基于 SmartX 分布式存储的 RDMA 与 TCP/IP 技术与性能对比
作者:深耕行业的 SmartX 金融团队
背景
上一篇 “分布式块存储 ZBS 的自主研发之旅|架构篇” 文章中,我们简单介绍了 SmartX 分布式块存储 ZBS 的架构原理。接下来,我们将为读者深入解析 ZBS 存储中最为重要的技术之一“RDMA”。
目前 ZBS 在两个层面会使用到 RDMA 技术,分别是存储接入网络和存储内部数据同步网络。为了使读者更加容易理解,以及更有针对性地做存储性能对比,特通过两篇独立的文章分别进行介绍。本期,我们将聚焦 RDMA 远程内存直接访问技术,并结合 ZBS 内部存储数据同步进行详细的展开(ZBS 支持 RDMA 能力,也是在存储内部数据同步中最先实现)。
ZBS 存储内部数据同步
分布式存储系统与集中存储最重要的区别之一就是架构实现。分布式架构要保证数据的存储一致性和可靠性,就必须依赖网络进行数据同步。这里举一个例子,一个由 3 节点(A/B/C)组成的 ZBS 存储集群,数据采用两副本保护(数据存储两份,放置在不同的物理节点),假设数据分别存放在节点 A 和节点 B 上,当数据发生修改,ZBS 分布式存储必须完成对节点 A 和 B 的数据修改再返回确认。在这个过程中,A 和 B 节点同步数据修改,所使用的网络,即是存储网络。
通过例子,相信读者已经理解,数据同步效率对于分布式存储的性能表现有着非常大的影响,是分布式存储性能优化的重要方向之一,也是本篇文章重点讨论的内容。
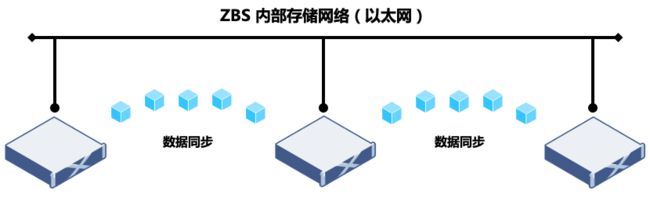
图 1:分布式存储数据同步网络
在目前常规的工作负载需求下,ZBS 存储网络通常使用 10GbE 以太网交换机和服务器网卡配置,采用标准 TCP/IP 作为网络传输协议。但对于高带宽和低延时的业务工作负载,这样的配置明显会成为内部存储数据同步的性能瓶颈。同时,为了发挥新型的高速存储介质(例如 NVMe 磁盘)更强劲的 I/O 性能,采用 RDMA 技术并结合 25GbE 或更高的网络规格,是满足业务端更高的存储性能诉求的更优选择。
TCP/IP
通过软件定义实现的分布式存储,基于通用标准的硬件构建,是其有别于传统存储的重要的特点之一。多年以来,ZBS 使用 TCP/IP 网络协议栈作为存储内部通信方式,优势是具备与现有以太网最大的兼容性,同时满足绝大多数客户的业务工作负载需求。但 TCP/IP 网络通信逐渐不能适应更高性能计算的业务诉求,其主要限制有以下两点:
TCP/IP 协议栈处理带来的时延
TCP 协议栈在接收/发送数据报文时,系统内核需要做多次上下文切换,这个动作无疑将增加传输时延。另外在数据传输过程中,还需要多次数据复制和依赖 CPU 进行协议封装处理,这就导致仅仅是协议栈处理就带来数十微秒的时延。
TCP 协议栈处理导致服务器更高的 CPU 消耗
除了时延问题,TCP/IP 网络需要主机 CPU 多次参与到协议栈的内存复制。分布式存储网络规模越大,网络带宽要求越高,CPU 收发数据时的处理负担也就越大,导致 CPU 资源的更高消耗(对于超融合架构,是非常不友好的)。
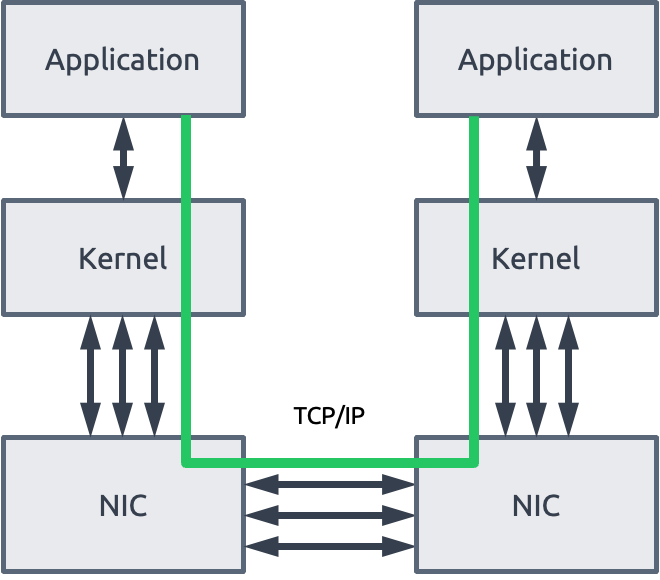
图 2:TCP/IP Socket 通信
RDMA
RDMA 是 Remote Direct Memory Access 的缩写。其中 DMA 是指设备直接读写内存技术(无需经过 CPU)。
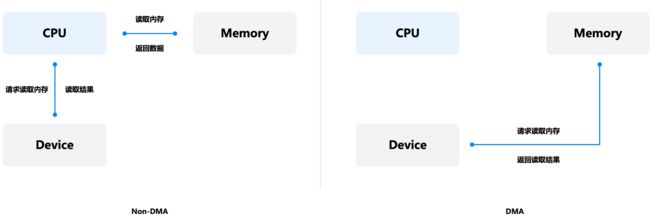
图 3:DMA
RDMA 技术的出现,为降低 TCP/IP 网络传输时延和 CPU 资源消耗,提供了一种全新且高效的解决思路。通过直接内存访问技术,数据从一个系统快速移动到远程系统的内存中,无需经过内核网络协议栈,不需要经过中央处理器耗时的处理,最终达到高带宽、低时延和低 CPU 资源占用的效果。
目前实现 RDMA 的方案有如下 3 种:
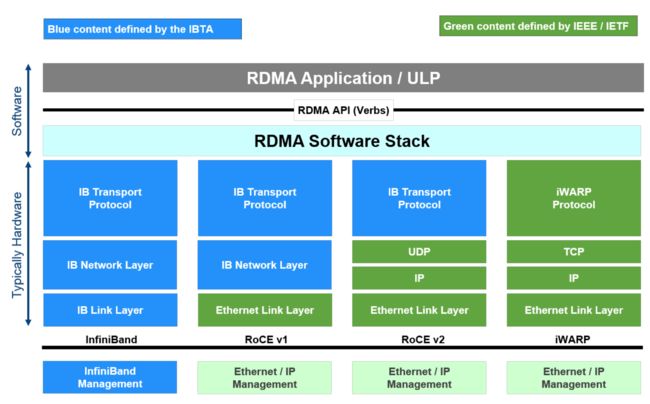
图 4:RDMA 实现方案 (图片来源:SNIA)
InfiniBand(IB)是一种提供了 RDMA 功能的全栈架构,包含了编程接口、二到四层协议、网卡接口和交换机等一整套 RDMA 解决方案。InfiniBand 的编程接口也是 RDMA 编程接口的事实标准,RoCE 和 iWARP 都使用 InfiniBand 的接口进行编程。
RoCE(RDMA over Converged Ethernet)和 iWARP(常被解释为 Internet Wide Area RDMA Protocol,这并不准确,RDMA Consortium 专门做出解释 iWARP 并不是缩写),两个技术都是将 InfiniBand 的编程接口封装在以太网进行传输的方案实现。RoCE 分为两个版本,RoCEv1 包含了网络层和传输层的协议,所以不支持路由(更像是过渡协议,应用并不多);RoCEv2 基于 UDP/IP 协议,具有可路由能力。iWARP 是构建于 TCP 协议之上的。
跟 RoCE 协议继承自 Infiniband 不同,iWARP 本身不是直接从 Infiniband 发展而来的。Infiniband 和 RoCE 协议都是基于“Infiniband Architecture Specification”,也就是常说的“IB 规范”。而 iWARP 是自成一派,遵循着一套 IETF 设计的协议标准。虽然遵循着不同的标准,但是 iWARP 的设计思想受到了很多 Infiniband 的影响,并且目前使用同一套编程接口(Verbs*)。这三种协议在概念层面并没有差异。
* Verb 是 RDMA 语境中对网络适配器功能的一个抽象,每个 Verb 是一个函数,代表了一个 RDMA 的功能,实现发送或接收数据、创建或删除 RDMA 对象等动作。
RDMA 需要设备厂商(网卡和交换机)的生态支持,主流网络厂家的协议支持能力如下:
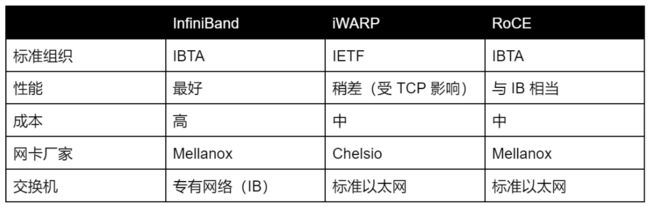
Infiniband 从协议到软硬件封闭,其性能虽然最优,但成本也最高,因为需要更换全套设备,包括网卡、光缆和交换机等。这对于通用标准化的分布式存储场景并不友好,在 ZBS 选择时首先被排除掉。
对于 RoCE 和 iWARP 选择上,虽然 RoCE 在数据重传和拥塞控制上受到 UDP 协议自身的限制,需要无损网络的环境支持,但在综合生态、协议效率和复杂度等多方面因素评估下,SmartX 更加看好 RoCE 未来的发展,在极致的性能诉求下,RoCE 也会比 iWARP 具有更强的潜力。当前 ZBS 存储内部数据同步网络采用的是 RoCEv2 的 RDMA 技术路线。

图 5:ZBS RDMA RoCEv2
性能验证数据
为了使测试数据有更直观的对比性(RDMA vs TCP/IP),将控制测试环境严格一致性,包括硬件配置、系统版本以及相关软件版本,唯一变量仅为开启/关闭存储内部数据同步 RDMA 能力,基于此,测试集群在两种状态下的性能表现。
环境信息
存储集群,由 3 节点组成,安装 SMTX OS 5.0,分层存储结构,所有存储节点的硬件配置相同,节点环境信息如下:

性能数据
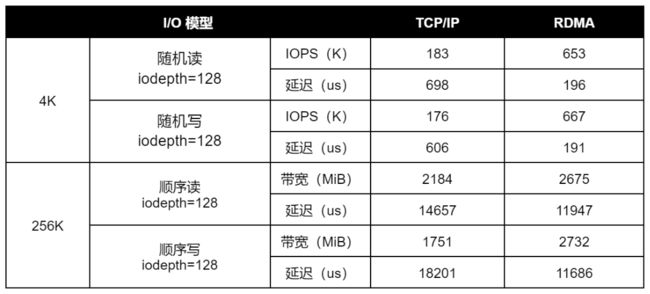
在相同的测试环境和测试方法下,分别使用 RDMA 和 TCP/IP 协议进行性能验证。为了更好地观测读写 I/O 跨节点的性能表现(ZBS 分布式存储默认具有数据本地化特点,对读 I/O 模型有明显优化作用),本次测试基于 Data Channel 平面(ZBS 内部的 RPC 通道,用于节点间收发数请求)。本测试仅用于评估网络性能差异,I/O 读写操作并不落盘。
性能对比数据
测试结论
通过以上基准测试数据,可以看出,相同软硬件环境以及测试方法下,使用 RDMA 作为存储内部数据同步协议,可以取得更优的 I/O 性能输出。其表现为更高的 4K 随机 IOPS 和更低的延时,以及在 256K 顺序读写场景,充分释放网络带宽(25GbE)条件,提供更高的数据吞吐表现。
总结
通过本篇文章的理论介绍和客观的性能测试数据,希望读者能够对于 RDMA 协议有了更加全面的了解。RDMA 对于数据跨网络通信性能的优化,已经应用于很多企业场景中,分布式存储作为其中一个重要场景,借助 RDMA 实现了存储内部数据同步效率的提升,进而为更高工作负载需求的业务应用提供了更好的存储性能表现。
参考文章:
1. RDMA over Converged Ethernet. Wikipedia.
https://en.wikipedia.org/wiki/RDMA_over_Converged_Ethernet
2. How Ethernet RDMA Protocols iWARP and RoCE Support NVMe over Fabrics.
https://www.snia.org/sites/default/files/ESF/How_Ethernet_RDMA_Protocols_Support_NVMe_over_Fabrics_Final.pdf
点击了解 SMTX ZBS 更多产品特性与技术实现亮点。