7. Redis 主从复制
文章目录
-
- 7. 主从复制
-
- 简介
- 7.1 Redis 主从几种方案拓扑
- 7.2 主从复制配置
-
- 7.2.1 同一台机器测试配置
- 7.2.2 多台机器测试配置
-
- 7.2.2.1 修改配置文件
- 注意事项:
- 7.2.2.2 查看机器信息
- 7.3 测试数据
- 7.4 主从复制原理
-
- 7.4.1 全量复制
-
- :large_orange_diamond: replication buffer 缓冲区
- :large_blue_diamond: 命令传播
- :large_orange_diamond: 树状拓扑分担主库压力
- 7.4.2 增量复制
-
- :large_blue_diamond: 问题:同步过程中网络断开怎么办?
- :large_orange_diamond: 增量复制
- :large_blue_diamond: Repl_backlog_buffer 环形缓冲区
- 7.4.3 关闭持久化时,复制的安全性
- 7.4.4 无磁盘复制模式
- 7.5 总结
7. 主从复制
简介
前言
一般来说,要将Redis运用于工程中,只使用一台Redis服务是万万不能的,在实际的场景当中单一节点的redis容易面临风险。主要原因有:
- 结构:单个Redis服务器会发生单点故障,其次一台服务器需处理所有的请求负载,压力较大
- 容量:单个Redis服务器内存容量有限,就算一台Redis服务器内存容量为256g,也不能将所有内存用作Redis存储内存,通常情况,单台Redis最大使用内存不应该超过20g
- 如果服务器发生故障,就需要迁移到另外一台服务器上并且还要考虑数据同步问题,另外也存在容量瓶颈现象,当有需求需要扩容Redis内存,就需不断加升内存
解决办法
- 通常,我们为了避免服务的单点故障,会把数据复制到多个副本并放在不同的服务器上,且这些拥有数据副本的服务器可以用于处理客户端的读请求,扩展整体的性能!
什么是主从复制
- 主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master/Leader),后者称为从节点(Slave/Follower), 数据的复制是单向的!只能由主节点复制到从节点(主节点以写为主、从节点以读为主)。
- 默认情况下,每台Redis服务器都是主节点,一个主节点可以有0个或者多个从节点,但每个从节点只能由一个主节点。

解析:
- 采用读写分离。主服务器master可提供读写操作(为了减轻压力通常只处理写请求),当master的数据发生变化,master会发出命令流来保持对salve的数据更新(slave通常提供读)
主从复制的好处
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余的方式。
- 故障恢复:当主节点故障时,从节点可以暂时替代主节点提供服务,是一种服务冗余的方式
- 负载均衡:在主从复制的基础上,配合读写分离,由主节点进行写操作,从节点进行读操作,分担服务器的负载;尤其是在多读少写的场景下,通过多个从节点分担负载,提高并发量。
- 高可用(集群)基石:主从复制还是哨兵和集群能够实施的基础。
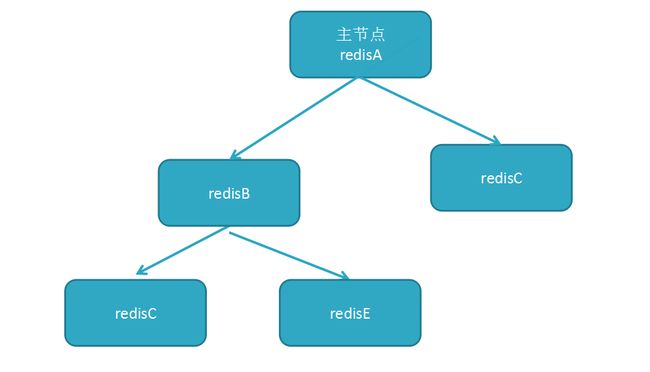
7.1 Redis 主从几种方案拓扑
- 一主一从:
用于主节点故障转移从节点,当主节点的“写”命令并发高且需要持久化,可以只在从节点开启AOF(主节点不需要),这样即保证了数据的安全性,也避免持久化对主节点的影响

- 一主多从:
针对“读”较多的场景,“读”由多个从节点来分担,但节点越多,主节点同步到多节点的次数也越多,影响带宽,也加重主节点的稳定

- 树状主从:
此方案可以解决上面 “一主多从" 的缺点(主节点推送次数多压力大),主节点只推送一次数据到从节点B,再由从节点B推送到C,减轻主节点推送的压力(感觉有点像代理,此时 B 节点类似于 C 节点的 master)。
7.2 主从复制配置
注:
默认情况下,每台Redis服务器都是主节点;我们一般情况下只用配置从机就好了!
7.2.1 同一台机器测试配置
将 redis.conf 配置文件 cp 多份
修改文件名(例如:redis6379.conf 、redis6380.conf 、redis6381.conf)
修改对应的端口号、pid文件名、日志文件名、rdb文件名
示例:redis6379.conf
port 6379
logfile “6379.log”
pidfile /var/run/redis_6379.pid
dbfilename dump6379.rdb
可以参考网上的案例,注意版本不同即可
# 设置为后台运行
daemonize yes
port 6379
# 如果是一台机器伪造3个服务器,需要命名区分,如果是3台机器则不需要
# 保存pid的文件 ————每个conf配置文件对应自己的端口号区分下名称
pidfile /var/run/redis_6379.pid # 即redis81.conf就命名:redis_6381.pid,以此类推
# 指定日志文件, (命名区分同上)
logfile "6379.log"
# 指定rdb文件的名称 (命名区分同上)
dbfilename dump6379.rdb
-- 如果是三台机器 上述命名可以不区分,但是这里绑定IP就是机器的IP地址
# 绑定的主机地址,这里注释掉,开放ip连接
#bind 127.0.0.1
7.2.2 多台机器测试配置
本次测试使用三台机器测试
| ip | 角色 | 端口 | 版本信息 |
|---|---|---|---|
| 192.168.169.150 | master | 6379 | Redis server v=7.0.1 |
| 192.168.169.151 | slave | 6379 | Redis server v=7.0.1 |
| 192.168.169.152 | slave | 6379 | Redis server v=7.0.1 |
7.2.2.1 修改配置文件
主机配置文件修改
注意,这里需要配置密码也可能是因为误开了 protected mode 保护模式,后期在测试将 protected mode 改为 no
# 注意:使用多台机器配置主从时一定要设置密码,不然主机会看不到自己的从机
requirepass <password>
从机配置文件修改
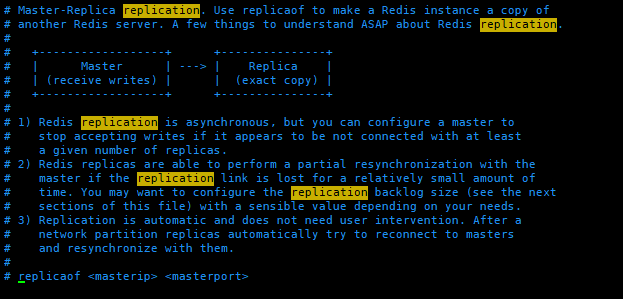
# 主机的IP、端口
replicaof <masterip> <masterport>
# 注意1:因为 master 设置了 requirepass 密码,slave 用此选项指定 master 认证密码
masterauth <master-password> 默认没有密码注释掉
# 注意2:作为从服务器,默认情况下是只读的(yes),可以修改成NO,用于写(不建议)。
replica-read-only yes
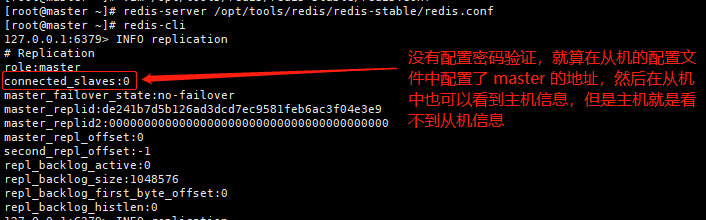
注意事项:
测试发现,在配置主从时,如果在 master 中没有配置密码验证,那么就算在 salve 的配置文件中配置了 master 的地址及端口,而且在 salve 中也可以 通过 info replication 查看到主机信息,但是 master 就是不能获取到 salve 的数量信息。
单台主机 cp 多个 redis.conf 配置多个 redis 进程的方案没有测试连接时是否需要开启密码验证,参考网上一些案例没有配置,可能是新版本原因,本次使用的是目前最新版 7.0.1
- 解决方案
# 在 maste 中将 requirepass 配置验证密码,示例:
requirepass 123456
# 在 slave 中将 masterauth 配置成对应的 master 的验证密码
masterauth 123456

7.2.2.2 查看机器信息
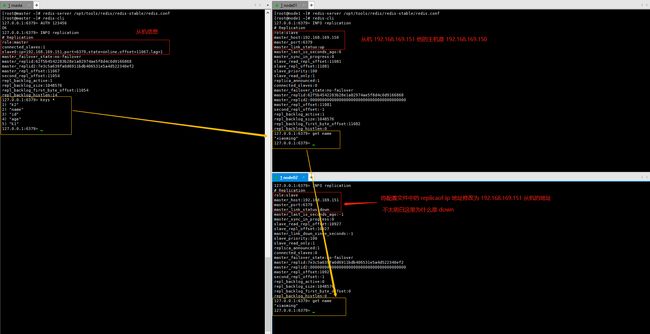
INFO replication
# INFO replication 参数解析
127.0.0.1:6379> INFO replication
# Replication
role:master # 当前实例的角色master还是slave
connected_slaves:1 # slave的数量
slave0:ip=192.168.169.151,port=6379,state=online,offset=11067,lag=1 # slave机器的信息、状态
master_failover_state:no-failover
master_replid:62f5b4542283b28e1a82974ae5f8d4c0d9166868 # 主实例启动随机字符串
master_replid2:7e3c5a639fa0d6911bdb406531e5a4d522340ef2 # 主实例启动随机字符串2
master_repl_offset:11067 # 主从同步偏移量,此值如果和上面的 slave0 中的 offset 相同说明主从一致没延迟,与master_replid可被用来标识主实例复制流中的位置。
second_repl_offset:11054 # 主从同步偏移量2,此值如果和上面的offset相同说明主从一致没延迟
repl_backlog_active:1 # 复制缓冲区是否开启
repl_backlog_size:1048576 # 复制缓冲区大小
repl_backlog_first_byte_offset:11054 # 复制缓冲区里偏移量的大小
repl_backlog_histlen:14 # 此值等于 master_repl_offset - repl_backlog_first_byte_offset,该值不会超过repl_backlog_size的大小

7.3 测试数据
1️⃣ 主机写数据,从机读数据
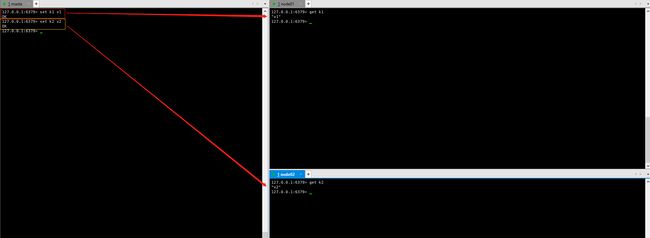
2️⃣ 从机只能读,不能写,主机可读可写但是多用于写

3️⃣ 主机断电宕机
当主机断电宕机后,默认情况下从机的角色不会发生变化 ,集群中只是失去了写操作,当主机恢复以后,又会连接上从机恢复原状。
主机宕机后,从机读取数据不影响
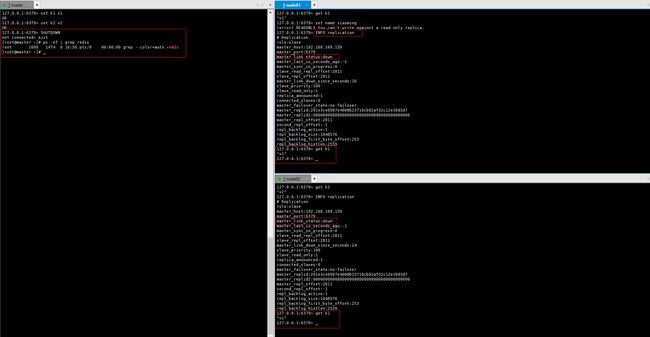
4️⃣ 主机重新连接
主机重新连接后,正常运行,写入的新数据也能被从机立刻读取!
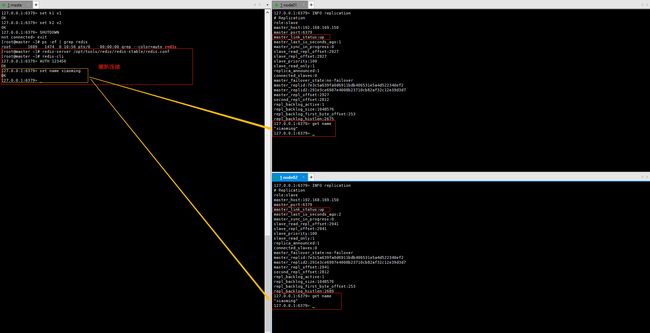
5️⃣ 从机宕机
一台从机宕机后不影响主机的写入和其他从机的读取
- 从机恢复
从机恢复之后也可以读取到之前宕机时主机写入的数据

6️⃣ 思考:为什么从机宕机恢复后仍能收到主机之前写入的数据
7.4 主从复制原理
在2.8版本之前只有全量复制,而2.8版本后有全量和增量复制
全量复制:将主节点中整个数据文件都发送给从节点(重型操作)增量复制:主和从节点在中断期间,主库所执行的写命令发送给从节点注意:如中断时间过长,主节点没完全保存中断期间执行的写命令,仍然会使用全量复制
参考地址:https://blog.csdn.net/qq_34827674/article/details/123448733
7.4.1 全量复制
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。
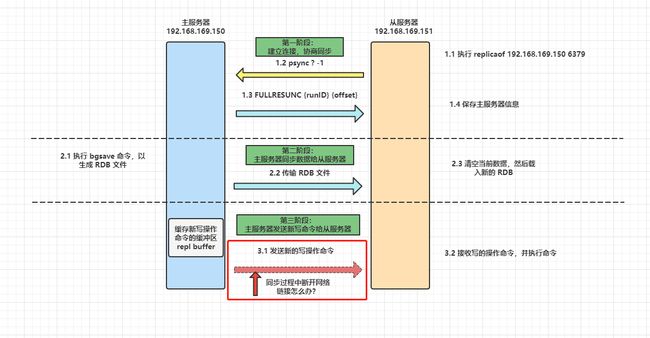
- Redis的主从复制过程大体上分3个阶段:建立连接、数据同步、命令传播

1️⃣ 第一阶段:主从库间建立连接,协商同步
步骤解析:
从库执行了 replicaof 命令后,从服务器就会给主服务器发送
psync命令,表示要进行数据同步。psync 命令包含两个参数,分别是主服务器的 runID 和复制进度 offset。
- runID,每个 Redis 服务器在启动时都会自动生产一个随机的 ID 来唯一标识自己。当从服务器和主服务器第一次同步时,因为不知道主服务器的 run ID,所以将其设置为 “?”。
- offset,表示复制的进度,第一次同步时,其值为 -1。
主服务器收到 psync 命令后,会用
FULLRESYNC作为响应命令返回给对方。并且这个响应命令会带上两个参数:主服务器的 runID 和主服务器目前的复制进度 offset。从服务器收到响应后,会记录这两个值。
FULLRESYNC 响应命令的意图是采用全量复制的方式,也就是主服务器会把所有的数据都同步给从服务器。
第一阶段的工作时为了全量复制做准备。
2️⃣ 第二阶段:主服务器同步数据给从服务器
步骤解析
- 主服务器会执行 bgsave 命令来生成 RDB 文件,然后把文件发送给从服务器
- 从服务器收到 RDB 文件后,会先清空当前的数据,然后载入 RDB 文件(避免从库的旧数据与主机发过来的rdb数据文件内容冲突)
- 主库同步给从库数据过程中,不会阻塞,仍然正常接收客户端请求
但是这期间的写操作命令并没有记录到刚刚生成的 RDB 文件中,这时主从服务器间的数据就不一致了。
那么为了保证主从服务器的数据一致性,主服务器会将在 RDB 文件生成后收到的写操作命令,写入到 replication buffer 缓冲区里。
3️⃣ 主服务器发送新写操作命令给从服务器
当主库把RDB 文件传送给从库完毕后,就会把 replication buffer 缓冲区中的数据再发给从库,从库再重新执行这些操作。完成主从库的数据一致性!
至此,主从服务器的第一次同步的工作就完成了
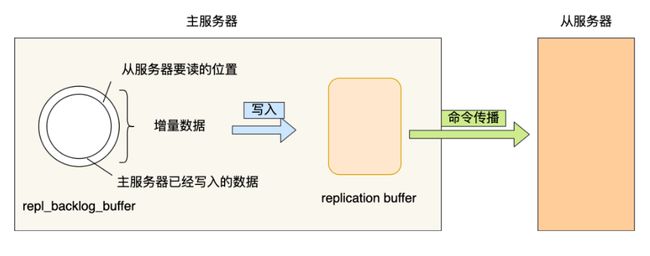
replication buffer 缓冲区
主库会为每一个连接到自己的客户端创建一个replication buffer,用来发送增量写命令。
即从库同步主库的rdb文件阶段,主库新产生的写命令会存入到该缓冲区,等从机完成rdb文件的同步后,主库再把该缓冲区的数据发给从库继续同步,保证
主从数据一致性
▶️ 问题一:如果replication buffer缓冲区写满了怎么办?
答:无论客户端是普通客户端还是从库,会断开其客户端连接,重新尝试全量同步
▶️ 问题二:如何避免replication buffer缓冲区写满?
答:可以在redis.config文件中配置如下参数:
主从复制缓存区,32mb表示缓冲区最大是32mb,8mb 60表示如果60s内写入量超过8mb,就会溢出 client-output-buffer-limit slave 32mb 8mb 60
**注意:**把缓冲区最大值调大,或把每秒允许的写入量增加,可减小缓冲区溢出的概率。但如果连接redis服务器的客户端越多,对内存的损耗也越大,故控制从节点的数量,也可以控制缓存区对内存的开销。当然也可以控制主节点的写命令接收速率。
命令传播
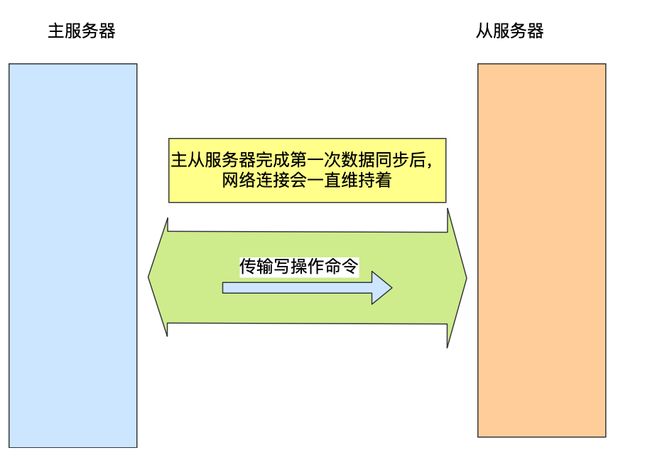
主从服务器在完成第一次同步后,双方之间就会维护一个 TCP 连接
后续主服务器可以通过这个连接继续将写操作命令传播给从服务器,然后从服务器执行该命令,使得与主服务器的数据库状态相同。
而且这个连接是长连接的,目的是避免频繁的 TCP 连接和断开带来的性能开销。
上面的这个过程被称为基于长连接的命令传播,通过这种方式来保证第一次同步后的主从服务器的数据一致性。
树状拓扑分担主库压力
从上面的分析中可以看出,主从服务器在第一次数据同步的过程中,主服务器会做两件耗时的操作:生成 RDB 文件和传输 RDB 文件。
主服务器是可以有多个从服务器的,如果从服务器数量非常多,而且都与主服务器进行全量同步的话,就会带来两个问题:
- 由于是通过 bgsave 命令来生成 RDB 文件的,那么主服务器就会忙于使用 fork() 创建子进程,如果主服务器的内存数据非大,在执行 fork() 函数时是会阻塞主线程的,从而使得 Redis 无法正常处理请求;
- 传输 RDB 文件会占用主服务器的网络带宽,会对主服务器响应命令请求产生影响。
参考案例说明:
这种情况就好像,刚创业的公司,由于人不多,所以员工都归老板一个人管,但是随着公司的发展,人员的扩充,老板慢慢就无法承担全部员工的管理工作了。
要解决这个问题,老板就需要设立经理职位,由经理管理多名普通员工,然后老板只需要管理经理就好。
Redis 也是一样的,从服务器可以有自己的从服务器,我们可以把拥有从服务器的从服务器当作经理角色,它不仅可以接收主服务器的同步数据,自己也可以同时作为主服务器的形式将数据同步给从服务器,组织形式如下图:
通过这种方式,主服务器生成 RDB 和传输 RDB 的压力可以分摊到充当经理角色的从服务器。

- 修改配置
# 修改从服务器的目标服务器 IP
replicaof <目标服务器的IP> 6379
- 此时如果目标服务器本身也是「从服务器」,那么该目标服务器就会成为「经理」的角色,不仅可以接受主服务器同步的数据,也会把数据同步给自己旗下的从服务器,从而减轻主服务器的负担。
示例:
7.4.2 增量复制
问题:同步过程中网络断开怎么办?
第二阶段完成rdb文件的同步后,在开始执行第三阶段的时候,此时断开连接怎么办?如何保证数据的一致性?
主从服务器在完成第一次同步后,就会基于长连接进行命令传播。
可是,网络总是存在不稳定情况,如果主从服务器间的网络连接断开了,那么就无法进行命令传播了,这时从服务器的数据就没办法和主服务器保持一致了,客户端就可能从「从服务器」读到旧的数据。

想要解答上面的疑问,看下面的增量复制
增量复制
在master主节点与slave从节点中断连接期间,主节点所产生的新的写命令,会被发送给重连后的从节点(只是中断期间产生新写命令,而不是复制全部数据给从库)
这就是为什么从机断联了,重连后,也能恢复主机在从机宕机期间新产生的数据

▶️ 步骤解析:
- 从服务器在恢复网络后,会发送 psync 命令给主服务器,此时的 psync 命令里的 offset 参数不是 -1;
- 主服务器收到该命令后,然后用 CONTINUE 响应命令告诉从服务器接下来采用增量复制的方式同步数据;
- 然后主服务将主从服务器断线期间,所执行的写命令发送给从服务器,然后从服务器执行这些命令。
▶️ 问题:主服务器怎么知道要将哪些增量数据发送给从服务器呢?
解答:
-
repl_backlog_buffer,是一个「环形」缓冲区,用于主从服务器断连后,从中找到差异的数据;
-
replication offset,标记上面那个缓冲区的同步进度,主从服务器都有各自的偏移量,主服务器使用 master_repl_offset 来记录自己「写」到的位置,从服务器使用 slave_repl_offset 来记录自己「读」到的位置。
Repl_backlog_buffer 环形缓冲区
在主服务器进行命令传播时,不仅会将写命令发送给从服务器,还会将写命令写入到 repl_backlog_buffer 缓冲区里,因此 这个缓冲区里会保存着最近传播的写命令。
网络断开后,当从服务器重新连上主服务器时,从服务器会通过 psync 命令将自己的复制偏移量 slave_repl_offset 发送给主服务器,主服务器根据自己的 master_repl_offset 和 slave_repl_offset 之间的差距,然后来决定对从服务器执行哪种同步操作:
- 如果判断出从服务器要读取的数据还在 repl_backlog_buffer 缓冲区里,那么主服务器将采用增量同步的方式;
- 相反,如果判断出从服务器要读取的数据已经不存在 repl_backlog_buffer 缓冲区里,那么主服务器将采用全量同步的方式。
当主服务器在 repl_backlog_buffer 中找到主从服务器差异(增量)的数据后,就会将增量的数据写入到 replication buffer 缓冲区
注意:
- 主库不会给每个从库分配一个repl_backlog_buffer,而是所有从库共享一个
- repl_backlog_buffer 缓行缓冲区的默认大小是 1M,并且由于它是一个环形缓冲区,所以当缓冲区写满后,主服务器继续写入的话,就会覆盖之前的数据。所以当主服务器的写入速度远超于从服务器的读取速度,缓冲区的数据一下就会被覆盖
- 在网络恢复时,如果从服务器想读的数据已经被覆盖了,主服务器就会采用全量同步,这个方式比增量同步的性能损耗要大很多
- 因此,为了避免在网络恢复时,主服务器频繁地使用全量同步的方式,我们应该调整下 repl_backlog_buffer 缓冲区大小,尽可能的大一些,减少出现从服务器要读取的数据被覆盖的概率,从而使得主服务器采用增量同步的方式。
- repl_backlog_buffer 最小的大小可以根据这面这个公式估算。

公式说明:
- second 为从服务器断线后重新连接上主服务器所需的平均 时间(以秒计算)。
- write_size_per_second 则是主服务器平均每秒产生的写命令数据量大小。
示例:
如果主服务器平均每秒产生 1 MB 的写命令,而从服务器断线之后平均要 5 秒才能重新连接主服务器。
那么 repl_backlog_buffer 大小就不能低于 5 MB,否则新写地命令就会覆盖旧数据了。
为了应对一些突发的情况,可以将 repl_backlog_buffer 的大小设置为此基础上的 2 倍,也就是 10 MB。
# 修改 redis.conf 配置文件
repl-backlog-size 1mb
7.4.3 关闭持久化时,复制的安全性
在进行主从复制设置时,强烈建议在主服务器上开启持久化,当不能这么做时,例如由于非常慢的磁盘性能而导致的延迟问题,应该配置实例来避免重置后自动重启
❓ 为什么不开启持久化的主服务器自动重启非常危险呢?
- 假设A节点是master,并关闭持久化,节点B和C 从 节点A复制数据。
- 一旦A节点发生崩溃,由于具有自动重启系统可以自动重启,但由于关闭了持久化,节点重启后其数据为空
- 节点B和C 会从 节点A进行复制数据,由于节点A是空数据集,复制后的数据也只是一个空数据集,从而覆盖了它们之前的数据副本
☛ 结论:如果数据比较重要,使用了主从复制并关闭了master的持久化,都应禁止实例自动重启
7.4.4 无磁盘复制模式
Redis 默认是磁盘复制,从2.8.18版本开始尝试支持无磁盘的复制。使用这种设置时,子进程直接将RDB通过网络发送给从服务器,不使用磁盘作为中间存储
无磁盘复制模式:master创建一个新进程直接 dump RDB 到 slave的socket,不经过主进程,不经过硬盘。适用于disk较慢,并且网络较快的时候。
- repl-diskless-sync参数:启动无磁盘复制
- repl-diskless-sync-delay参数:传输开始的延迟时间(单位:秒)
master 等待一个 repl-diskless-sync-delay 的秒数,如果没 slave 来的话,就直接传,后来的得排队等了; 否则就可以一起传。
7.5 总结
本次测试主从复制的三种模式:全量复制、基于长连接的命令传播、增量复制。
-
主从服务器第一次同步的时候,就是采用全量复制,此时主服务器会两个耗时的地方,分别是生成 RDB 文件和传输 RDB 文件。为了避免过多的从服务器和主服务器进行全量复制,可以把一部分从服务器升级为「经理角色」,让它也有自己的从服务器,通过这样可以分摊主服务器的压力。
-
第一次同步完成后,主从服务器都会维护着一个长连接,主服务器在接收到写操作命令后,就会通过这个连接将写命令传播给从服务器,来保证主从服务器的数据一致性。
-
如果遇到网络断开,增量复制就可以上场了,不过这个还跟 repl_backlog_size 这个大小有关系。
-
如果 repl_backlog_size 配置的过小,主从服务器网络恢复时,可能发生「从服务器」想读的数据已经被覆盖了,那么这时就会导致主服务器采用全量复制的方式。所以为了避免这种情况的频繁发生,要调大这个参数的值,以降低主从服务器断开后全量同步的概率。