Redis高级
Redis持久化
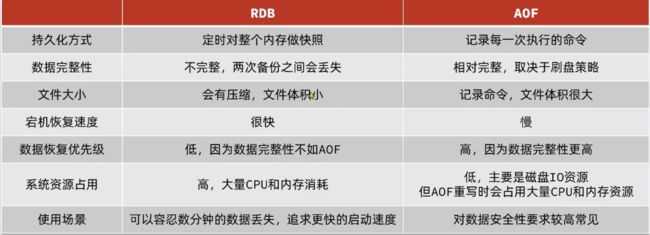
解释:就是将数据序列化,达到数据备份,防止数据丢失。
RDB持久化方案
就是将数据在设定的某一时刻记录到rdb文件中持久化保存到磁盘当中。
考虑到主进程持久化会造成资源阻塞,redis会单独创建(fork)一个子进程来进行持久化,而主进程是不会进行任何IO操作的,这样就确保了redis极高的性能。
实现原理:就是主进程会在自己所在的虚拟内存种根据页表进行读写硬盘中的数据,子进程会根据主进程的页表进行内存的读取数据到自己的虚拟内存,然后写到硬盘中,为了方式读写冲突避免脏数据,主进程执行写操作时,内存会拷贝一份数据供主进程进行写入,然后新旧替换。
如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
虽然RDB有不少优点,但它的缺点也是不容忽视的。如果你对数据的完整性非常敏感,那么RDB方式就不太适合你,因为即使你每5分钟都持久化一次,当redis故障时,仍然会有近5分钟的数据丢失。所以,redis还提供了另一种持久化方式,那就是AOF。
AOF持久化方案
就是将操作数命令记录到aof文件中进行持久化保存到磁盘当中。
redis会根据配置的频率进行命令的序列化存储,所有操作都有主进程来完成。有三种频率写入方式,第一种,就是边执行边写,每当有一次执行命令操作,主进程会同时将命令写入到aof文件当中。第二种,就是执行命令将命令写在缓冲区中,每隔一秒将缓冲区所有命令写到aof中,这样的好处就是如果发生数据丢失也仅丢失一秒的数据。第三种,就是执行命令,将所有命令都写到缓冲区,由操纵系统来决定什么时候将命令写到aof文件当中。

AOF重写
作用:因为存在key多次操作被覆盖产生堆积,照成aof文件体积过大,使用bgrewriteaof命令将对key操作后无效命令进行清除只保留最后的有效命令从而使用最少的命令达到同样的效果。
实际开发是两种方案搭配使用。
Redis集群
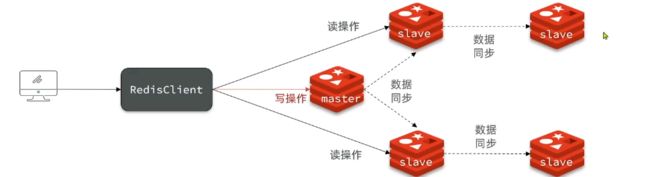
作用:解决redis单节点并发能力上限问题,提高redis处理并发能力,实现读写分离。
主从数据同步底层
全量同步
就是主节点会根据repid判断该从节点是否为第一次同步,如果是,则主节点会将所有数据全部给从节点,先给定数据版本信息,会执basave生成rdb文件并发送给从节点,从节点清楚本地数据重新加载rdb文件,中间存在命令产生,主节点进程会异步去记录一份命令操作文件,然后将其文件发送给从节点,确保数据完整性。

增量同步
就是建立在第一次同步主从产生关系的基础上存在重启的操作照成数据补全的过程。

注意:如果当主从数据同步数据丢失达到上限时,(即当红色循环一圈覆盖掉绿色部分)从节点就无法从主节点获取到丢失数据,原因已被覆盖,则需要进行全量同步。
如何解决主从同步时,主节点附载太多从节点,造成主节点压力过大问题?
答:可以采用主-从-从链式结构布局。
Redis哨兵(Sentinel)机制
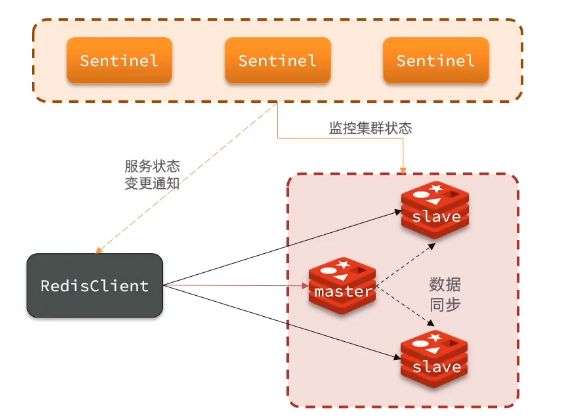
作用:实现主从集群的自动故障恢复。
监控作用:Sentinel会不断检查监听自己所对应的主从节点的状态是否正常。
自动故障恢复作用:如果主节点故障,Sentinel会将其中的一个从节点提升成主节点,如果故障恢复后的库将会降级成从节点。
通知作用:Sentinel会充当java客户端的发现来源,java客户端不会直接访问主从节点来获取它们的地址,而是访问Sentinel来获取地址进行访问,此过程类似服务注册过程,如果存在主节点故障时,Sentinel会通知java客户端新的
主节点地址。
Sentinel是如何知道集群状态是否正常呢?
答:Sentinel会每隔一秒就会向集群的库发送ping命令,如果库没在规定时间内回应,则会有两种下线可能判定,第一种是库绑定的Sentinel认为下线了为主观下线,第二种是由指定数量的Sentinel来决定该库是否下线为客观下线,数量最好超过Sentinel总量的一半。
主从故障转移
答:如果存在主节点存在故障,则Sentinel会从剩余的从节点选取新的作为主节点,选举条件,会判断剩下的从节点同步进度,如果存在某从节点与之前主节点同步差距超过指定值,就会被视为没有选举权,其次判断从节点配置文件priority值的大小,默认大家都等值(值越小选举优先级越高),如果值都是默认的就会判断从节点的offset值(该值为与主节点同步完整度值)值越高,就代表该从节点的数据与之前主节点同步数据更接近,最新。如果还一致最后会根据id值(id是全量同步主节点赋予的唯一标记)大小来进行选举,越小优先级越高。当选举完成后,Sentinel会发送slaveof no one命令给被选库成为主节点,并且发送新主节点的地址给其他节点来进行新的信息同步
分片集群
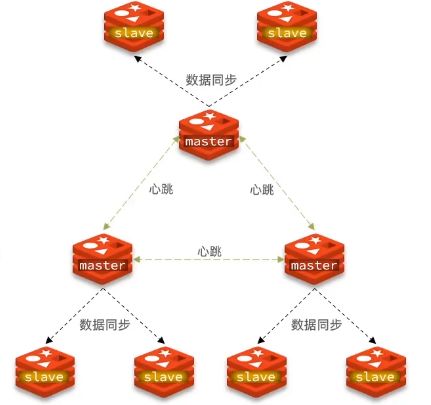
作用:基于主从集群存在主节点唯一的缺点,造成主节点对于高并发写操作存储操作能力低问题使用分片集群,没有主从关系,每个库都是主节点并保存不同数据,这样数据存储的上限取决主节点的上限,并且每个主节点附载其他的从节点,主节点之间通过ping监视对方状态,不需要哨兵了,如果java客户端访问时,不管访问哪个节点,节点之间会相互路由到对应所要访问的节点
散列插槽

作用:将所有节点分均映射到16384的插槽中,每个节点有固定插槽值范围,数据是与插槽绑定的。
如果数据存入到集群中,怎么知道存在哪个节点上?
答:redis会将数据有效部分(有效部分就是"{}"中包裹的数据,但至少有一个,如果整个key没有{}则整个都是有效部分)计算插槽值来寻找对应的节点,计算方法,有效部分通过CRC16算法获得hash值对16384取余得到的值slot对应在那个节点卡槽值范围中。
关于分区集群故障转移
每个集群内部故障转移原理就是单个集群的故障转移处理方式一致。请往上看
数据迁移
原理:就是当一个集群中的主节点被手动停止服务,则从节点会询问主节点是否停止服务,如果停止服务,则主节点会把数据同步给从节点达到最新数据同步,这两个主从身份就会互换。