Python爬虫 | 教你怎么用正则表达式~
网页上的信息爬下来之后,关键的一步就是对目标信息进行提取;
解析方法通常会用到正则表达式,可以方便的提取网页里非结构化的数据。
网络爬虫中用的较多的正则表达式有:
-
.:匹配任意一个字符,换行\n除外
-
*:匹配前一个字符0次或无限次
-
?:匹配前一个字符0次或者一次
-
.*:贪心算法
-
.*?:非贪心算法
-
() 内的数据作为结果输出
![]()
一、基本知识
概 念
是对字符串操作的⼀种逻辑公式;
利用事先定义好的⼀些特定字符及这些特定字符的组合,组成⼀个“规则字符串”。
这个“规则字符串”⽤来表达对字符串的⼀种过滤逻辑;
-
优点:可以精准的爬取我们想要的数据信息;
-
缺点:爬取的速度会很慢,时间就会变得很长,就容易被反爬虫,封ip;
表达式组成
正则表达式由字符集[...]、量词(* + ?{ })、边界(^ $)、逻辑( | )、re模块的函数五部分组成。
一个字符集(\d \w 这些也属于字符集,它们不需要用 [ ] 包裹 )不论有多复杂,在没有量词的情况下,只代表一个字符。
常用规则
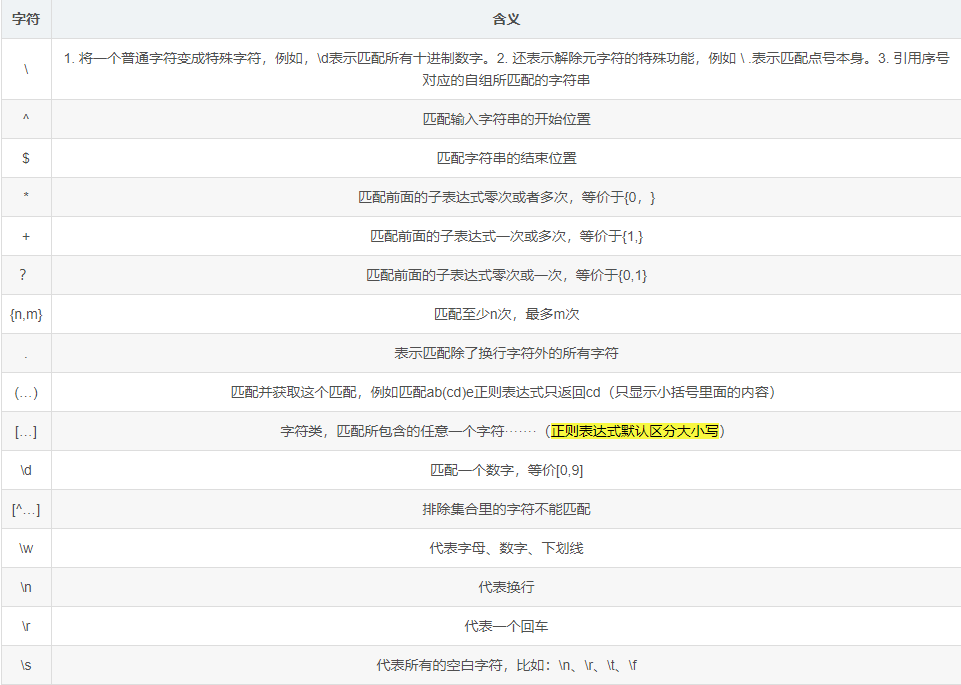
元字符:是构造正则表达式的一种基本元素;
重复限定符:为了处理一堆连七八糟而且重复的问题;
利用正则表达四中一些重复限定符,把重复部分用合适的限定符代替。
分 组
Python的re模块有⼀个分组功能,所谓的分组就是去已经匹配到的内容再筛选出需要的内容,相当于⼆次过滤。
实现分组靠圆括号(),⽽获取分组的内容靠的是group()、groups()。
转 义
如果要匹配的字符串中本身就包含小括号的情况,正则表达式提供了转义的方式。
也就是要把这些元字符、限定符或者关键字转义成普通的字符,在转义的字符前加个“\”即可。
注意区分“\”与“/”的区别;
条件 或
正则用符号|来表示或,也叫做分支条件,当满足正则里的分支条件的任何一种条件时,都会当成是匹配成功。
如例:
![]()
区 间
正则提供一个元字符中括号[ ] 来表示区间条件;
如例:
限定0到9 可以写成 [0-9]
限定A-Z 写成 [A-Z]
限定某些数字 [165]
![]()
小 结
① 正则表达式只能处理字符串,用于模糊匹配;
② 正则表达式的区间是闭区间;
③ 正则表达式的匹配方式:正则项 被包含于 字符串 时均可匹配 , 可以用 ^ $ 来具体匹配正则项;
④ python需要插入 re 模块才能使用正则表达式
最近整理了一套编程学习资料分享给大家,全是干货内容,包含教程视频、电子书、源码笔记、学习路线图、实战项目、面试题等等,关注gzh【Python编程学习圈】就能免费获取,回复关键词【学习资料】即可,抓紧时间吧!
匹配IP地址
匹配IP地址的正则表达式
IP地址由4断组成,每段0-255,由’.'分割,如210.134.3.123
第一步:\d+.\d+.\d+.\d+,不考虑长度
第二步:\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}考虑了长度
第三步:分割
0-99:[1-9]?\d
100-199:1\d{2}
200-249:2[0-4]\d
250-255:25[0-5]
组合:
(([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5]).){3}([1-9]?\d|1\d{2}|2[0-4]\d|25[0-5])
可选标志
用于控制正则表达式的匹配方式;
正则表达式可以包含一些可选标志修饰符来控制匹配的模式,修饰符被指定为一个可选的标志。
多个标志可以通过按位 OR(|) 它们来指定,如 re.I | re.M 被设置成 I 和 M 标志:
re.S:使 . 匹配包括换行在内的所有字符;
re.I:使匹配对大小写不敏感;
re.L:做本地化识别(locale-aware)匹配;
re.M:多行匹配,影响 ^ 和 $;
re.U:根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B;
re.X:该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。![]()
二、Re库的基本使用
在Python中使用正则需要引入re模块,包含了正则表达式的所有功能,这一块的学习是掌握爬虫解析重要的一步之一。
了解完基础知识之后,就可以顺着建立的学习路径,一路升级打怪。
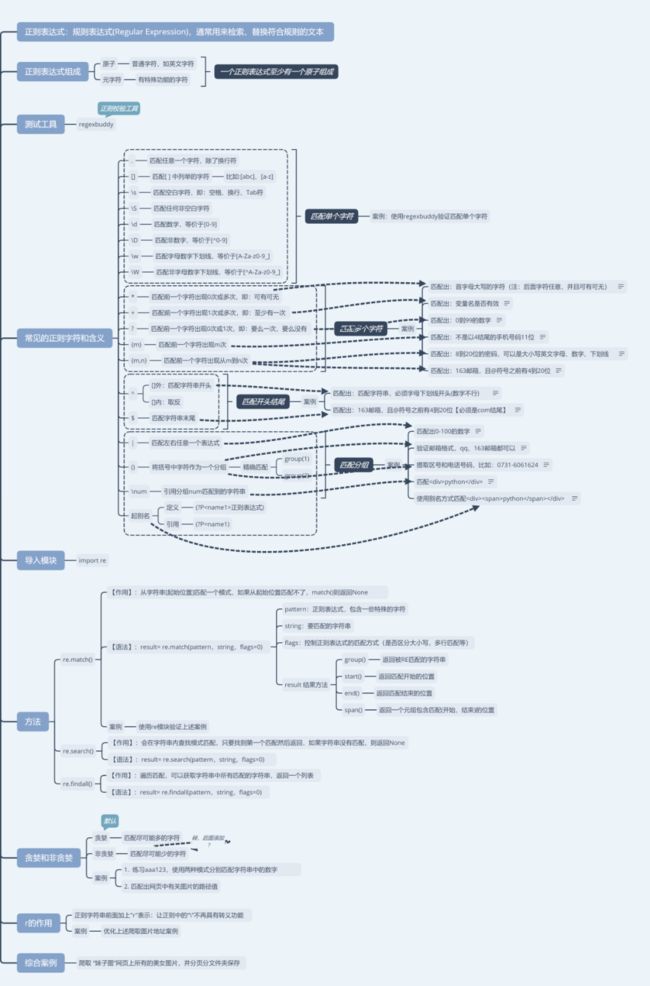
基本介绍
Re库是Python的标准库,主要用于字符串匹配。
re库使用raw string(原生字符串类型)表示,表示为r’text’,例如邮政编码表示为r’[1-9]\d{5}’。
原生字符串是不包括转义字符的字符串,只需要在字符串前面加上r就可以了。
其实也可以使用string类型表示正则表达式,但是string中把\作为转义字符,所以表示会更加繁琐。
主要功能函数
匹配的方法有:.findall()、.seach()、.match()
需要注意它们的区别;

compile函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象,该对象拥有一系列方法用于正则表达式匹配和替换。
re.match() 方法
re.match() 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 None。
re.match(pattern,string,flags=0)参数说明:
-
pattern 匹配的正则表达式;
-
string 要匹配的字符串;
-
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等;
常用的flags如下:

re.match() 方法若匹配成功,返回一个匹配的对象,否则返回 None。
可以用 group(num) 或 groups() 匹配对象函数来获取匹配表达式;
匹配对象方法如下:
group(num=0):
groups():返回一个包含所有小组字符串的元组,从1到所含的小组号。
match对象的属性:
(1)string属性
获取匹配时使用的字符串对象
(2)re属性
匹配时使用的pattern对象,也就是匹配到内容的正则表达式对象
(3)pos属性
该属性表示文本中正则表达式开始搜索的索引;
值与Pattern.match()和Pattern.seach()方法中的同名参数相同。
(4)endpos属性
表示文本中正则表达式结束搜索的索引;
值与Pattern.match()和 Pattern.seach()方法中的同名参数相同。
(5)lastindex属性
表示最后一个被捕获的分组在文本中的索引;
如果没有被捕获的分组,将为None
(6)lastgroup属性
表示最后一个被捕获的分组别名。如果这个分 组没有别名或者没有被捕获的分组,将为None。
match对象的常用方法:
re.search() 方法
re.search() 方法扫描整个字符串并返回第一个成功的匹配;
re.search(pattern,string,flags=0)参数说明:
-
pattern 匹配的正则表达式;
-
string 要匹配的字符串;
-
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等;
同样可以用 group(num) 或 groups() 匹配对象函数来获取匹配表达式。
3)re.match() 与 re.search() 的区别
-
re.match() 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None。
-
re.search() 匹配整个字符串,直到找到一个匹配。
例子示例:
import re
print(re.match('super', 'superstition').span())输出:(0, 5)
print(re.match('super','insuperable'))输出:None
print(re.search('super','superstition').span())输出:(0, 5)
print(re.search('super','insuperable').span())输出:(2, 7)
最小匹配
re库的贪婪匹配和最小匹配
如例:match = re.search(r'PY.*N','PYANBNCNDN')
对于这个匹配形式,有多个字符串满足这种匹配形式,re默认使用贪婪匹配,即输出匹配最长的子串,即输出PYANBNCNDN。
怎么输出最短的子串?,增加一个?就可以对操作符进行扩展,实现最小匹配;
示例:match = re.search(r'PY.*?N','PYANBNCNDN')
最小匹配在贪婪匹配的基础上进行了扩展,也就是说re库中,如果你想要得到最小匹配,你需要对操作符进行扩展。
即常见的四种:

![]()
三、关于匹配为空的问题
怎么处理Python爬虫正则表达式匹配为空的问题?
在用正则表达式匹配网址信息的时候,有时候会匹配到空的列表,有可能会是以下几种情况:
1)选取正则表达式的方式不对
不太建议在网页上按F12,然后选中自己想爬的内容;
直接写正则表达式,因为网页的源代码和返回给我们请求的html是不一样的。
源代码里会夹杂着一些隐含符,/n或者/r/n…要是没有这些隐含符就会导致匹配到空的字符串。
解决方法:在def_analysis(self,htmls):里设置断点,然后进行调试
2)爬取的内容是动态的
你爬取的内容是动态的,返回的html里没有相应的信息。
例如京东的价格,评论等,这样就不能用正则表达式来匹配,需要从接口里爬取。
3)如果以上两种可能性都没有
可能是你爬取的网址反爬虫十分强大,不让你爬,可以试试更换ip地址。
总结:
文章总结了爬虫的用的频率较高的正则表达式中的一些基本使用方法,对于网络爬虫来说,重要的是要能从网页中提取信息。