高可用PgSQL集群架构设计与落地
高可用PgSQL集群架构设计与落地
[PostgreSQL中文社区](javascript:void(0) 今天
把数据库拉起来是一回事,部署专业水准的数据库集群又是另一回事。想要真正用好管好数据库,需要良好的架构设计让多种组件协同配合起来。今天我们就来介绍一下典型的高可用PgSQL集群架构及其 落地方式。
本文将以 Pigsty v0.8 为例,介绍高可用集群的设计与部署。
“ Pigsty针对大规模数据库集群监控与管理而设计,提供业界顶尖的PostgreSQL监控系统与开箱即用的高可用数据库供给方案,为用户带来极致的可观测性与丝滑的数据库使用体验。
Pigsty基于开源生态构建,旨在降低PostgreSQL使用管理的门槛,让所有人都能轻松享受到数据库的乐趣。”
**
**

01
—
概览
Pigsty创建的数据库集群是*分布式*、高可用的数据库集群。
从效果上讲,只要集群中有任意实例存活,集群就可以对外提供完整的读写服务与只读服务。数据库集群中的每个数据库实例在使用上都是幂等的,任意实例都可以通过内建负载均衡组件提供完整的读写服务。
数据库集群可以自动进行故障检测与主从切换,普通故障能在几秒到几十秒内自愈,且期间只读流量不受影响。
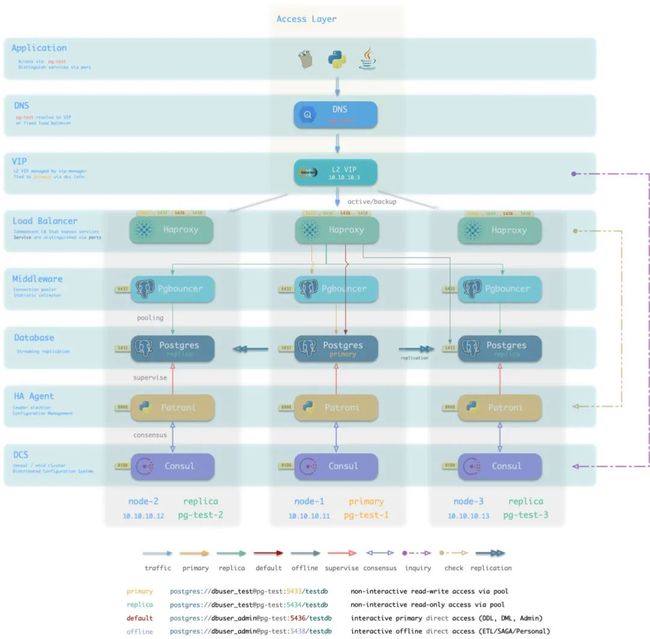
图:Pigsty数据库集群样例
一套Pigsty部署在架构上分为两个部分:
- 基础设施**(Infra)** :部署于元节点上,监控,DNS,NTP,DCS,Yum源等基础服务。
- 数据库集群**(PgSQL):部署于数据库节点上,以集群为单位对外提供数据库服务**。
所谓节点,是指用于部署的机器,物理机,虚拟机或Pod,节点分为两种:
- 元节点(Meta):部署基础设施,执行控制逻辑,每个Pigsty部署至少需要一个元节点。
- 数据库节点(Node):用于部署数据库集群/实例,节点与数据库实例一一对应。
02
—
沙箱样例
以Pigsty附带的四节点沙箱环境为例,沙箱由一个元节点与四个数据库节点组成。其中元节点也被复用为一个数据库节点。沙箱部署有一套基础设施与两套数据库集群。
meta 为元节点,部署有基础设施组件,同时部署有单主数据库集群pg-meta。
node-1,node-2,node-3 为普通数据库节点,部署有一主两从数据库集群pg-test。组件在节点上的分布如下图所示:

图:Pigsty沙箱中包含的节点与组件
下面,我们将依次介绍这几个部分:数据库节点,数据库集群,基础设施
**
**
03
—
数据库节点
数据库节点负责运行数据库实例, 在Pigsty中数据库实例固定采用独占式部署,一个节点上有且仅有一个数据库实例,因此节点与数据库实例可以互用唯一标识(IP地址与实例名)。所以下面提到数据库节点时,既可以指称数据库实例,也指称数据库实例所运行的节点。
最简单的数据库部署,就是单个PostgreSQL进程裸跑在单台机器上,实际上不少用户真的就是这么用的。玩一玩当然无所谓,但生产中这样佛系是不行的啊朋友们。
在Pigsty中,一个数据库节点,除了数据库本身还包含了一系列附属组件。
这里以一个典型的主库节点为例,一个典型数据库节点架构如下所示:
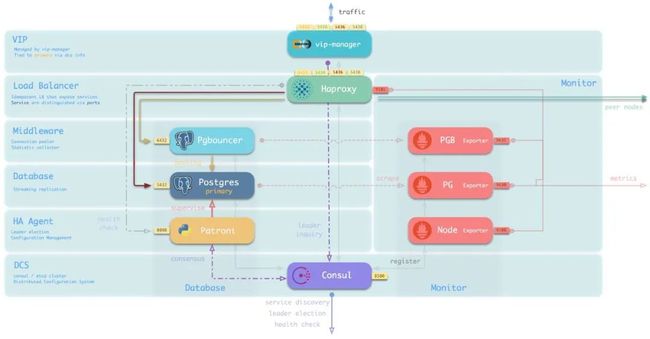
图:单个数据库节点架构
业务流量通过VIP进入主库上的负载均衡器HAProxy。HAProxy通过不同的端口将不同性质的流量(生产/离线,读写/只读)分流至具体的节点上。
典型的生产读写流量将通过Pgbouncer池化后打到对应的Postgres数据库实例上。
Postgres数据库由高可用组件Patroni管理,Patroni则依赖Consul进行状态同步与领导者选举。所有服务都会注册至Consul中。其中包括各类用于收集监控指标的Exporter。
当业务访问HAPrxoy上的只读服务时(在线 or 离线),主库上的HAProxy会将流量分发至集群中的从库节点。HAProxy会通过健康检查,从Patroni或PG Exporter获取集群成员的主从身份,完成流量分发工作。
监控基础设施中的Prometheus会从Consul获取所有数据库服务及监控组件的地址,拉取监控数据,并将监控数据与数据库实例相关联。
节点组件

组件交互
-
vip-manager通过查询Consul获取集群主库信息,将集群专用L2 VIP绑定至主库节点。 -
Haproxy是数据库流量入口,用于对外暴露服务,使用不同端口(543x)区分不同的服务。
-
- Haproxy的9101端口暴露Haproxy的内部监控指标,同时提供Admin界面控制流量。
- Haproxy 5433端口默认指向集群主库连接池6432端口
- Haproxy 5434端口默认指向集群从库连接池6432端口
- Haproxy 5436端口默认直接指向集群主库5432端口
- Haproxy 5438端口默认直接指向集群离线实例5432端口
-
Pgbouncer用于池化数据库连接,缓冲故障冲击,暴露额外指标。
-
- 生产服务(高频非交互,5433/5434)必须通过Pgbouncer访问。
- 直连服务(管理与ETL,5436/5438)必须绕开Pgbouncer直连。
-
Postgres提供实际数据库服务,通过流复制构成主从数据库集群。
-
Patroni用于监管Postgres服务,负责主从选举与切换,健康检查,配置管理。
-
- Patroni使用Consul达成共识,作为集群领导者选举的依据。
-
Consul Agent用于下发配置,接受服务注册,服务发现,提供DNS查询。
-
- 所有使用端口的进程服务都会注册至Consul中
-
PGB Exporter,PG Exporter, Node Exporter分别用于暴露数据库,连接池,节点的监控指标
04
—
数据库集群
**
**
生产环境的数据库以集群为单位进行组织,集群是一个由主从复制所关联的一组数据库实例所构成的逻辑实体。每个数据库集群是一个自组织的业务服务单元,由至少一个数据库实例组成。
下图是Pigsty沙箱中提供的测试集群pg-test架构示意图。按照集群视角进行重排并去除了次要组件。这是一个一主两从的三节点集群。通过DNS,L2VIP与HAProxy接入外部流量。
图:从数据库集群的逻辑视角审视架构
集群中的三个数据库节点在部署与使用上是完全幂等的,尽管Postgres数据库有主从之别,但这种主从区别被幂等部署的HAProxy所屏蔽。
HAProxy采用Node Port的方式对外暴露集群服务:例如从效果上说,访问任意实例的5433端口即可访问主库,访问任意实例的5434端口即可访问从库。而且只要集群一息尚存,还有任何一个节点活着,读与写服务都不会中止。这是通过Patroni自动故障切换与Haproxy自动流量切换实现的。如下图所示。
05
—
数据库接入
**
**
一个高可用方案有两个最重要的部分,主从切换与流量切换。
主从切换即集群主库发生故障时,集群可以自动选举出新的领导者来。这一点是通过Patroni与Consul保证的。
另一个重要的问题是,当集群发生主从切换后,如何将客户端的流量正确分发至正确的节点上,这一点是通过HAproxy保证的。但是HAProxy本身的可用性又如何保证?
数据库集群提供的服务边界在负载均衡HAPrxoy处止步。用户只需要确保自己可以连接到任何一个存活的集群成员HAProxy即可享受完整的数据库服务。
在上面的例子中,我们使用了一个二层VIP确保多个HAProxy实例的可用性。还有多种变体接入方案可供选择。
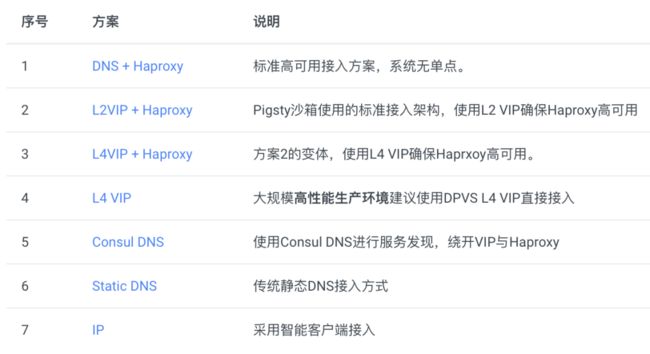
每一种方案都有自己的优势与局限性,需要用户自行权衡。
变体:DNS接入
在上面对例子中,使用了二层VIP接入HAproxy,但L2 VIP要求所有数据库实例位于同一个二层网络中。这通常意味着集群位于同一个交换机下,因此交换机反而成为了系统的单点。
使用DNS直接解析至HAProxy则不存在此问题,但流量切换无法如VIP一般快速灵敏:当某节点宕机时,客户端需要及时连接至其他健康节点,DNS使得该过程更为缓慢。DNS与客户端需要更多的工作(轮询/长连接/建连重试)才能绕过此问题。
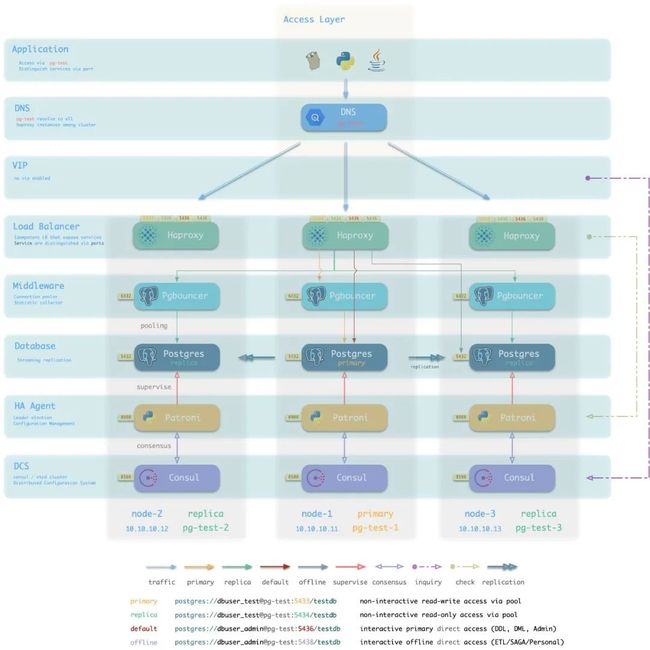
图:使用DNS接入数据库集群
变体:L4 VIP接入
一种备选项是通过L4 VIP接入。相比DNS,L4 VIP可以实时对所有HAProxy实例进行健康检测与流量分发。允许用户同时使用所有的Haproxy实例均匀承载流量。相比L2 VIP则没有同一二层网络的限制。
但L4 VIP在网络路径中又增加了额外的一跳,会降低性能与吞吐量。
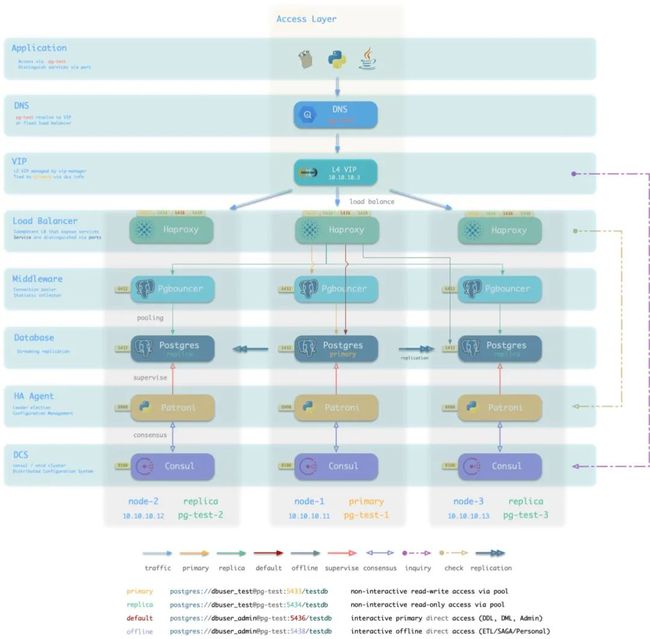
图:使用L4 VIP接入数据库集群
变体:L4 VIP直接接入
L4 VIP与HAProxy都是四层代理,L4 VIP也可以直接取代HAproxy,完成负载均衡的工作,直接将流量分发至数据库或连接池。
在生产环境中,基于DPVS集群的L4 VIP提供了更好的性能与可靠性,同时也可以通过toa模块解决传统4层负载均衡 客户端IP丢失 的问题。
当然,这种方案虽然好处很多,它对基础设施的要求会更高,实施更为复杂。同时没有Haproxy屏蔽主从差异,集群中的每个节点也不再“幂等”。

图:使用L4 VIP直接接入数据库集群
变体:自行解决
此外,用户也可以选择完全绕开HAProxy,采用传统的静态DNS方式,或Consul动态服务发现,或Consul DNS的方式来连接数据库。只要用户能自行确保连接至正确的数据库实例(读写连主库,只读连从库,在线连连接池,离线直连数据库),那么就没有问题。
例如,用户可以使用Consul服务发现寻找集群的主库,或者通过连接串中指定多个IP地址与连接属性的方式定位集群主库,或者通过传统静态DNS的方式手工维护主从信息。
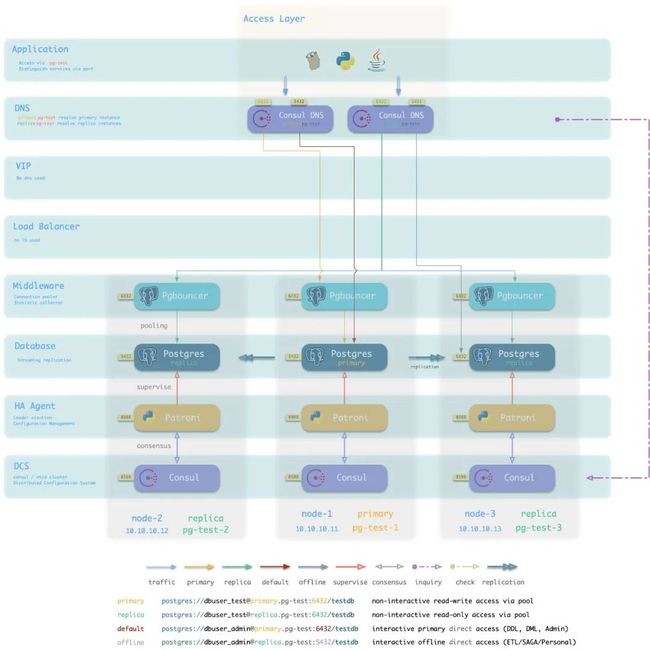
图:使用Consul DNS服务发现接入数据库集群
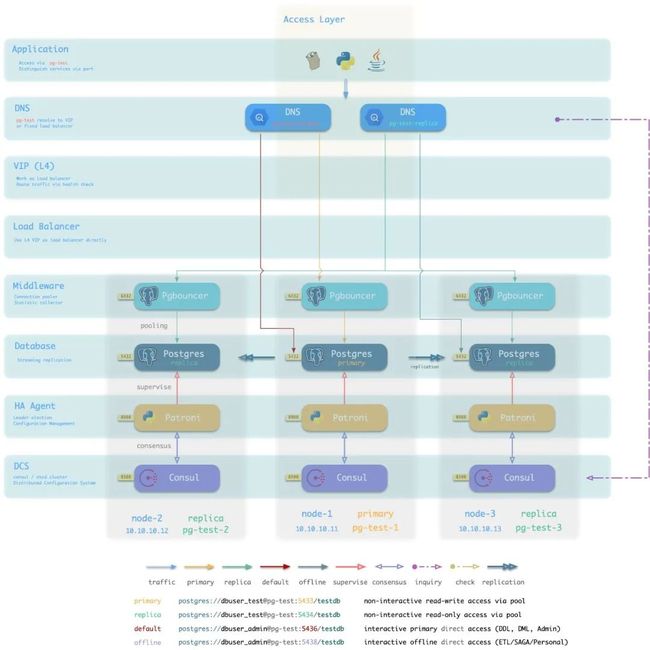
图:使用传统静态DNS接入数据库集群

图:使用IP地址直连
06
—
基础设施
介绍完数据库集群后,让我们再来看一下数据库集群赖以运行的环境 —— 基础设施。所谓基础设施,就是介于操作系统与数据库集群中间的那一部分 运行时**(Runtime)** 。
每一套 Pigsty 部署(Deployment) 中,都需要有一些基础设施,才能使整个系统正常工作。基础设施通常由专业的运维团队或云厂商负责,但Pigsty作为一个开箱即用的产品解决方案,将基本的基础设施集成至供给方案中。包括:
- 域名基础设施:Dnsmasq(部分请求转发至Consul DNS处理)
- 时间基础设施:NTP
- 监控基础设施:Prometheus
- 报警基础设施:Altermanager
- 可视化基础设施:Grafana
- 本地源基础设施:Yum/Nginx
- 分布式配置存储:Consul/etcd
- Pigsty基础设施:元数据库MetaDB,管理组件Ansible,定时任务,与其他高级特性组件。
基础设施部署于 元节点 上。每一套部署中都包含一个或多个元节点用于基础设施部署。
元节点
在每套环境中,Pigsty最少需要一个 元节点 ,该节点将作为整个环境的控制中心。元节点负责各种管理工作:保存状态,管理配置,发起任务,收集指标,等等。整个环境的基础设施组件,Nginx,Grafana,Prometheus,Alertmanager,NTP,DNS Nameserver,DCS都将部署在元节点上。
同时,元节点也将用于部署元数据库 (Consul 或 Etcd),用户也可以使用已有的外部DCS集群。如果将DCS部署至元节点上,建议在生产环境使用3个元节点,以充分保证DCS服务的可用性。DCS外的基础设施组件都将以对等副本的方式部署在所有元节点上。元节点的数量要求最少1个,推荐3个,建议不超过5个。
元节点上运行的服务如下所示:
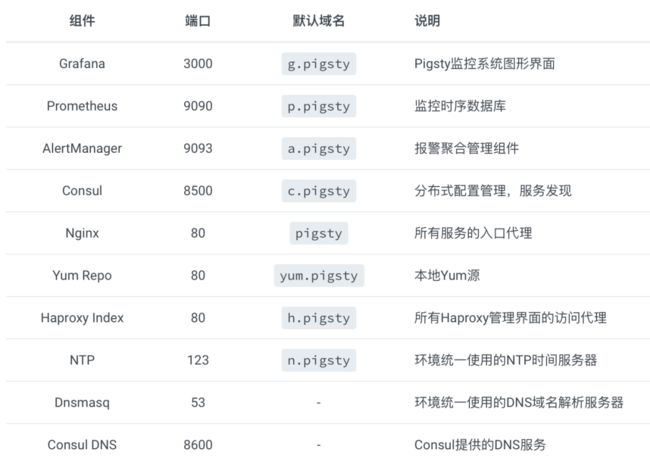
部署于元节点上的基础设置架构如下图所示:

图:部署于元节点上的基础设施组件
其主要交互关系如下:
-
Dnsmasq提供环境内的DNS解析服务(可选用已有Nameserver)
部分DNS解析将转交由Consul DNS进行
-
Nginx对外暴露所有Web服务,通过域名进行区分转发。
-
Yum Repo是Nginx的默认服务器,为环境中所有节点提供从离线安装软件的能力。
-
Grafana是Pigsty监控系统的载体,用于可视化Prometheus与CMDB中的数据。
-
Prometheus是监控用时序数据库。
-
Prometheus默认从Consul获取所有需要抓取的Exporter,并为其关联身份信息。
-
Prometheus从Exporter拉取监控指标数据,进行预计算加工后存入自己的TSDB中。
-
Prometheus计算报警规则,将报警事件发往Alertmanager处理。
-
Consul Server用于保存DCS的状态,达成共识,服务元数据查询。
-
NTP服务用于同步环境内所有节点的时间(可选用已有NTP服务器)
-
Pigsty相关组件:
-
- 用于执行剧本,发起控制的Ansible
- 用于支持各种高级功能的MetaDB(也是一个标准的数据库集群)
- 定时任务控制器(备份,清理,统计,巡检,高级特性暂未加入)
基础设施与数据库的关系
以单个 元节点 和 单个 数据库节点 构成的环境为例,架构如下图所示:

图:基础设施与数据库节点
元节点与数据库节点之间的交互主要包括:
-
数据库集群/节点的域名依赖元节点的Nameserver进行解析。
-
数据库节点软件安装需要用到元节点上的Yum Repo。
-
数据库集群/节点的监控指标会被元节点的Prometheus收集。
-
Pigsty会从元节点上发起对数据库节点的管理
执行集群创建,扩缩容,用户、服务、HBA修改;日志收集、垃圾清理,备份,巡检等
-
数据库节点的Consul会向元节点的DCS同步本地注册的服务,并代理状态读写操作。
-
数据库节点会从元节点(或其他NTP服务器)同步时间
07
—
如何拥有?
介绍完Pigsty中高可用数据库集群的架构之后,让我们回到用户最关心的问题上来。如何拥有这样一套生产级数据库集群方案?
负责任的开发者不应该装完逼就跑,只讲自己多牛逼,不给别人解决实际问题。
Pigsty是开源免费(您想赞助掏钱我举双手资瓷!)的数据库供给方案。在Pigsty中拥有这样的数据库集群,只需要两步:
首先准备好机器,填入集群基本信息(IP地址,集群名,实例编号,实例角色)

然后运行剧本,一键拉起
./pgsql.yml -l pg-test
实际上,不仅仅是数据库集群,整个基础设施与所有数据库集群都可以通过这样的命令一键拉起,而且还附带有开箱即用的顶级PostgreSQL****监控系统。


详细的文档,可以参考这里:https://pigsty.cc