核心系统国产平台迁移验证
核心系统国产平台迁移验证
摘要:信息技术应用创新,旨在实现信息技术领域的自主可控,保障国家信息安全。金融领域又是关系国家经济命脉的行业,而对核心交易系统的信息技术应用创新是交易所未来将要面临的重大挑战。为了推进国产化进程,选取核心交易系统的典型模块,实践了基于鲲鹏平台的迁移验证,在各技术栈迁移流程方法、性能调优、典型问题等方面,做了大量的探索与尝试。
一、背景
信息技术应用创新,旨在实现信息技术领域的自主可控,保障国家信息安全。目前,信创产业蓬勃发展,未来将会形成一条庞大的产业链,主要包括:基础设施(CPU、服务器、存储、交换机等),基础软件(操作系统、数据库、中间件等),以及应用软件和信息安全产品等。
金融领域又是关系国家经济命脉的行业,加速推进核心交易系统的信息技术应用创新势在必行。通过选取核心交易系统部分典型模块作为信创试点,基于鲲鹏平台进行迁移验证,在各技术栈迁移流程方法、性能调优、典型问题等方面,做了大量的探索与尝试,为实现核心交易系统的全面信创改造筑牢技术基础。
二、引言
此次迁移过程是将核心交易系统中某一系列典型的业务功能模块(M模块,C模块、S模块)进行剥离,使其能够独立运行在信创平台上,并可以与核心交易系统进行实时通信,以实现完整的业务处理流程,形成独立运行的业务系统(简称:典型业务信创系统)。选取场景从技术栈的角度尽量覆盖核心交易系统中的大部分应用场景,开发语言以C++为主,同时涵盖了JAVA,GOLANG,汇编(C内嵌)等。中间件采用Kafka,Zookeeper,以及相关开源第三方项目:Protobuf,librdkafka,otlv4等。
验证环境(基础设施,基础软件)包括:TaiShan 200服务器搭载鲲鹏920处理器,麒麟操作系统Kylin-v10,达梦数据库DM8。后文将详细介绍各技术栈迁移流程、方法、典型问题以及注意事项等。
三、典型业务信创系统技术架构
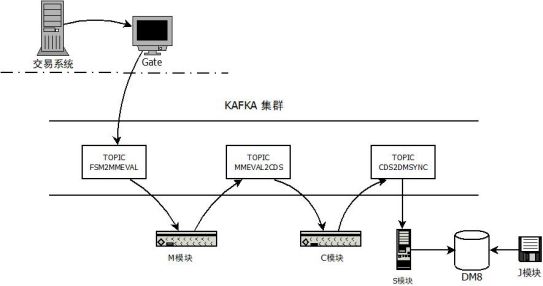
::: hljs-center
图1 系统架构图
:::
典型业务信创系统以Kafka集群作为消息中间件,交易系统数据通过网关Gate与典型业务信创系统交互,M模块处理业务逻辑;C模块负责数据格式转换;S模块业务数据同步至达梦数据库;J工具为Java数据抽取工具,抽取达梦数据库中作为系统启动的初始化数据。
四、系统迁移
(一)环境准备
基础设施:TaiShan 200服务器搭载鲲鹏920处理器。鲲鹏处理器基于ARM架构,有别于Intel、AMD CPU采用CISC复杂指令集(Complex Instruction Set Computers,复杂指令集计算机),ARM CPU 采用RISC精简指令集(Reduced Instruction Set Computers,精简指令集计算机)。
| x86 | ARM | |
|---|---|---|
| 指令集 | CISC | RISC |
| 供应商 | 主要有intel和AMD,intel处于垄断地位 | 开放的授权策略,众多供应商 |
| 产业链 | 成熟 | 快速发展中 |
鲲鹏处理器架构(ARM)特点:
优点:
1. 低功耗、集成度高,更多的硬件CPU核,具备更好的并发性能;
2. 支持64位指令集,能很好的兼容,从IOT、终端到云端的各类应用场景;
3. 大量使用寄存器,大多数数据操作都在寄存器中完成,指令执行速度更快;
4. 采用RISC指令集,指令长度固定,寻址方式灵活简单,执行效率高;
缺点:
1. 刚刚起步,其生态处于快速发展阶段;
2. CPU主频相对较低,对于某些应用场景限制了性能;
基础软件:麒麟操作系统Kylin v10,达梦数据库DM8;
鲲鹏工具链:鲲鹏代码迁移工具、鲲鹏性能分析工具;
其他依赖列表:
| 名称 | 版本 |
|---|---|
| otlv4 | v4 |
| tinyxml/tinyxml2 | v1/v2 |
| zookeeper | v3.7.0 |
| kafka | v2.7.1 |
| openjdk | v1.8 |
| Bisheng jdk | v1.8 |
| gcc/g++ | v7.3.0 v9.3.1(kunpeng定制) |
| make/cmake | V3.12.1 |
| librdkafka | v1.7.0 |
| golang | v1.16.5 |
| shell | v5.0.17 |
(二)编译迁移
典型业务信创系统包括编译类代码(C/C++/Go)和解释类代码(Java)。
1. C/C++代码迁移
麒麟Kylin v10默认GCC编译器版本为v7.3.0,同时华为鲲鹏还提供了两款定制的C/C++编译器,分别是:gcc-9.3.1-2021.03-aarch64-linux(Kunpeng gcc 1.3.2.b023)和基于llvm的毕昇编译器(bisheng-compiler-1.3.1-aarch64-linux),本次迁移分别采用了v7.3.0和v9.3.1(Kunpeng 1.3.2)两个版本的GCC编译器进行编译。
1)编译
由于CPU架构的差异编译时需要调整和增加以下编译选项。
| x86 | ARM | 说明 |
|---|---|---|
| -m64 | -mabi=lp64 | -m64是x86 64位应用编译选项,m64选项设置int为32bits及long、指针为64 bits,为AMD的x86 64架构生成代码。在ARM64平台无法支持。 |
| -fsigned-char | char变量在不同CPU架构下默认符号不一致,在x86架构下为signed char,在ARM64平台为unsigned char,移植时需要指定char变量为signed char。 | |
| -march=armv8-a | 在编译时增加编译选项指定处理器架构为Armv8,使编译器按照鲲鹏处理器的微架构和指令集生成可执行程序,提升性能。 | |
| -mtune=tsv110 | 如果使用了gcc 9.1以上的版本在编译时增加编译选项指定使用tsv110流水线 ,使编译器按照鲲鹏处理器的流水线编排指令执行顺序,充分利用流水线的指令级并行,提升性能。 |
2)内存屏障
现代CPU被设计成在从内存中获取数据的同时,可以执行其他指令和内存引用,这就导致了指令和内存引用的乱序执行。为了解决这一内存乱序问题,引入了各种同步原语,这些原语通过使用内存屏障来实现多处理器之间内存访问的顺序一致性。然而内存模型在不同架构下存在着差异,x86下为强内存序,而ARM则为弱内存序。下表列出x86与鲲鹏架构之间的内存序差异:
| 内存乱序行为 | x86 | arm |
|---|---|---|
| 读-读乱序 | 不允许 | 允许 |
| 读-写乱序 | 不允许 | 允许 |
| 写-读乱序 | 允许 | 允许 |
| 写-写乱序 | 不允许 | 允许 |
| 原子操作-读写乱序 | 不允许 | 允许 |
x86和ARM的汇编指令是不同的,因此原有代码中使用的嵌入式汇编需要修改,cpu内存屏障指令移植方案如下:
| x86 | arm | 说明 |
|---|---|---|
| __asm__ __volatile__(“sfence” : : : “memory”); | __asm__ __volatile__(“dmb ishst” : : : “memory”); | 前后的写入(store/release)指令 |
| __asm__ __volatile__(“lfence” : : : “memory”); | __asm__ __volatile__(“dmb ishld” : : : “memory”); | 前后的读取(load/acquire)指令 |
| __asm__ __volatile__(“mfence” : : : “memory”); | __asm__ __volatile__(“dmb ish” : : : “memory”); | 之前的写入(store/release)指令 |
在程序编译的时候,特别是加入了优化选项-O2或-O3之后,编译器可能会将代码打乱顺序执行,即编译生成后的汇编代码的执行顺序可能与原始的高级语言代码中的执行顺序不一致。所以编译器提供了编译阶段的内存屏障,用于指导编译器及时刷新寄存器的值到内存中,保证该编译器屏障前后的内存访问指令在编译后是定序排布的。常见的编译型屏障定义如下所示:
#define barrier() __asm__ __volatile__(“”: : :“memory”)
x86属于强内存序架构,大部分情况使用编译型屏障或者volatile访问(c++ 标准不建议用于跨线程变量)就可以保证多线程内存访问的一致性。但是,在arm架构下就无法保证这一点。需要修改为对应的cpu内存屏障,必要的时候增加cpu内存屏障。为了支持跨平台,要么使用预编译条件,要么引入C++ 11的内存屏障原语。引入C++ 11内存屏障原语提高了可移植性,增加了可读性,选为最终方案。
相比ARMv7,ARMv8增加了load-acquire(LDLARB,LDLARH和LDLAR)和store-release(STLLRB,STLLRH和STLLR)指令,这可以直接支持c++原子库中的相关语义。这些指令可以理解成半屏障。这些半屏障指令的执行效率要比全屏障更高,所以在能够使用这种类型的屏障时,我们尽可能使用acquire和release语义来做线程间的同步。Read-Acquire用于修饰内存读取指令,一条 read-acquire的读指令会禁止它后面的内存操作指令被提前执行,即后续内存操作指令重排时无法向上越过屏障。Write-Release用于修饰内存写指令,一条Write-Release的写指令会禁止它上面的内存操作指令被乱序到写指令完成后才执行,即写指令之前的内存操作指令重排时不会向下越过屏障。
通过统一使用标准库的atomic_thread_fence以及acquire-release语义,简化了跨平台代码的实现。编译器会在arm平台替换为合适的指令,而在x86下则精简为普通变量访问。x86下测试表明,使用标准库的实现相比汇编实现,性能降低幅度在5%以内,在arm上也有较好的性能表现。
2. Go代码迁移
Go与C++类似,同为编译型语言,需要在不同CPU架构上安装对应的编译器。使用Go编译器版本为go1.16.5 linux/arm64。项目中未使用嵌入式汇编,因此在编译器成功安装后,Go工程目录下执行go install即可编译通过。
3. JAVA代码迁移
JAVA应用是运行在JVM(java虚拟机)上的解释性语言,迁移过程如下:
1)安装鲲鹏或ARM版本jdk,可以使用OpenJDK也可以使用鲲鹏提供的毕昇JDK,这里我们对两个版本的JDK分别做了尝试。
2)配置JDK环境
3)替换依赖jar包匹配鲲鹏或ARM架构(手动或maven)
4)重新打包Java应用
4. Shell代码迁移
Bash从4.2版本升级到5.0版本,修复了很多BUG,但也存在一些旧语法在新版本上无法运行,需要进行适当的调整,例如:
二维数组ids=${temp[2][@]}这种语法在4.2上是可以运行的,但在5.0需要分开写成
temp_ids=${temp[2]}
ids=${temp_ids[@]}
5. 鲲鹏代码迁移工具
鲲鹏代码迁移工具提供如下功能:
1)软件迁移评估:自动扫描并分析软件包(非源码包)、已安装的软件,提供可迁移性评估报告。
2)源码迁移:当用户有软件要迁移到基于鲲鹏916/920的服务器上时,可先用该工具分析源码并得到迁移修改建议。
3)软件包重构:帮助用户重构适用于鲲鹏平台的软件安装包。
4)专项软件迁移:使用华为提供的软件迁移模板修改、编译并产生指定软件版本的安装包,该软件包适用于鲲鹏平台。
5)增强功能:支持x86平台GCC 4.8.5~GCC 9.3版本32位应用向64位应用的64位运行模式检查,结构体字节对齐检查和鲲鹏平台上的弱内存序检查。
通过手动迁移结合鲲鹏代码迁移工具,根据不同工程的特点可以大大提高迁移效率。
本文重点讨论迁移流程,不对工具使用细节过多描述。
(三)数据库迁移
1. 迁移目标
数据库是典型业务信创系统中重要的组成部分,迁移目标是将Oracle数据库中的数据对象(表、视图、存储过程等)全部迁移至达梦数据库DM8中,且保证功能完整。数据库迁移主要包括两个部分,一是数据库server端,主要是数据对象的迁移和业务逻辑的验证。二是client端,包括各类API接口,如OCI/OCCI,JDBC等的迁移。
2. API及应用迁移
信创系统与数据库相关的应用包括S模块和J模块,两个模块分别使用C++和JAVA开发。
1)OCI应用迁移
DM8提供了多种C/C++接口,包括DCI/OCI,DPI,ODBC。原项目S模块采用OCI接口与Oracle数据库进行通信。因此建议过程中选取了DCI接口与DM8进行通信。DM DCI 是参照 OCI 的接口标准,结合自身的特点,为开发人员提供向 Oracle 兼容功能的一款接口产品。
修改CMakeLists.txt或Makefile,将链接路径、头文件路径、动态库指向DCI驱动路径($DMDBMS/drivers/dci)和动态库文件(libdmdpi.so)。修改完成后重新编译(注意:运行时需要确认LD_LIBRARY_PATH是否已包含dpi动态库路径)。DM8对Oracle有较好的兼容性,且应用针对持久化层有封装,因此迁移OCI接口过程相对简单。
2)JDBC应用迁移
典型业务信创系统的J模块使用JDBC与Oralce链接,JDBC已经对数据库接口进行了抽象,DM8提供了JDBC驱动($DMDBMS/drivers/jdbc/DmJdbcDriver18.jar,18表示对应的jdk版本,如:18对应jdk 1.8),迁移只需将驱动进行替换后重新打包应用即可。另外,可以使用针对鲲鹏定制的毕昇jdk(JDK8:BiSheng JDK 1.8.0_292-b13)。
3. 数据对象迁移
达梦数据库提供“DM数据迁移工具”DTS对常规对象进行迁移,常规对象指的是序列、表和视图,但存在一些兼容性的问题。整体上,大部分常规迁移操作可以通过迁移工具完成,部分不兼容功能需要调整代码或规避。
(四)功能验证
经过代码迁移,需对典型业务信创系统进行功能验证,验证方式为回归生产系统单元测试用例和集成测试用例。性能结果作为性能调优的基准数据,功能验证结果如下:
| 软件类型 | Kunpeng-920 鲲鹏处理器 |
Kylin-v10 银河麒麟 |
DM8 达梦数据库 |
|
|---|---|---|---|---|
| M模块 | 自研 | 通过 | 通过 | - |
| C模块 | 自研 | 通过 | 通过 | |
| S模块 | 自研 | 通过 | 通过 | 通过 |
| Kafka | 开源 | 通过 | 通过 | |
| otlv4 | 开源 | 通过 | 通过 | 通过 |
| tinyxml/tinyxml2 | 开源 | 通过 | 通过 | |
| Gate | 自研 | 通过 | 通过 | |
| zookeeper | 开源 | 通过 | 通过 | |
| openjdk | 工具 | 通过 | 通过 | |
| gcc/g++ | 工具 | 通过 | 通过 | |
| make/cmake | 工具 | 通过 | 通过 | |
| librdkafka | 开源 | 通过 | 通过 | |
| golang | 通过 | 通过 | 通过 | |
| J模块 | 通过 | |||
| SQL | 自研 |
(五)性能优化
1. 应用性能优化
鲲鹏提供一系列硬件加速手段,如加解密、解压缩等。本小节只讨论软加速手段,且不包括对业务代码本身的优化,只基于CPU架构和操作系统层面的优化,以确保与x86基准版本性能对比的准确性。
1)NUMA-Aware亲和度优化
鲲鹏920共有有4个NUMA节点 CPU 节点,每个 CPU 节点由多个(鲲鹏920有32/24/16个) CPU组成,并且具有独立的本地内存、 I/O 槽口等,相同 node 之间 CPU 和内存之间的访问称为本地访问,不同 node 之间的访问称为远程访问。很显然,访问本地内存的速度将远远高于访问远地内存的速度。可以使用numactl -H查看node、cpu、内存之间的关系以及node之间的距离。之后可以通过numactl -C绑定NUMA节点,减少CPU跨域访问内存,提高3级缓存使用率,提高进程运行性能。通过绑定NUMA节点应用性能可提升10+%,值得一提的是,绑定节点后性能波动得到很好的改善。
2)编译优化
a.-march=armv8-a:在编译时增加编译选项指定处理器架构为Armv8,使编译器按照鲲鹏处理器的微架构和指令集生成可执行程序,提升性能。
b.-mtune=tsv110:如果使用了gcc 9.1以上的版本在编译时增加编译选项指定使用tsv110流水线,使编译器按照鲲鹏处理器的流水线编排指令执行顺序,充分利用流水线的指令级并行,提升性能。
3)内存分配优化
鲲鹏GCC编译器基于开源GCC-9.3版本开发,并进行了优化和改进,实现软硬件深度协同优化,挖掘OpenMP、SVE向量化、数学库等领域极致性能,是一种Linux下针对鲲鹏920处理器的高性能编译器。
使用v9.3.1(Kunpeng定制)Kunpeng GCC 1.3.2编译器可是用其自带的jemalloc库,jemalloc是一个通用的malloc实现,着重于减少内存碎片和提高并发性能,以动态库的方式放置于鲲鹏GCC编译器内。
编译器内置两种版本的jemalloc库,命名相同,放置于不同目录,适用于不同类型的场景。
a.开源版jemalloc:适用于通用场景,位于编译器gcc-9.3.1-2021.03-aarch64-linux/lib64目录下,通过如下选项使能,选项:-ljemalloc。
b.优化版jemalloc:针对HPC高性能计算领域,位于编译器gcc-9.3.1-2021.03-aarch64-linux/lib64/libhpc目录下,通过如下操作使能:
export LD_LIBRARY_PATH=/opt/aarch64/compiler/gcc-9.3.1-2021.03-aarch64-linux/lib64/libhpc:$LD_LIBRARY_PATH
2. 数据库性能优化
1)参数调优
根据当前软硬件平台,包括CPU架构,数量,内存大小,操作系统等,需要调整默认参数,以达到数据库最有性能。
DM8参数可以通过动态调整,也可以修改数据库实例目录下的dm.ini文件,启动时需要在指定对应的配置文件,如./dmserver/your/dm/path/dm.ini。
参数优化参见附录A达梦配置参数优化列表。
2)客户端
客户端主要是针对达梦提供的API接口调用进行调优,本次主要针对批量处理和批量提交进行优化。批量处理需满足一下几个条件:a.ATCH_PARAM_OPT配置为1;b.表上有主键(实测,只有唯一索引不能触发批量操作);c.SQL的条件(where)需要落在主键上;(当前版本必须满足以上三个条件)。在触发批量的前提下,每1000~2000条进行一次提交可以达到应用最大性能。
通过上述优化S(数据同步写)模块,单进程单Session每秒可同步数据3.5w条。
五、总结
本文通过对核心交易系统部分典型业务模块信息技术应用创新平台的迁移实践,尽可能涵盖了包括C/C++、Java、Golang、数据库,中间件等核心技术栈。对基础设施(鲲鹏平台),基础软件(Kylin-v10操作系统、DM8数据库)以及主流开源软件(Kafka,Zookeeper)和自研应用(部分核心应用)做了全面的验证。对指令集架构和数据库兼容性对交易系统的影响有了跟进一步的了解,为核心系统的全面迁移和新系统的研发储备重要技术基础。
信息技术应用创新平台处于蓬勃发展的阶段,生态也在不断的完善中。期货行业作为关系国家经济命脉的行业是推进信息技术应用创新发展的主要力量,也为信创产业提供了更多的应用场景,是信创产业的土壤和温床。通过本次实践希望能对金融行业和信创生态提供更多的借鉴与思考。
六、附录
(一)达梦配置参数优化列表
| 参数名 | 默认值 | 优化值 | 参数说明 |
|---|---|---|---|
| COMPATIBLE_MODE | 0 | 2 | 是否兼容其他数据库模式。0:不兼容,1:兼容 SQL92 标准,2:部分兼容 ORACLE,3:部分兼容 MS SQL SERVER, 4:部分兼容 MYSQL,5:兼容 DM6,6:部分兼容 TERADATA |
| DATETIME_FMT_MODE | 0 | 1 | 是否兼容 ORACLE 日期格式。0:不兼容;1: 兼容 |
| CASE_COMPATIBLE_MODE | 0 | 1 | 涉及不同数据类型的 CASE 运算,是否需要兼容 ORACLE 的处理策略。 0:不兼容; 1:兼容,本模式下,当函数 DECODE()中的多个 CASE 类型不一致时, DECODE 会从其中选择一个类型进行匹配 2:兼容,本模式下,当函数 DECODE()中的多个 CASE 类型不一致时,DECODE 根据第一个 CASE 的类型来决定匹配类型 |
| MEMORY_POOL | 200 | 20000 | 共享内存池大小,以M为单位。共享内存池是由DM 管理 的内存 。有 效值范 围: 32位平台为(64~2000),64位平台为(64~67108864) |
| MEMORY_MAGIC_CHECK | 2 | 0 | 是否开启对所有内存池的校验。0:不开启;1:开启校验,校验码基于分配出的块地址计算,在被分配空间的头部和尾部写入校验码;2:增强校验,在 1 的基础上,如果是内存池分配的,则对尾部未使用空间也计算校验码,写入未使用空间的头部 |
| BUFFER | 100 | 180000 | 系统缓冲区大小,以 M 为单位。推荐值:系统缓冲区大小为可用物理内存的 60%~80%。有效值范围(8~1048576) |
| BUFFER_POOLS | 19 | 100 | BUFFER 系统分区数,每个 BUFFER 分区的大小为 BUFFER/BUFFER_POOLS。有效值范围(1~512) |
| RECYCLE | 64 | 19000 | RECYCLE 缓冲区大小,以 M 为单位。有效值范围(8~1048576) |
| RECYCLE_POOLS | 19 | 41 | RECYCLE 缓冲区分区数,每个 RECYCLE 分区的大小为 RECYCLE/RECYCLE_POOLS。有效值范围(1~512) |
| SORT_BUF_SIZE | 2 | 50 | 原排序机制下,排序缓存区最大值,以 M 为单位。有效值范围(1~2048) |
| SORT_BUF_GLOBAL_SIZE | 1000 | 9000 | 新排序机制下,排序全局内存使用上限,以 M为单位。有效值范围(10~4294967294) |
| SORT_FLAG | 0 | 1 | 排序机制,0:原排序机制;1:新排序机制 |
| HJ_BUF_GLOBAL_SIZE | 500 | 73000 | HASH 连接操作符的数据总缓存大小(>=HJ_BUF_SIZE),系统级参数,以 M 为单位。有效值范围(10~500000) |
| HJ_BUF_SIZE | 50 | 512 | 单个 HASH 连接操作符的数据总缓存大小,以 M为单位,必须小于 HJ_BUF_GLOBAL_SIZE。有效值范围(2~100000) |
| HAGR_BUF_GLOBAL_SIZE | 500 | 19000 | HAGR、DIST、集合操作、SPL2、NTTS2 以及HTAB 操作符的数据总缓存大小(>=HAGR_BUF_SIZE),系统级参数,以 M 为单位。有效值范围(10~1000000) |
| HAGR_BUF_SIZE | 50 | 512 | 单个 HAGR、DIST、集合操作、SPL2、NTTS2以及HTAB 操作符的数据总缓存大小,以M 为单位。有效值范围(2~500000)。如果 HAGR_BUF_SIZE设置的值满足范围且大于 HAGR_BUF_GLOBAL_SIZE,那么会在HAGR_BUF_GLOBAL_SIZE/2 和 500000 两个值中,选出较小的那个,作为新的HAGR_BUF_SIZE值。 |
| DICT_BUF_SIZE | 5 | 50 | 字典缓冲区大小,以 M 为单位,有效值范围(1~2048)。单位:MB |
| VM_POOL_SIZE | 64 | 8000 | 系统执行时虚拟机内存池大小,在执行过程中用到的内存大部分是从这里申请的,它的空间是从操作系统中直接申请的,有效值范围(32~1024*1024) |
| SESS_POOL_SIZE | 64 | 8000 | 会话缓冲区大小,以 KB 为单位,有效值范围(16~1024*1024)。若所申请的内存超过实际能申请的大小,则系统将按 16KB 大小重新申请 |
| WORKER_THREADS | 4 | 64 | 工作线程的数目,有效值范围(1~64) |
| TASK_THREADS | 4 | 64 | 任务线程个数,有效值范围(1~1000) |
| BATCH_PARAM_OPT | 0 | 1 | 是否启用批量参数优化,0:不启用;1:启用,默认不启用。当置为 1 时,不返回操作影响的行数 |
| VIEW_PULLUP_FLAG | 0 | 1 | 是否对视图进行上拉优化,把视图转换为其原始定义,消除视图。可取值 0、1、2、4。0:不进行视图上拉优化;1:对不包含别名和同名列的视图进行上拉优化;2:对包含别名和同名列的视图也进行上拉优化;4:强制允许带变量的查询语句进行视图上拉优化,有可能造成结果集错误;8 表示不对 LEFT JOIN 的右孩子RIGHT JOIN 的左孩子\FULL JOIN 左右孩子进行上拉 支持使用上述有效值的组合值,如 3 表示同时进行 1 和 2 的优化 |
| ADAPTIVE_NPLN_FLAG | 3 | 0 | 是否启用自适应计划机制,仅OPTIMIZER_MODE=1 时生效。0:不启用;1:对索引连接、嵌套含 VAR 连接等复杂连接启用自适应计划;2:ORDER BY 在 HASH 连接时启用自适应计划; 3:同时启用 1 和 2 的优化机制 |
| IO_THR_GROUPS | 2 | 8 | 非 WINDOWS 下有效,表示 IO 线程组个数。有效值范围(1~512) |
| MAX_SESSIONS | 100 | 1500 | 系统允许同时连接的最大数,同时还受到LICENSE 的限制,取二者中较小的值,有效值范围(1~65000) |
| MAX_SESSION_STATEMENT | 100 | 20000 | 单个会话上允许同时打开的语句句柄最大数,有效值范围(64~20480) |
| TEMP_SIZE | 10 | 1024 | 默认创建的临时表空间大小,以 M 为单位。有效值范围(10~1048576) |
| CACHE_POOL_SIZE | 20 | 2048 | SQL 缓冲池大小,以 M 为单位。有效值范围:32 位平台下为(1~2048);64 位平台下为(1~67108864)。单位:MB |
| RLOG_BUF_SIZE | 512 | 10240 | 单个日志缓冲区大小(以日志页个数为单位) ,取值只能为 2 的次幂值,最小值为 1,最大值为 20480 |
| RLOG_POOL_SIZE | 128 | 1024 | 最大日志缓冲区大小(以 M 为单位)。有效值范围(1~1024) |
| RLOG_PARALLEL_ENABLE | 0 | 1 | 是否启动并行日志,1:启用;0:不启用 |
| PARALLEL_PURGE_FLAG | 0 | 1 | 是否启用并行事务清理,0:不启用;1:启用 |
| MSG_COMPRESS_TYPE | 2 | 0 | 与客户端的通信消息是否压缩,0:不压缩;1:压缩;2:系统自动决定每条消息是否压缩 |