【Pandas】DataFrame排序 sort_index // sort_values
DataFrame排序和修改索引
- 构造数据
- 按索引排序(sort_index)
-
- 行索引排序
- 列索引排序
- 参数key的用法
- 按数据排序(sort_values)
-
- 给一组数据排序
- 给多组数据排序
- 给多组数据进行不同排序
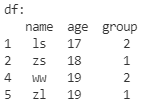
构造数据
df = pd.DataFrame(
data=[
['zs', 18, 1],
['ls', 17, 2],
['ww', 19, 2],
['zl', 19, 1]
],
columns=['name', 'age', 'group'],
index=[2, 1, 4, 5]
)
print('df:\n', df)
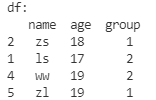
按索引排序(sort_index)
行索引排序
df.sort_index(
ascending=True, # ascending=True --升序排序(默认); ascending=False --降序排序
inplace=True, # 如果为True,则直接删除,对原df进行操作; 如果为False(默认),那么返回一个结果,不会对原df操作!
axis=0, # axis=0 --根据行索引排序(默认); axis=1 --根据列索引排序
key=None # (默认)None,否则在排序之前对索引值应用键函数。
)
print('df:\n', df)
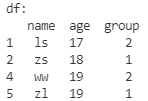
列索引排序
df.sort_index(
ascending=True, # ascending=True --升序排序(默认); ascending=False --降序排序
inplace=True, # 如果为True,则直接删除,对原df进行操作; 如果为False(默认),那么返回一个结果,不会对原df操作!
axis=1, # axis=0 --根据行索引排序(默认); axis=1 --根据列索引排序
)
print('df:\n', df)
上述排序是根据字符串的排序方式进行的
参数key的用法
>>> df = pd.DataFrame({"a": [1, 2, 3, 4]}, index=['A', 'b', 'C', 'd'])
>>> df.sort_index()
a
A 1
C 3
b 2
d 4
>>> df.sort_index(key=lambda x: x.str.lower())
a
A 1
b 2
C 3
d 4
"""
按数据排序(sort_values)
sort_values 和 sort_index 参数相似,区别是多出一个by参数指定用来排序的行 或 列,by的值可以是字符串或数组。
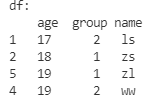
给一组数据排序
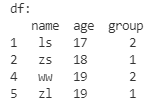
根据age排序
df.sort_values(
by='age',
ascending=True,
inplace=True
)
print('df:\n', df)
给多组数据排序
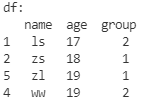
先根据age排序,age相同的数据再根据group排序
df.sort_values(
by=['age', 'group'],
ascending=True,
inplace=True
)
print('df:\n', df)
给多组数据进行不同排序
先根据age升序排序,age相同的数据再根据group降序排序
df.sort_values(
by=['age', 'group'],
ascending=[True, False],
inplace=True
)
print('df:\n', df)