Python 爬虫 面试题
目录
理论
笔试或面试记录题
理论
爬虫遵循的协议:robot协议
定义:网络爬虫排除标准。
作用:告诉搜索引擎哪里可以爬,哪里不可以爬。
爬虫分类
(1)通用爬虫:搜索引擎的主要组成,作用就是将互联网的上页面整体的爬取下来之后,保存到本地。
(2)聚焦爬虫:聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。通用爬虫和聚焦爬虫的区别:聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
通用爬虫工作流程
1)抓取网页:通过搜索引擎将待爬取的url加入到通用爬虫的url队列中,进行网页内容的爬取
2)数据存储:将爬取下来的网页保存到本地,这个过程会有一定的去重操作,如果某个网页的内 容大部分内容都会重复,搜索引擎可能不会保存。
3)预处理:提取文字,中文分词,消除噪音(比如版权声明文字,导航条,广告等)。
4)设置网站排名,为用户提供服务。
一些反爬及其应对措施
推送门:关于反爬与反反爬
1)通过user-agent来判断是否是爬虫。
解决方案:可以通过伪装请求头中的user-agent来解决。若user-agent被检测到,可以找大量的user-agent,放入列表,然后进行更换
2)将IP进行封杀。
解决方案:可以通过代理来伪装IP。
3)通过访问频率来判断是否是一个爬虫。
解决方案:可以通过设置请求间隔,和爬取间隔。
4)当一定时间内的总请求数超过上限,弹出验证码。
解决方案:对于简单的验证码图片可以使用tesseract来处理,对于复杂的可以去打码平台。
5)通过JS来获取页面数据。
解决方案:可以使用selenium+phantomjs来加载JS获取数据。
介绍搜索引擎
1.搜索引擎的主要组成
通用爬虫:就是将互联网的上页面整体的爬取下来之后,保存到本地。通用爬虫要想爬取网页,需要网站的url.但是搜索引擎是可以搜索所有网页的。那么通用爬虫url就要涉及到所有网页,这个‘所有’是如何做到的:
- 新网站向搜索引擎主动提交网址;
- 在其他网站上设置新网站外链;
- 搜索引擎和DNS解析服务商(如DNSPod等)合作,新网站域名将被迅速抓取。
2.搜索引擎的工作流程(通用爬虫的工作流程)
(1)抓取网页:通过搜索引擎将待爬取的URL加入到通用爬虫的URL队列中,进行网页内容的爬取。
(2)数据存储:将爬取下来的网页保存到本地,这个过程会有一定的去重操作,如果某个网页的内 容大部分内容都会重复,搜索引擎可能不会保存。
(3)预处理:提取文字,中文分词,消除噪音(比如版权声明文字,导航条,广告等)。
(4)设置网站排名,为用户提供服务。
3.搜索引擎的局限性
(1)搜索引擎只能爬取原网页,但是页面90%内容都是无用的。
(2)搜索引擎不能满足不同行业,不同人的特定需求。
(3)通用搜索引擎只能爬取文字信息,不能对音频、图片等进行爬取。
(4)只能基于关键字查询,无法基于语义查询。
介绍HTTP
网络七层协议:
1.HTTP协议特点
- HTTP协议是超文本传输协议;
- HTTP协议是一个应用层协议;
- 无连接:每次请求都是独立的;
- 无状态,表示客户端每次请求都不能记录请求状态,就是两条请求直接不可通信。
2.HTTP工作过程
- 地址进行DNS解析,将URL解析出对应的内容
- 封装HTTP请求数据包
- 封装成TCP包,建立TCP连接(TCP的三次握手)
- 客户端发送请求
- 服务器接收请求,发送响应
- 客户端接收到响应,进行页面渲染
- 服务器关闭TCP连接(TCP的四次挥手)
3.HTTP协议和HTTPS协议的区别
- HTTP协议是使用明文数据传输的网络协议,明文传输会让用户存在一个非常大的安全隐患。端口80
- HTTPS协议可以理解为HTTP协议的安全升级版,就是在HTTP的基础上增加了数据加密。端口443
- HTTPS协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议要比HTTP协议安全。
4.HTTP通信
HTTP通信由两部分组成:客户端请求消息与服务器响应消息。
5.关于响应常见的响应码
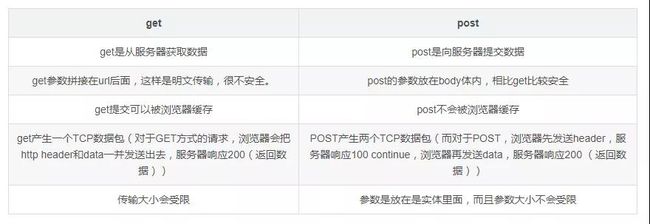
6.客户端请求(Get和Post区别)
(1)组成:请求行、请求头部、空行、请求数据四个部分组成
(2)请求方法Get/Post
(3)Get和Post的区别GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。
(4)常见的请求头
User-Agent:客户端请求标识
Accept:传输文件类型。Referer :请求来源
cookie (cookie):在做登录的时候需要封装这个头
Content-Type (POST数据类型)
7.服务器响应
(1)组成:状态行,响应头,空行,响应正文。
(2)常见的响应头
Content-Type:text/html;资源文件的类型,还有字符编码
Content-Length:响应长度
Content-Size响应大小
Content-Encoding告诉客户端,服务端发送的资源是采用什么编码的
Connection:keep-alive这个字段作为回应客户端的
Connection:keep-alive,告诉客户端服务器的tcp连接也是一个长连接,客户端可以继续使用这个TCP连接发送HTTP请求。


URL
统一资源定位符:
基本格式:scheme://host[:port#]/path/…/?query-string 协议://服务器ip地址:端口号/资源路径/?key1=参数1&key2=参数2scheme:协议(例如:HTTP、HTTPS、FTP)
host/IP:服务器的IP地址或者域名
port:服务器的端口(如果是走协议默认端口,缺省端口80),用来从互联网进入电脑
path:访问资源的路径,就是为了在电脑中找到对应的资源路径
query-string:参数,发送给http服务器的数据
anchor:锚(跳转到网页的指定锚点位置)
Q:当我们在浏览器输入一个URL,为什么可以加载出一个页面?为什么抓包的过程中请求一个URL,出现很多的资源请求?
当我们在浏览器输入一个URL,客户端会发送这个URL对应的一个请求到服务器获取内容。服务器收到这个请求,解析出对应内容,之后将内容封装到响应里发送到客户端
当客户端拿到这个HTML页面,会查看这个页面中是否有CSS、JS、image等URL,如果有,在分别进行请求,获取到这些资源。
客户端会通过HTML的语法,将获取到的所有内容完美的显示出来。
Cookie和Session
产生原因:由于HTTP是一个无状态的协议,每次请求如果需要之前的一些信息,无法记录,因此为了解决这个问题,产生了一种记录状态技术,Cookie和Session。
Cookie指某些网站为了辨别用户身份,进行会话跟踪而存储在用户本地终端上的数据,种类有会话Cookie和持久Cookie。
(1)会话Cookie指存在浏览器内存的Cookie,当浏览器关闭,会话Cookie会失效;
(2)持久Cookie是保存在硬盘上的Cookie。
Session用来存储特定的用户会话所需的属性及其配置信息。
Cookie是在客户端记录状态,Session是在服务端记录状态。
联系:当客户端发送一个Cookie,服务器会从这个Cookie中找到sessionID,再查找出相应的Session信息返回给客户端,来进行用户页面的流转。如果通过sessionID来查找Session的时候,发现没有Session(一般第一次登陆或者清空了浏览器),那么就会创建一个Session。
hashlib密码加密
def get_hex(value):
md5_ = hashlib.md5()
md5_.update(value.encode('utf-8'))
return md5_.hexdigest()
关于response.text乱码问题
response的常用属性:
1.获取字符串类型的响应正文:response.text
2.获取bytes类型的响应正文:response.content
3.响应正文字符串编码:response.encoding
4.状态码:response.status_code5.响应头:response.headers
response.text乱码问题:
#方法一:转换成utf-8格式
response.encoding='utf-8'
print(response.text)
#方法二:解码为utf-8 :
with open('index.html','w',encoding='utf-8') as fp: fp.write(response.content.decode('utf-8'))
代理
代理的作用:
1、突破自身IP 访问限制, 访问一些平时不能访问的站点。
2、访问一些单位或团体内部资源:比如使用教育网内地址段免费代理服务器, 就可以用于对教育网开放的各类FTP 下载上传, 以及各类资料查询共享等服务。
3、提高访问速度:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时, 同时也将其保存到缓冲区中,当其他用户再访问相同的信息时,则直接由缓冲区中取屮信息传给用户,以提高访问速度。
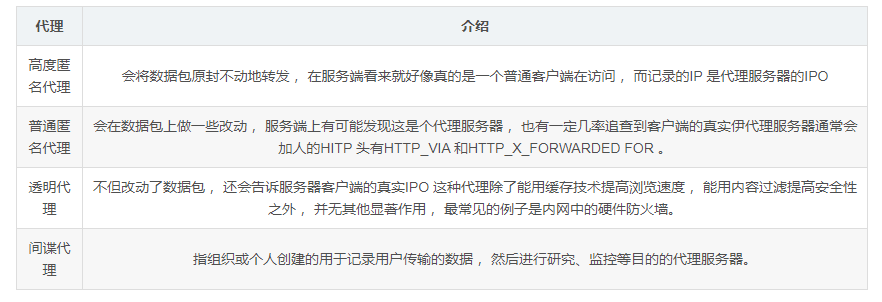
4、隐藏真实IP :上网者也可以通过这种方法隐藏自己的IP , 免受攻击。对于爬虫来说, 我们用代理就是为了隐藏自身IP , 防止自身的被封锁。代理根据匿名程度的分类:
JSON数据
数据的分类:
JSON的本质:是一个字符串,JSON是对JS对象的字符串表达式,它使用文本形式表示一个JS对象的信息。
JSON使用:
(1)json.dumps(Python的list或者dict),将Python的list或者dict返回为一个JSON字符串;
(2)json.loads(json字符串),将JSON字符串返回为Python的list或者dict;
(3)json.dump(list/dict,fp),将Python的list或者dict转为一个JSON字符串,保存到文件中;
(4)json.load(fp) ,从JSON文件中读出JSON数据,并转换为Python的list或者dict。

正则表达式
1、贪婪和非贪婪
(1)正则默认是贪婪模式,所以数量控制符默认是取最大值,也是贪婪。例如*
(2)非贪婪是用?来控制,尽量匹配最少的次数,0次或一次。2、Python使用格式:
pattern=re.compile('正则表达式') print(pattern.match(字符串,start,end))#默认从头开始匹配,只匹配一次,返回一个match对象 print(pattern.search(字符串,start,end))#从任意位置开始匹配,只匹配一次,返回一个match对象 print(pattern.findall(字符串,start,end))#全文多次匹配,将匹配到的结果放到一个list返回给我们 print(pattern.finditer(字符串,start,end))#全文多次匹配,将匹配到的结果放到一个match对象的迭代器返回3、常见的正则题目

笔试或面试记录题
python 常用数据结构有哪些?请简要介绍一下。
Python中常见的数据结构可以统称为容器。序列(如列表和元组)、映射(如字典)以及集合(set)是三类主要的容器。
线性数据结构分类:栈(stack)--先进后出、 队列(queue)-先进先出、双端队列(deque)、链表(LinkedList)
简要描述 Python 中单引号、双引号、三引号的区别。
单引号 与 双引号
一般情况单引号和双引号都可以用来表示一个字符串,没有什么区别,当你用单引号' '定义字符串的时候,它就会认为你字符串里面的双引号" "是普通字符,从而不需要转义。反之当你用双引号定义字符串的时候,就会认为你字符串里面的单引号是普通字符无需转义。
3个单引号及3个双引号
通常情况下我们用单引号或者双引号定义一个字符串的时候只能把字符串连在一起写成一行,如果要写成多行就得在每一行后面加一个\表示连字符,使用三个引号就可以按预期的格式输入,如:
>>> str1 = """List of name: ... Ming Li ... Xiao Dong ... """ >>> print(str1) List of name: Ming Li Xiao Dong使用3个引号还有一个作用就是 加注释
3个单引号和双引号大部分情况下无明显区别,需要注意如果字符串中包含有单引号就要使用双引号来定义。
- 三单引号:”’python ”’,也可以表示字符串,一般用来输入多行文本,或者用于大段的注释
- 三双引号:”””python”””,一般用在类里面,用来注释类,这样可以直接用类的对象__doc__访问获得文档
如何在一个 function 里面设置一个全局的变量?
用global声明
Python 里面如何拷贝一个对象?(浅拷贝、深拷贝)
1. 浅拷贝 :
使用 copy.copy 进行浅拷贝,就是拷贝了引用(修改拷贝对象元素,则被拷贝对象元素也被修改)
2. 深拷贝 :
使用 copy.deepcopy 进行深拷贝,就是获得了一个全新的对象,与被拷贝对象完全独立,但这需要牺牲一定的时间和空间。
3. 特殊拷贝:
如要复制列表L,使用list(L),要复制一个字典d,使用dict(d),要复制一个集合s,使用set(s)。
也就是:如果要复制某个属于python内建类型的对象,可以使用这个对象的type(object)来获得一个拷贝。
闭包
在函数嵌套的前提下,内部函数使用了外部函数的变量,并且外部函数返回了内部函数,我们把这个使用外部函数变量的内部函数称为闭包。
闭包的形成条件:
- 在函数嵌套(函数里面再定义函数)的前提下
- 内部函数使用了外部函数的变量(还包括外部函数的参数)
- 外部函数返回了内部函数
闭包可以提高代码的可重用性,不需要再手动定义额外的功能函数。
装饰器
就是给已有函数增加额外功能的函数,它本质上就是一个闭包函数(把函数作为参数传入)。
装饰器的功能特点:
- 不修改已有函数的源代码
- 不修改已有函数的调用方式
- 给已有函数增加额外的功能
语法糖的书写格式是函数上面: @装饰器名字
- @check 等价于 comment = check(comment)
- 装饰器的执行时间是加载模块时立即执行。
生成器
根据程序员制定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成处理,而是使用一个,再生成一个,可以节约大量的内存。
- 生成器推导式:与列表推导式类似,只不过生成器推导式使用小括号
- yield 关键字
next 函数获取生成器中的下一个值、for 循环遍历生成器中的每一个值。
yield 关键字:只要在def函数里面看到有 yield 关键字那么就是生成器。
- 代码执行到 yield 会暂停,然后把结果返回出去,下次启动生成器会在暂停的位置继续往下执行
- 生成器如果把数据生成完成,再次获取生成器中的下一个数据会抛出一个StopIteration 异常,表示停止迭代异常
- while 循环内部没有处理异常操作,需要手动添加处理异常操作
- for 循环内部自动处理了停止迭代异常,使用起来更加方便,推荐大家使用。
如果 custname 字符串格式utf-8,如何将其转为 gb18030 ?
先将 custname 编码格式转换为 unicode,在转换为gb18030。
即custname.decode('utf-8').encode('gb18030')。
ps:unicode编码是一种二进制编码,是转换编码的中间桥梁。比如需要将utf-8转换为gbk,那么就需要先转换为unicode(decode),再转为gbk(encode)。
请写出一段 Python 代码实现删除一个 list 里面的重复元素。
两种方法:
1. 利用字典的 fromkeys 来自动过滤重复值;
a = [1, 2, 3, 4, 5, 2, 3] def fun1(a): b = {} b = b.fromkeys(a) c = list(b.keys()) print(c) c = fun1(a)2. 利用 集合set 的特性,元素是非重复的。
a = [1, 2, 3, 4, 5, 2, 3] def fun1(a): a = list(set(a)) print(a) fun1(a)
这两个参数是什么意思:*args,**kwargs ?
都是用于传递参数的,*和**是固定的,args和kwargs是约定俗成的命名
- *args传递的是非键值对的参数(列表);
- **kwargs传递的是带键值对的参数(字典)。
统计如下 list 单词及其出现次数。
a=['apple', 'banana', 'apple', 'tomato', 'orange', 'apple', 'banana', 'watermeton']
1. 利用字典:
dic = {} for key in a: # get() 函数返回指定键的值 dic[key] = dic.get(key, 0) + 1 print(dic) # 输出结果: {'apple': 3, 'banana': 2, 'tomato': 1, 'orange': 1, 'watermeton': 1}2. 利用 collections包:
from collections import Counter d = Counter(a) print(d) # 输出结果: Counter({'apple': 3, 'banana': 2, 'tomato': 1, 'orange': 1, 'watermeton': 1}) # 是一个类似字典的结构
给列表中的字典排序:假设有如下 list 对象
alist=[{"name":"a", "age":20}, {"name":"b", "age":30}, {"name":"c", "age":25}],将alist中的元素按照age从小到大排序。
使用 list 的 .sort() 进行排序:
alist.sort(key=lambda x: x['age'])输出结果:
1 [{'name': 'a', 'age': 20}, {'name': 'c', 'age': 25}, {'name': 'b', 'age': 30}]
写出下列代码的运行结果
a = 1
def fun(a):
a = 2
fun(a)
print(a)
############################
a = []
def fun(a):
a.append(1)
fun(a)
print(a)
############################
class Person:
name = 'Lily'
p1 = Person()
p2 = Person()
p1.name = 'Bob'
print(p1.name)
print(p2.name)
print(Person.name)1
[1]
Bob
Lily
Lily
假设有如下两个 list:a = ['a', 'b', 'c', 'd', 'e'],b = [1, 2, 3, 4, 5],将 a 中的元素作为 key,b 中元素作为 value,将 a,b 合并为字典。
a = ['a', 'b', 'c', 'd', 'e', 'f', 'g'] b = [1, 2, 3, 4, 5, 6] 方法一:用for循环遍历dict1 = {} for i in a: for j in b: # 以列表的下标相对应的元素作为键值对 if a.index(i) == b.index(j): # 以列表的下标跟列表的元素个数对比,如果存在第一个列表元素 dict1.setdefault(i, j) # 个数大于另一个列表元素的情况,会默认用None补充 elif a.index(i) > len(b) - 1: dict1.setdefault(i) print(dict1) # {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6, 'g': None}方法二:用zip函数,优点是代码量少,易理解,缺点是如果两个列表元素个数不同时,会取最短dict1 = dict(list(zip(a, b))) print(dict1) # {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
使用 python 已有的数据结构,简单的实现一个栈结构。
class Stack(object): """ 栈 使用python列表实现 """ def __init__(self): self.items = list() def is_empty(self): """判空""" return self.items == [] def size(self): """获取栈元素个数""" return len(self.items) def push(self, item): """入栈""" self.items.append(item) def pop(self): """出栈""" self.items.pop() def peek(self): """获取栈顶元素""" if self.is_empty(): raise IndexError("stack is empty") return self.items[-1]
数据如何去重,清洗,存入数据库?
遇到哪些反爬机制?如何解决?
反爬与反反爬_mengnf的专栏-CSDN博客
面试官提的问题:项目上遇到了哪些难点?如何解决?
你是怎么理解爬虫的
- 爬虫的目的就是为了抓取万维网信息资源,比如谷歌百度等搜索引擎,搜索结果全都依赖爬虫来定时获取 ;
爬虫的目标对象也很丰富,不论是文字、图片、视频,任何的数据爬虫都可以爬取;
爬虫经过发展,也衍生出了各种爬虫类型:
1. 通用爬虫:从一些种子 URL 扩充到整个 Web,如搜索引擎;
2. 聚焦爬虫:专门抓取某一个(某一类)网站数据;大部分网站都有 robots.txt 文件,告诉爬虫什么可以爬取什么不可以爬取(君子协议)
scrapy
- scrapy的基本结构(五个部分都是什么,请求发出去的整个流程)
- scrapy的去重原理(指纹去重到底是什么原理)
- scrapy中间件有几种类,你用过哪些中间件
- scrapy中间件在哪里起的作业(面向切片编程)
代理问题:
- 为什么会用到代理
- 代理怎么使用(具体代码, 请求在什么时候添加的代理)
- 代理失效了怎么处理
验证码处理:
- 登陆验证码处理
- 爬取速度过快出现的验证码处理
- 如何用机器识别验证码
模拟登陆问题:
- 模拟登陆流程
- cookie如何处理
- 如何处理网站传参加密的情况
分布式:
- 分布式原理
- 分布式如何判断爬虫已经停止了
- 分布式的去重原理
数据存储和数据库问题:
- 关系型数据库和非关系型数据库的区别
- 爬下来数据你会选择什么存储方式,为什么
- 各种数据库支持的数据类型,和特点
Python基础问题:
Python 核心技术 面试题_mengnf的专栏-CSDN博客
协议问题:
1.http协议,请求由什么组成,每个字段分别有什么用,https和http有什么差距
2.证书问题
3.TCP,UDP各种相关问题
数据提取问题:
- 主要使用什么样的结构化数据提取方式,可能会写一两个例子
- 正则的使用
- 动态加载的数据如何提取
- json数据如何提取
算法问题:
算法:你们要善用Python的数据类型,对Python的数据结构深入了解