python中pandas库的使用(excel读取)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、pandas是什么?
- 二、使用步骤
-
- 1.引入库
- 2.读取数据
-
- loc和iloc方法:
-
- loc方法提取:
- iloc方法:
- 通过某一字段筛选数据
-
- 1. 通过某一列中数据初步筛选
- 2.只选择其中一列或几列
- 3.获取表单数据行数
- 4.获取表单中某一列或行中数据的长度
- 5. 通过数据长度筛选数据
-
- 1.属于
- 2.不属于
- 3.数据转换
-
- 1. DataFrom转字典
- 2 . 字典转DataFrom
- 4.写入数据
-
- 1.更改DataFrame数据
- 2 . 写入excel中
- openpyxl使用(指定excel指定位置插入数据)
-
- 复制原来的文件
- 打开新生成的文件
- 写入数据
- 插入图片
- 保存数据直接覆盖原数据
- 5、处理重复数据
- 三、后缀是xls文件的输入追加方式
-
- 1.打开已保存文件
- 2.写入
- 总结
前言
提示:以下是本篇文章正文内容,下面案例可供参考
一、pandas是什么?
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
二、使用步骤
1.引入库
代码如下(示例):
import pandas as pd
2.读取数据
数据结构

# 读取excel文件内容
def read(file_path):
data_from = pd.read_excel(io=file_path,sheet_name='Sheet1',keep_default_na=False,dtype=str,engine='openpyxl')
print(data_from) #输出的是一个DataFrom表单
参数解析
- io : 文件路径
- sheet_name : excel文件那一个 sheet
- keep_default_na=False : 空值的NaN不显示
- dtype : 设置数据类型,不设置有时候开头是0的数据不读取
- engine : 指定驱动
loc和iloc方法:
区别:
loc函数:通过行索引 “Index” 中的具体值来取行数据
iloc函数:通过行号来取行数据
获取行时写法差不多,
loc方法提取:
ps : data_from.iloc[初始行:结束行,初始列:结束列]
loc方法是通过行、列的名称或者标签来寻找我们需要的值。
1.获取某一行,会带着标题行
data_from.loc[1]
2。获取某一列,通过列名
data_from.loc[:,'列名]
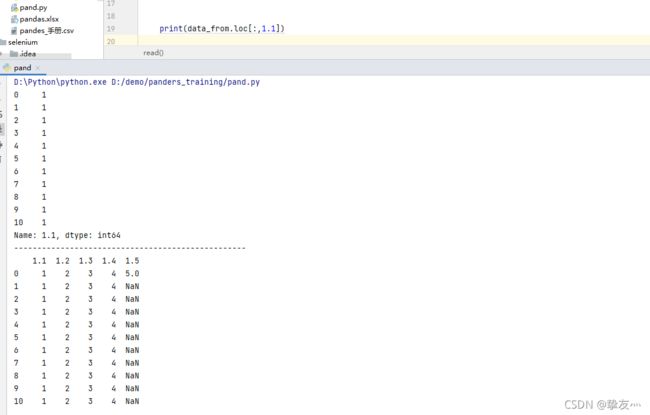
3.获取全部数控
data_from.iloc[:,:]
4.获取第一到第二列
data_from.loc[:,1.1:1.2]
iloc方法:
1.获取第一行,和loc方法写法一样
data_from.iloc[1]
2.获取第一列,通过index
data_from.iloc[:,0]
3.获取全部数控
data_from.iloc[:,:]
4.获取第一到第二列
data_from.iloc[:,1:2]
通过某一字段筛选数据
1. 通过某一列中数据初步筛选
df=data_from[data_from['船公司']=='COSCO']
2.只选择其中一列或几列
number = df.iloc[:,0]
goal = df.iloc[:,10]
3.获取表单数据行数
data_from.shape[0] # data_from 是表单数据
4.获取表单中某一列或行中数据的长度
goal = df.iloc[:,10].str.len() # str.len() 获取字符串长度
5. 通过数据长度筛选数据
1.属于
data = [11,14]
# 属于data的 ,data是可迭代数据
data_frome_no_length = df[df.iloc[:, 0].str.len().isin(data )]
# 获取筛选后数据行数
if data_frome_no_length.shape[0] != 0:
pass
2.不属于
data = [11,14]
data_frome_no_length = df[~df.iloc[:, 0].str.len().isin(data)]
if data_frome_no_length.shape[0] != 0:
pass
3.数据转换
1. DataFrom转字典
转换数据可以通过下标取出对应列数据
data_dic = data_from.to_dict(orient='index')
也可以通过列名
data_dic =data_from.to_dict('records')
2 . 字典转DataFrom
pd.DataFrame(data_dic)
4.写入数据
1.更改DataFrame数据
#循环遍历每一行
count = 1
for i in data_dic:
if i[1.5] is None or i[1.5] == '':
i[1.5] = 5
# continue
else:
# print(i)
i[1.5] = 5
print(data_dic)
2 . 写入excel中
实现步骤:
字典数据转DataFrame
这里 df 是 DataFrame简称
df = pd.DataFrame(data_dic)
df.to_excel('./cs.xlsx')
### 单列数据由转list DataFrame中的单列数据是pandas.core.series.Series,通过下标进行循环提取时可能数据不全,这里是转换成list
type(number) #输出pandas.core.series.Series
number = number.values.tolist() #转换之后就是list类型数据
openpyxl使用(指定excel指定位置插入数据)
复制原来的文件
shutil.copy(old_file_name, new_file_path)
打开新生成的文件
wb = openpyxl.load_workbook(new_file_path)
ws = wb['Sheet1'] # 第一个Sheet页
写入数据
ws.cell(row=5, column=15).value = ’测试‘
插入图片
img = Image(r'D:\ZJGL\img.png') # 选择你的图片
ws.add_image(img, 'G47')
保存数据直接覆盖原数据
wb.save(new_file_path)
5、处理重复数据
-
标记重复记录下标
df2= df.loc[df.duplicated(subset=['取证链接', '敏感内容', '正确表述', '报告类型', '目标名称']), '办公地址'] = 'true'- 解释:
- df2 = df.loc[行索引, 列名] = ‘指定值’
- df.duplicated(subset=[‘字段1’,‘字段2’])
- subset: 对比字段
- keep:
- ‘last’:保留最后一个重复数据
- ‘first’: 保留第一个重复数据
- Flast : 重复值是标记True
- df.loc[] : [行索引, 列名]
- 通过索引行(True的那一行)更改字段value
-
去除重复数据
df.drop_duplicates(subset=['取证链接', '敏感内容', '正确表述', '报告类型', '目标名称'], keep=False, inplace=True)- 解释: subset与keep上同
- inplace : 是否对数据集本身进行修改,默认False , 覆盖就用True
三、后缀是xls文件的输入追加方式
1.打开已保存文件
file_path = '.xls文件路径'
rb = open_workbook(file_path,formatting_info=True) # formatting_info=True 保留格式
r_sheet = rb.sheet_by_index(0) # 切换到第一个Sheet 页面
wb = copy(rb) # 复制file_path路径的文件
w_sheet = wb.get_sheet(0) # 写入的页(Sheet)
2.写入
w_sheet.write(row_index, col_summer1, 'data')
w_sheet.write(row, line, ‘data’) , 行和列都从0开始
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。