大数据生态体系产品(3) - HBase的架构与高性能存储
文章目录
- 1. HBase的诞生
-
- 1.1 设计模型
- 1.2 非关系数据库NoSQL
- 2. HBase的可伸缩架构
-
- 2.1 HRegion
- 2.2 HRegionServer
- 2.3 HMaster
- 2.4 数据写入过程
- 3. HBase的可扩展数据模型
- 4. HBase的高性能存储
-
- 4.1 数据存储
- 4.2 数据读取
1. HBase的诞生
Google发表GFS、MapReduce、BigTable三篇论文,号称“三驾马车”,开启了大数据的时代。本文介绍BigTable对应的NoSQL系统HBase,对大规模海量数据的处理。
1.1 设计模型
在计算机数据存储领域,一直是关系数据库的天下,许多应用系统设计都是面向数据库设计,导致关系模型绑架对象模型,并由此引申出旷日持久的业务对象贫血模型与充血模型之争。
这里说一下,几乎所有的Web项目,都是基于这种贫血模型的开发模式,甚至连Java Spring框架的官方demo,都是按照这种开发模式来编写的,关于为何贫血模型的开发模式会被广大程序员所接受,主要是有下面三点原因:
- 大部分情况下,我们开发的系统业务可能都比较简单;
- 充血模型的设计要比贫血模型更加有难度,不做过度设计;
- 思维已固化,转型有成本;
如果我们在项目中,应用基于充血模型的DDD的开发模式,那对应的开发流程就完全不一样了。在这种开发模式下,我们需要事先理清楚所有的业务,定义领域模型所包含的属性和方法。领域模型相当于可复用的业务中间层。新功能需求的开发,都基于之前定义好的这些领域模型来完成。
1.2 非关系数据库NoSQL
业界为了解决关系数据库的不足,提出了很多方案,比较有名的是对象数据库,这些数据库的出现进一步证明关系数据库的优越。
直到人们遇到了关系数据库难以克服的缺陷——糟糕的海量数据处理能力及僵硬的设计约束,局面才有所改善。从Google的BigTable开始,一系列的可以进行海量数据存储与访问的数据库被设计出来,NoSQL这一概念被提了出来。
NoSQL,主要指非关系的、分布式的、支持海量数据存储的数据库设计模式。也有许多专家表示NoSQL只是关系数据库的补充,并不是替代方案。HBase是NoSQL系统的杰出代表。
HBase能够具有海量数据处理的能力,原因是它和传统关系型数据库设计的不同思路。传统关系型数据库对存储在其上的数据有很多约束,学习关系数据库都要学习数据库设计范式,在数据存储中包含了一部分业务逻辑。而NoSQL数据库则简单暴力地认为,数据库就是存储数据的,业务逻辑应该由应用程序去处理。
2. HBase的可伸缩架构
HBase为可伸缩海量数据储存而设计,它的伸缩性主要依赖其可分裂的HRegion及可伸缩的分布式文件系统HDFS来实现。
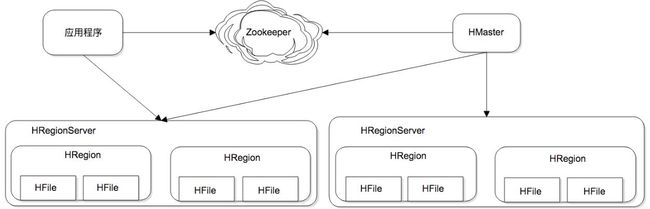
2.1 HRegion
HRegion是HBase负责数据存储的主要进程,程序对数据的读写操作都是通过和HRegion通信完成的。
数据以HRegion为单位进行管理,应用程序想要访问一个数据,必须先找到HRegion,然后将数据读写操作提交给HRegion,由HRegion完成存储层面的数据操作。
2.2 HRegionServer
HRegionServer是物理服务器,每个HRegionServer上可以启动多个HRegion实例。
当一个HRegion中写入的数据太多,达到配置的阈值时,一个HRegion会分裂成两个 HRegion,并将HRegion在整个集群中进行迁移,以使HRegionServer的负载均衡。
2.3 HMaster
每个HRegion中存储一段Key值区间[key1, key2)的数据。
所有HRegion的信息,包括存储的Key值区间、所在HRegionServer地址、访问端口号等,都记录在HMaster服务器上。
为了保证HMaster的高可用,HBase会启动多个HMaster,并通过ZooKeeper选举出一个主服务器。
应用程序通过ZooKeeper获得主HMaster的地址,输入Key值获得这个Key所在的HRegionServer地址,然后请求HRegionServer上的HRegion,获得所需要的数据。
时序图如下:

2.4 数据写入过程
与读过程一样,需要先得到HRegion才能继续操作。
HRegion会把数据存储在若干个HFile格式的文件中,这些文件使用HDFS分布式文件系统存储,在整个集群内分布并高可用。
当一个HRegion中数据量太多时,这个HRegion连同HFile会分裂成两个HRegion,并根据集群中服务器负载进行迁移。
如果集群中有新加入的服务器,也就是说有了新的HRegionServer,由于其负载较低,也会把HRegion迁移过去并记录到HMaster,从而实现HBase的线性伸缩。
3. HBase的可扩展数据模型
传统的关系数据库为了保证关系运算(通过SQL语句)的正确性,在设计数据库表结构的时候,需要指定表的字段名称、数据类型等,并要遵循特定的设计范式。这些规范导致扩展性差,即使是预先设计一些冗余字段也无法满足增量需求。
NoSQL数据库使用的列族(ColumnFamily)设计就是其中一个解决方案。列族最早在Google的BigTable中使用,这是一种面向列族的稀疏矩阵存储格式。

如上图所示的是一个学生的基本信息表,表中不同学生的联系方式各不相同,选修的课程也不同,将来会有更多联系方式和课程加入到这张表里。
使用支持列族结构的NoSQL数据库,在创建表的时候,只需要指定列族的名字,无需指定字段,可以在数据写入时再指定字段。通过这种方式,数据表可以包含数百万的字段,这样就可以随意扩展应用程序的数据结构了。
并且这种数据库在查询时也很方便,可以通过指定任意字段名称和值进行查询。
HBase这种列族的数据结构设计,实际上是把字段的名称和字段的值,以Key-Value的方式一起存储在HBase中。实际写入的时候,可以随意指定字段名称,即使有几百万个字段也能轻松应对。
4. HBase的高性能存储
我们知道,传统的机械式磁盘的访问特性是:连续读写很快,随机读写很慢。因为磁盘的寻址消耗的时间长,如果数据不连续存储,磁头需要不停地移动,会浪费大量的时间。
为了提高数据写入速度,HBase使用了一种叫LSM树的数据结构进行数据存储。LSM 树的全名是Log Structed Merge Tree,也就是Log结构合并树。
4.1 数据存储
数据写入的时候以Log方式连续写入,然后异步对磁盘上的多个LSM树进行合并。
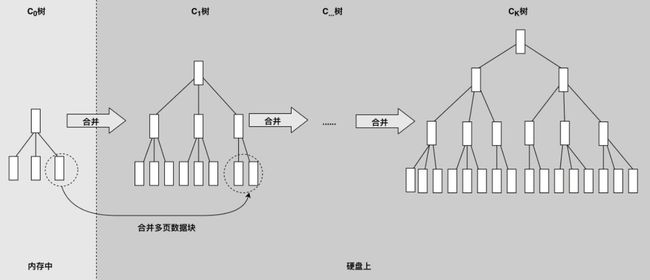
LSM树可以看成一个N阶合并树,数据读写都在内存中进行,都会创建新的记录,修改会记录新的数据,删除会记录删除标志。
在内存中依然是一颗排序树,当数据量超过设定的内存阈值,会将这棵排序树和磁盘上最新的排序树合并。
当这颗排序树的数据量也超过设定的阈值后,会和磁盘下一级的排序树合并。
合并过程中,会用最新更新的数据覆盖旧的数据。
4.2 数据读取
数据读取时,先从内存中的排序树开始搜索,如果没有找到,再从磁盘上的排序树上顺序查找。
在LSM树上进行一次数据更新不需要磁盘访问,在内存即可完成。
当数据访问以写操作为主,而读操作则集中在最近写入的数据上时,使用LSM树可以极大程度地减少磁盘的访问次数,加快访问速度。
参考文章
- https://blog.csdn.net/zhangzeyuaaa/article/details/113242728