介绍 Qubole 的 Spark 调整工具
更新
Qubole 的 Spark 调优工具现已开源并命名为Sparklens。要做出贡献,请查看https://github.com/qubole/sparklens 的源代码。要使用Sparklens分析您的Spark应用程序,只需将以下附加配置参数添加到 spark-submit 或 spark-shell:
--packages qubole:sparklens:0.1.2-s_2.11
--conf spark.extraListeners=com.qubole.sparklens.QuboleJobListener
Spark已被证明是处理 TB 或更大的大型数据集的出色引擎。由于大规模分布式和并行化设置中的容错数据处理,其应用程序适用于从机器学习和高级分析到大规模 ETL 批量转换的所有领域。然而,Spark 的一个缺陷是它在配置和争论方面是一头野兽。如果操作不当,大规模运行不同工作负载所需的大量配置可能会使其不稳定。
现在,我们通过托管的自动扩展解决方案使这个过程更加自助化,以便在您首选的云基础设施中运行 Spark。为了实现这一使命,我们构建了一个基于 Spark 侦听器框架的工具,该工具仅通过查看应用程序的一次运行来提供有关给定 Spark 应用程序的洞察力。
用户在配置和运行Spark 应用程序时面临的常见问题之一是决定执行程序的数量或应用程序应使用的内核数量。通常,这个过程是通过反复试验来完成的,这需要时间并且需要运行超出正常使用范围的集群(读取浪费的资源)。此外,它没有告诉我们去哪里寻找进一步的改进。使用 Qubole 的 Spark Tuning Tool 来优化生产中的 Spark 作业。
2018年1月22日由罗希特Karlupia,Qubole和Shefali AGGARWAL 更新2021年9月4日
更新:Qubole 的 Spark 调优工具现已开源并命名为Sparklens。要做出贡献,请查看https://github.com/qubole/sparklens 的源代码。要使用Sparklens分析您的Spark应用程序,只需将以下附加配置参数添加到 spark-submit 或 spark-shell:
–packages qubole:sparklens:0.1.2-s_2.11
–conf spark.extraListeners=com.qubole.sparklens.QuboleJobListener
Apache Spark已被证明是处理 TB 或更大的大型数据集的出色引擎。由于大规模分布式和并行化设置中的容错数据处理,其应用程序适用于从机器学习和高级分析到大规模 ETL 批量转换的所有领域。然而,Spark 的一个缺陷是它在配置和争论方面是一头野兽。如果操作不当,大规模运行不同工作负载所需的大量配置可能会使其不稳定。
现在,我们通过托管的自动扩展解决方案使这个过程更加自助化,以便在您首选的云基础设施中运行 Spark。为了实现这一使命,我们构建了一个基于 Spark 侦听器框架的工具,该工具仅通过查看应用程序的一次运行来提供有关给定 Spark 应用程序的洞察力。
用户在配置和运行Spark 应用程序时面临的常见问题之一是决定执行程序的数量或应用程序应使用的内核数量。通常,这个过程是通过反复试验来完成的,这需要时间并且需要运行超出正常使用范围的集群(读取浪费的资源)。此外,它没有告诉我们去哪里寻找进一步的改进。使用 Qubole 的 Spark Tuning Tool 来优化生产中的 Spark 作业。
在看到应用程序运行一次后,该工具会告诉我们:
1.如果应用程序使用更多内核运行得更快。如果是这样,多快。
2.如果我们可以在不增加挂钟时间的情况下以更少的内核运行来节省计算成本。
3.即使我们给它无限的执行者,这个应用程序将花费的绝对最短时间。
4.如何使申请时间低于此最小值。

许多 Spark 应用程序在许多 executor 中什么都不做,并且很长一段时间内一直什么都不做。上图显示了 Spark 应用程序的时间线。x 轴是时间,y 轴是资源。具体来说,这张图片显示了三个执行器,每个执行器都有一个核心。蓝色和绿色区域代表正在积极使用的资源。红色区域表示资源没有完成有用的工作。这种“无所作为”的发生有以下三个原因:
驱动程序中的繁重处理
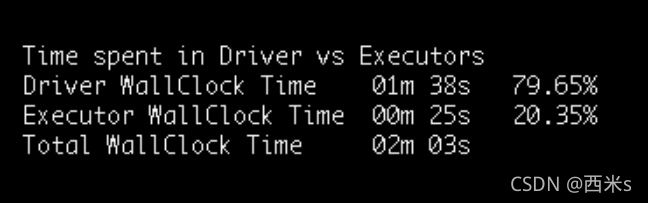
用户有时做的第一件次优的事情是构建他们的 Spark 应用程序来完成驱动程序中的大部分处理。在某些情况下,不是用户代码,而是其他一些组件,如 Hive 客户端加载表,导致驱动程序繁重的计算。从 Spark 的挂钟执行角度来看,应用程序可以分为不同的阶段。每个阶段要么在驱动程序上执行,要么在执行程序上执行。主要的收获是,当我们处于驱动程序阶段时,没有一个执行程序在做任何有用的工作。所以如果你有 100 个 executor 并且驱动程序忙了 1 分钟,那么浪费的有效计算资源是 100 分钟,每个 executor 1 分钟。我们的调优工具发出的第一个指标是在驱动程序中花费的挂钟时间的百分比。
以下是对驱动程序进行的一些常见操作:
1.文件列表和拆分计算。一般来说,它在 S3 上很慢。在 Qubole,我们进行了一些优化以使其更快。有关这些优化的详细信息,请参阅[第 1 部分](https://www.qubole.com/blog/optimizing-hadoop-for-s3-part-1/)和[第 2 部分](https://www.qubole.com/blog/optimizing-s3-bulk-listings-for-performant-hive-queries/)。
2.从 Spark加载配置单元表发生在驱动程序中。这在 HDFS 上效果很好,但在 S3 上它非常慢。在 Qubole,我们进行了重大改进,使 S3 上的 Spark 写入 hive 表的性能与 HDFS 一样可靠。
现在还有一些我们无法自动优化的东西。这包括诸如调用df 的用户代码之类的东西。收集所有数据到驱动程序中,然后在驱动程序中工作。有时这些东西是隐藏的,不是很明显。例如,Spark DataFrames 可以转换为 Pandas DataFrames,反之亦然。当然,问题在于 Pandas DataFrame 仅在驱动程序上处理,而 Spark DataFrames 在 Executors 上处理,因此可扩展。Qubole 的 Spark Tuning Tool 有助于使这些意外错误变得明显。
执行端利用率
Spark 应用程序效率低下的第二个来源来自执行器端浪费的 CPU 资源。造成这些低效率的原因有很多,但在解决主要是仅驱动程序计算的问题之前开始调查它们是没有意义的。Spark 应用程序的执行器利用率指标捕获了这种低效率的本质。执行器利用率不足的两个常见原因是:
1.没有足够的任务(即任务少于应用程序可用的内核数)
2.有偏差的任务,使得一些任务完成得非常快,而另一些则继续运行很长时间

很容易看出为什么第一个是一个问题。第二个是 Spark 如何调度阶段的问题。当子阶段依赖于某些父阶段集时,直到所有父阶段的所有任务都完成后才会调度子阶段。因此,不是任务的平均运行时间决定了总运行时间,而是父阶段中最大和最慢的任务决定了应用程序的运行时间。

预测最小、最大和理想挂钟时间
使用来自 Spark 事件侦听器的详细数据,Qubole Spark Tuning Tool 计算如下:
仅在一个执行程序上运行应用程序需要多长时间
使用无限执行程序运行时应用程序将花费多少时间
这两个数字一起为我们提供了应用程序挂钟时间的范围以及我们离这些时间的近或远。由于无限的执行者花费了无限的金钱,因此我们可以通过调整执行者的数量来确定我们可以使应用程序运行的速度的下限。这些边界条件可以作为参考检查来指导下一级调查。这个练习的目的是让额外执行者的投资回报率非常明显。该工具实际上为不同的执行程序计数计算挂钟时间,而不仅仅是两个极端,以预测添加执行程序没有意义的时间点。

通常很容易在此工具和调度理论之间进行比较。具体来说,任务 DAG 的关键路径的概念得到了相当的研究。不同之处在于调度理论将任务大小和任务数量视为给定的事实,而像 Spark 这样灵活的东西,可以通过仔细地进行配置和代码更改来构建任务,以生成具有更好的调度特性。
我们怎样才能做得更好?深层发掘
有时上一步产生的边界条件不够好。该工具发布的其他指标之一是“理想”应用程序的挂钟时间。理想的应用程序是以 100% 的执行程序利用率运行的应用程序。这个数字设定了下一级目标,以推动应用程序向“理想”应用程序进行调整。如果您是编写 Spark 应用程序的团队的经理,定期查看这些统计数据将有助于您了解不优化这些应用程序还剩下多少钱。它将帮助您在将开发人员时间用于优化应用程序与在计算账单上花钱之间进行权衡。
要弄清楚的关键特征是每个阶段的任务(我们有足够的任务)和每个阶段的倾斜(任务是统一的还是倾斜的)。然后,根据是否值得进一步调整,花时间解决这些问题。如前所述,Spark 只有在一个阶段中的所有任务都结束后才会进入下一阶段。因此,一个落后的任务可能会以一种浪费的方式占用所有资源,直到这个最慢的任务完成。调整工具不会修复所有阶段的偏差问题,而是将您指向占据大部分挂钟时间的阶段。如果 50% 的时间花在一个阶段,我们可以专注于这一阶段,而不是担心工作的所有阶段。
该工具在每个阶段打印的四个重要指标是:
- PRatio:阶段中的并行性。越高越好。
- TaskSkew:阶段中的倾斜,特别是最大任务时间与中间任务时间的比率。越低越好
- StageSkew:最大任务与总阶段时间的比率。越低越好。
- OIRatio:阶段中的输出输入比。我们是否创造了太多的临时输出?
根据这些值,我们可以采取不同的操作,例如确保足够的并行度、处理偏斜或修改 Spark 应用程序以减少临时数据,或者如果没有别的,交易执行时间以换取金钱并以更少的执行者运行作业以获得更好的集群利用率。
Qubole Spark Tuning Tool 也适用于 Notebooks。您不仅可以分析 Spark 应用程序,还可以在开发阶段通过逐段分析每个代码片段来使用它。它适用于 Python 和 Scala。

我们刚刚开始了这条解构 Spark 应用程序调优的路径。在第一个版本中,我们主要着眼于以执行器内核和挂钟时间作为关键评估标准来优化 Spark 应用程序。其他变量,如执行器 JVM 堆大小和 Spark 中的内部内存分配,没有被探索。我们将在该工具的下一个版本中讨论这些问题。继续关注这个空间。
要根据您的数据自行测试Spark Tuning 工具,请通过www.qubole.com 注册以创建您的免费帐户。Qubole 数据服务(QDS) 商业版免费提供,但使用量限制为每月 10,000 Qubole 计算单位小时 (QCUH)(价值 1000 美元)。每个 QDS 账户可以使用任意数量的云优化数据引擎;包括 Spark、Hadoop、Hive 和 Presto 来支持查询。要使用 QDS,上手非常简单,在处理工作负载之前,您无需从 S3 或其他 AWS 数据存储库中的账户迁移任何数据。
翻译自:《介绍 Qubole 的 Spark 调整工具》