ConvNeXt
ConvNeXt
研究思路
基于ResNet50进行改进,使用VIT的策略去训练原始的原始的ResNet50模型
1宏观设计
改变模型比例,
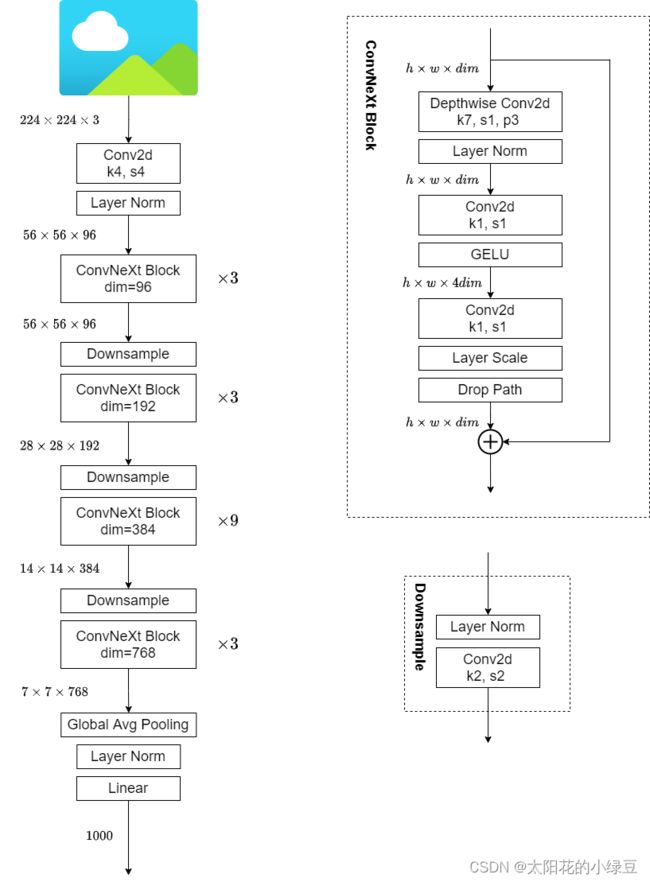
ResNet50中stage1到stage4堆叠block的次数是(3, 4, 6, 3)比例大概是1:1:2:1,调整成(3, 3, 9, 3)和Swin-T拥有相似的计算速度(FLOPs),准确率由78.8%提升到了79.4%。
改变stem为patchify
作者将ResNet中的stem也换成了和Swin Transformer一样的patchify。替换后准确率从79.4% 提升到79.5%,并且FLOPs也降低了一点。
stem:通过一个卷积核大小为7x7步距为2的卷积层以及一个步距为2的最大池化下采样共同组成,高和宽都下采样4倍。
patchify:卷积核大小为4x4步距为4的卷积层构成,同样是下采样4倍。
2采用depthwise convolution
作者采用更激进的depthwise convolution,将最初的通道数由64调整成96和Swin Transformer保持一致,最终准确率达到了80.5%
depthwise convolution:每个卷积核的channel都是等于1,只负责输入特征矩阵的一个channel,故卷积核的个数必须等于输入特征矩阵的channel数,从而使得输出特征矩阵的channel数也等于输入特征矩阵的channel数。
3倒置Bottleneck
作者认为Transformer block中的MLP模块非常像MobileNetV2中的Inverted Bottleneck模块,即两头细中间粗。采用Inverted Bottleneck模块后,在较小的模型上准确率由80.5%提升到了80.6%,在较大的模型上准确率由81.9%提升到82.6%。

a是ReNet中采用的Bottleneck模块,b是MobileNetV2采用的Inverted Botleneck模块(图b的最后一个1x1的卷积层画错了,应该是384->96,后面如果作者发现后应该会修正过来),c是ConvNeXt采用的是Inverted Bottleneck模块。
4大卷积核
上移深度卷积层
将depthwise conv模块上移,原来是1x1 conv -> depthwise conv -> 1x1 conv,
现在变成了depthwise conv -> 1x1 conv -> 1x1 conv。
这样改动后,准确率下降到了79.9%,同时FLOPs也减小了
增大卷积核尺寸
将depthwise conv的卷积核大小由3x3改成了7x7(和Swin Transformer一样),当然作者也尝试了其他尺寸,包括3, 5, 7, 9, 11发现取到7时准确率就达到了饱和。并且准确率从79.9% (3×3) 增长到 80.6% (7×7)。
5微观设计
Replacing ReLU with GELU
作者又将激活函数替换成了GELU,替换后发现准确率没变化。
使用更少的激活函数,
在ConvNeXt Block中也减少激活函数的使用,如下图所示,减少后发现准确率从80.6%增长到81.3%。
更少使用 normalization layers
只保留了depthwise conv后的Normalization层,此时准确率已经达到了81.4%,已经超过了Swin-T
将BN替换成LN
作者将BN全部替换成了LN,发现准确率还有小幅提升达到了81.5%
单独的下采样层
作者就为ConvNext网络单独使用了一个下采样层,就是通过一个Laryer Normalization加上一个卷积核大小为2步距为2的卷积层构成。更改后准确率就提升到了82.0%。
代码
作为backbone
import torchvision
from torchvision.models.feature_extraction import create_feature_extractor
backbone = modle.convnext_tiny(num_classes= 5)
print(backbone)
backbone = create_feature_extractor(backbone, return_nodes={"stages.2": "0"})
out = backbone(torch.rand(1, 3, 224, 224))
print(out["0"].shape)
backbone.out_channels = 384