集群中的Master节点进行监控
- 自动的对Master进行迁移,通过VIP。
- 重新配置集群中的其它slave对新的Master进行同步
一主多从
MMM架构(双主多从)
Multi Master Replication Manager,需要两个Master,同一时间只有一个Master对外提供服务,可以说是主备模式。

MHA架构(多主多从)
MySQL Master High Availability

MGR(Mysql Group Replication)
MGR是基于现有的MySQL架构实现的复制插件,可以实现多个主对数据进行修改,使用paxos协议复制,不同于异步复制的多Master复制集群,其采用组复制的机制。
MySQL MGR 集群最少3个server节点共同组成的分布式集群,一种share-nothing复制方案,每个server节点都有完整的副本。

其具备如下的特性:
- 高一致性,基于原生复制及Paxos协议的组复制技术,并以插件的方式提供,提供一致数据安全保证;
- 高容错性,只要不是大多数节点坏掉就可以继续工作,有自动检测机制,当不同节点产生资源争用冲突时,不会出现错误,按照先到者优先原则进行处理,并且内置了自动化脑裂防护机制;
- 高扩展性,节点的新增和移除都是自动的,新节点加入后,会自动从其他节点上同步状态,直到新节点和其他节点保持一致,如果某节点被移除了,其他节点自动更新组信息,自动维护新的组信息;
- 高灵活性,其支持以下集群方式
- 单主模式(官方推荐):MGR集群会选出primary节点负责写请求,primary节点与其它节点都可以进行读请求处理.
- 多主模式:客户端可以随机向MySQL节点写入数据
MGR要求组内每个MySQL实例都要基于ROW格式的binlog,并开启GTID。
什么是MySQL的GTID?
GTID(Global Transaction ID,全局事务ID)是全局事务标识符, 是一个已提交事务的编号,并且是一个全局唯一的编号。
GTID是从MySQL 5.6版本开始在主从复制方面推出的重量级特性。
GTID实际上是由UUID+TID组成的。其中UUID是一个MySQL实例的唯一标识。
GTID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增。
GTID有如下几点作用:
- 根据GTID可以知道事务最初是在哪个实例上提交的。
- GTID的存在方便了Replication的Failover。因为不用像传统模式复制那样去找master_log_file和master_log_pos。
- 基于GTID搭建主从复制更加简单, 确保每个事务只会被执行一次。
尽管MySQL在2016年就推出了MGR该功能,同时我们也知道有很多好处,并且有大胆的公司采用进行测试甚至部署线上环境,据公开资料网易、滴滴都有使用,国内部分商业银行也有使用,但仍然有不少人处于观望状态,主要有以下几点原因导致:
需求不是特别强烈:很多业务情况使用MySQL半同步和异步复制足够满足业务要求,配合MHA第三方组件满足了绝大部分场景需求。
分布式新事物:本身分布式这个概念已经存在多年,但是由于MGR推出年限较短,且我们搜索官方bug库任然存在较多未解决的bug。用户使用排查问题较为困难,且由于分布式设计导致问题复现难也是一种阻碍。
生态不成熟:官方几乎没有完全成熟用来构建整套高可用架构的解决方案,如果想要大规模使用还是需要更加成熟的生态。