Deformable Convolutional 可变形卷积网络
Deformable Convolutiona 可变形卷积网络
论文链接:https://arxiv.org/abs/1910.02940
可变形卷积,顾名思义,就是能够改变形状的卷积,普通的卷积一般都是使用一个kk的规则的卷积核对图像进行卷积操作,几何结构比较固定,感受野比较固定,而可变形卷积可以通过偏移量,把kk的卷积核变成不规则的网格,对原图进行卷积操作,进行端到端的学习,能够自适应地确定感受野的大小,关注到图像需要关注的地方

- 普通卷积运算
R={(-1,-1),(-1,0),…,(0,1),(1,1)}
R:在原图上的采样点,尺寸kxk,其实就是卷积核
pn:枚举R中在原图对应的位置
p0:输出特征图y上的每个位置

- 可变形卷积运算
R:在原图上的采样点,尺寸kxk,其实就是卷积核
pn:枚举R中在原图对应的位置
p0:输出特征图y上的每个位置
Δpn:(n=1,…,N), N = |R| = k x k
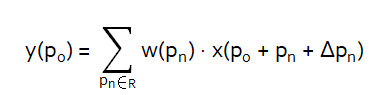
由于偏移量ΔPn一般都为浮点型的数值,那么x(P0+Pn+ΔPn)可通过双线性插值计算
其中p=p0+pn+Δpn, g(a,b)=max(0, 1-|a-b|), q就是p周围离p最近的4个点(下面对双线性插值的介绍中会写到)
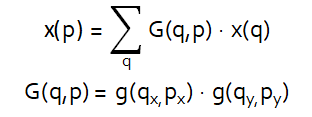
下面简单说一下双线性插值

由于p的位置(x,y)经过偏移后,那么数值一般都不是整型的了,但是图像上的像素位置都是整型的,浮点型就不能够在图像上获取数值了,就可以通过距离p最近的4个点,通过双线性插值计算得到p点的具体数值
计算公式:

看完这里的双线性插值公式和上面原始论文给出的双线性插值公式之后是不是会有点疑惑,为什么这里的有分母,论文的没有分母的?
其实是这样子的,图像是由像素组成的,图片的尺寸w*h也就表示了图像的像素点的数量,而x,y就是表示像素的位置,像素点与点之间的距离y(n+1)-y(n)=1,x(n+1)-x(n)=1,所以论文中的公式也就自然没有了分母
可变形卷积的操作流程
1.对输入图像img(B,C,H,W)进行卷积,得到偏移量Δ(B,2xkxk,H,W)
2.将偏移量与原图对应位置相加,获取偏移后的位置
3.通过双线性插值获取偏移后的位置上的数值
4.将每个R对应的数值加权再累加就能够得出输出特征图y上的所有点了,如以下公式所示

代码示例
class Deform_Conv2d(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size=3, padding=0, stride=1, dilation=1):
super(Deform_Conv2d, self).__init__()
self.in_channel = in_channel
self.out_channel = out_channel
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.dilation = dilation
# 用于生成偏移量
self.conv1 = nn.Conv2d(in_channel, 2*kernel_size*kernel_size,
kernel_size=kernel_size, padding=dilation, stride=stride, dilation=dilation)
self.conv2 = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, stride=kernel_size)
def forward(self, x):
b, c, h, w = x.shape
# 生成R
# 获取每个像素卷积核的位置
R_xy = get_R(self.kernel_size, b, self.dilation)
# 生成每个像素点的位置
P_xy = get_P(h, w, self.kernel_size, b, self.stride, self.dilation)
# 获取偏移量
offset_xy = self.conv1(x).data
# 获取所有卷积核偏移后的位置 [B,2*k*k,H,W]
offset = R_xy + P_xy + offset_xy
# 不加dilation的话R的取值就会超过原图的边界
pad = torch.nn.ZeroPad2d(padding=self.dilation)
x = pad(x)
# 获取双线性插值后的值
q = get_q(h, offset, x)
# 将获取到的值转换为B,C,H*K,W*K的格式
z = q.permute(0, 4, 1, 2, 3).contiguous()
z = z.view(b, c, b1.size(2), P_xy.size(3), self.kernel_size, self.kernel_size)
z = z.permute(0, 1, 2, 4, 3, 5)
q = z.contiguous().view(b, c, P_xy.size(2)*self.kernel_size, P_xy.size(3)*self.kernel_size)
q = Variable(q)
# 进行卷积,卷成B,C,H,W的格式
out = self.conv2(q)
return out
# 获取R
def get_R(kernel_size, b, dilation):
a = torch.arange(-(kernel_size//2), kernel_size//2+1)
a = torch.Tensor([i for i in product(a, a)])
a = a.view(-1, 1)
a.unsqueeze_(dim=-1)
a.unsqueeze_(dim=0)
a = a.expand(b, a.size(1), a.size(2), a.size(3))
return a * (dilation + 1)
# 获取每个像素的坐标
def get_P(h, w, k, b, stride, dilation):
# 因为padding的原因,所以有值的像素点应该从dilation开始
h1 = torch.arange(dilation, h+dilation, stride)
w1 = torch.arange(dilation, w+dilation, stride)
w2 = w1.expand(h1.size(0), w1.size(0))
h2 = h1.unsqueeze_(1).expand(h1.size(0), w1.size(0))
p = torch.cat((w2, h2), dim=0)
p = p.unsqueeze(0).expand(k*k, p.size(0), p.size(1))
p = p.contiguous()
p = p.view(2*k*k, h1.size(0), w1.size(0))
p.unsqueeze_(0)
p = p.expand(b, p.size(1), p.size(2), p.size(3))
return p
def get_q(h, offset, x):
# 获取最小值
lt_offset = offset.floor().long()
# 获取大的值
gt_offset = lt_offset + 1
# 获取偏移量x
offset_x = offset.permute(0, 2, 3, 1)[:, :, :, 0::2]
# 获取偏移量y
offset_y = offset.permute(0, 2, 3, 1)[:, :, :, 1::2]
lt_offset = torch.clamp(lt_offset, min=0, max=h + 1)
gt_offset = torch.clamp(gt_offset, min=0, max=h + 1)
# 求周围四个q点的x和y
min_x = lt_offset.permute(0, 2, 3, 1)[:, :, :, 0::2]
min_y = lt_offset.permute(0, 2, 3, 1)[:, :, :, 1::2]
max_x = gt_offset.permute(0, 2, 3, 1)[:, :, :, 0::2]
max_y = gt_offset.permute(0, 2, 3, 1)[:, :, :, 1::2]
x = x.permute(0, 2, 3, 1)
# 获取周围4个q点的值
q1 = torch.from_numpy(x.data.numpy()[:, min_y, min_x][0])
q2 = torch.from_numpy(x.data.numpy()[:, min_y, max_x][0])
q3 = torch.from_numpy(x.data.numpy()[:, max_y, min_x][0])
q4 = torch.from_numpy(x.data.numpy()[:, max_y, max_x][0])
min_x = min_x.float()
min_y = min_y.float()
max_x = max_x.float()
max_y = max_y.float()
# 这里是px-qx,py-qy
# 获取双线性插值后的值
q1_idx = ((1 - torch.abs(offset_x - min_x)) * (1 - torch.abs(offset_y - min_y))).unsqueeze(-1).expand(q1.shape)
q2_idx = ((1 - torch.abs(offset_x - max_x)) * (1 - torch.abs(offset_y - min_y))).unsqueeze(-1).expand(q2.shape)
q3_idx = ((1 - torch.abs(offset_x - min_x)) * (1 - torch.abs(offset_y - max_y))).unsqueeze(-1).expand(q3.shape)
q4_idx = ((1 - torch.abs(offset_x - max_x)) * (1 - torch.abs(offset_y - max_y))).unsqueeze(-1).expand(q4.shape)
q = q1_idx * q1 + q2_idx * q2 + q3_idx * q3 + q4_idx * q4
return q
函数get_P的操作是比较让人迷惑的是吧,我们来单独看一下get_P的代码
由于我们需要将偏移量和原图的位置索引对应相加,再加上卷积核的位置数值,就能够获取原图上所有卷积核的位置偏移数值,就能够通过这个数值进行双线性插值获取具体值

生成的w2就是对应这个图片里的所有x的坐标,h2就是对应这个图片所有y的坐标
这里的目的是把xy拆分开来再和偏移量进行相加操作,元素位置对应了就能够直接相加,不需要循环迭代操作所有元素,提高效率
# 获取每个像素的坐标
def get_P(h, w, k, b, stride, dilation):
# 因为padding的原因,所以有值的像素点应该从dilation开始
h1 = torch.arange(dilation, h+dilation, stride)
w1 = torch.arange(dilation, w+dilation, stride)
w2 = w1.expand(h1.size(0), w1.size(0))
h2 = h1.unsqueeze_(1).expand(h1.size(0), w1.size(0))
p = torch.cat((w2, h2), dim=0)
p = p.unsqueeze(0).expand(k*k, p.size(0), p.size(1))
p = p.contiguous()
p = p.view(2*k*k, h1.size(0), w1.size(0))
p.unsqueeze_(0)
p = p.expand(b, p.size(1), p.size(2), p.size(3))
return p
如果有什么错误的地方,还请各位大神评论指点