各主要城市数据分析岗位薪资水平分析
各主要城市数据分析岗位薪资水平分析
一、项目背景
由于个人考虑转行数据分析,故通过对招聘信息数据的分析,了解该岗位的市场需求、行业分布、薪资水平,以便明确求职方向
二、数据获取
数据来源于boss直聘网,通过爬虫采集
采集的城市主要为一线、新一线等较为发达的城市
爬虫代码如下:
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome(r'D:\PycharmProjects\python_present\boss直聘爬取\chromedriver.exe')
cities = [{"name": "北京", "code": 101010100, "url": "/beijing/"},
{"name": "上海", "code": 101020100, "url": "/shanghai/"},
{"name": "广州", "code": 101280100, "url": "/guangzhou/"},
{"name": "深圳", "code": 101280600, "url": "/shenzhen/"},
{"name": "杭州", "code": 101210100, "url": "/hangzhou/"},
{"name": "天津", "code": 101030100, "url": "/tianjin/"},
{"name": "苏州", "code": 101190400, "url": "/suzhou/"},
{"name": "武汉", "code": 101200100, "url": "/wuhan/"},
{"name": "厦门", "code": 101230200, "url": "/xiamen/"},
{"name": "长沙", "code": 101250100, "url": "/changsha/"},
{"name": "成都", "code": 101270100, "url": "/chengdu/"},
{"name": "郑州", "code": 101180100, "url": "/zhengzhou/"},
{"name": "重庆", "code": 101040100, "url": "/chongqing/"},
{"name": "青岛", "code": 101120200, "url": "/qingdao/"},
{"name": "南京", "code": 101190100, "url": "/nanjing/"}]
for city in cities:
urls = ['https://www.zhipin.com/c{}/?query=数据分析&page={}&ka=page-{}'.format(city['code'], i, i) for i in
range(1, 8)]
for url in urls:
driver.get(url)
html = driver.page_source
bs = BeautifulSoup(html, 'html.parser')
job_all = bs.find_all('div', {"class": "job-primary"})
for job in job_all:
position = job.find('span', {"class": "job-name"}).get_text()
address = job.find('span', {'class': "job-area"}).get_text()
company = job.find('div', {'class': 'company-text'}).find('h3', {'class': "name"}).get_text()
salary = job.find('span', {'class': 'red'}).get_text()
diploma = job.find('div', {'class': 'job-limit'}).find('p').get_text()[-2:]
experience = job.find('div', {'class': 'job-limit'}).find('p').get_text()[:-2]
labels = job.find('a', {'class': 'false-link'}).get_text()
with open('position.csv', 'a+', encoding='UTF-8-SIG') as f_obj:
f_obj.write(position.replace(',', '、') + "," + address + "," + company + "," + salary + "," + diploma
+ "," + experience + ',' + labels + "\n")
driver.quit()
三、数据清洗
In [59]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
from scipy.stats import norm,mode
import re
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
原数据没有字段名,设置字段名:
position:岗位名
address:公司所在地区
company:公司名
salary:薪水
diploma:学历要求
experience:工作经验要求
lables:行业标签
In [60]:
df = pd.read_csv('job.csv',header=None,names=['position','address','company','salary','diploma','experience','lables'])
查看数据整体情况
In [61]:
df.head()
Out[61]:
| position | address | company | salary | diploma | experience | lables | |
|---|---|---|---|---|---|---|---|
| 0 | 数据分析 | 北京·朝阳区·亚运村 | 中信百信银行 | 25-40K·15薪 | 本科 | 5-10年 | 银行 |
| 1 | 数据分析 | 北京·朝阳区·太阳宫 | BOSS直聘 | 25-40K·16薪 | 博士 | 1-3年 | 人力资源服务 |
| 2 | 数据分析 | 北京·朝阳区·鸟巢 | 京东集团 | 50-80K·14薪 | 本科 | 3-5年 | 电子商务 |
| 3 | 数据分析 | 北京·海淀区·清河 | 一亩田 | 15-25K | 本科 | 3-5年 | O2O |
| 4 | 数据分析岗 | 北京·海淀区·西北旺 | 建信金科 | 20-40K·14薪 | 硕士 | 5-10年 | 银行 |
In [62]:
df.shape
Out[62]:
(3045, 7)In [63]:
df.info()
RangeIndex: 3045 entries, 0 to 3044
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 position 3045 non-null object
1 address 3045 non-null object
2 company 3045 non-null object
3 salary 3045 non-null object
4 diploma 3045 non-null object
5 experience 3045 non-null object
6 lables 3045 non-null object
dtypes: object(7)
memory usage: 83.3+ KB
发现有45行重复数据,进行删除
In [64]:
df.duplicated().sum()
Out[64]:
45In [65]:
df.drop_duplicates(keep='first',inplace=True)
In [66]:
df.duplicated().sum()
Out[66]:
0In [67]:
df.shape
Out[67]:
(3000, 7)In [68]:
df.isnull().sum()
Out[68]:
position 0
address 0
company 0
salary 0
diploma 0
experience 0
lables 0
dtype: int64考虑到数据中有实习岗位,实习岗薪资按天算,不具有太大的参考价值,故删除包含实习的数据
In [69]:
#df['position'] = df['position'].astype('string')
In [70]:
x=df['position'].str.contains('实习')
df=df[~x]
df.reset_index(drop=True,inplace=True)
address列的值不规范,进行处理,全部转换为城市名
In [71]:
df['address']=df['address'].str[:2]
In [72]:
df['address'].unique()
Out[72]:
array(['北京', '上海', '广州', '深圳', '杭州', '天津', '苏州', '武汉', '厦门', '长沙', '成都',
'郑州', '重庆', '青岛', '南京'], dtype=object)观察salary列的值
In [73]:
df['salary'].unique()
Out[73]:
array(['25-40K·15薪', '25-40K·16薪', '50-80K·14薪', '15-25K', '20-40K·14薪',
'15-30K·14薪', '20-30K', '15-25K·14薪', '40-55K·13薪', '20-35K',
'30-55K·13薪', '20-40K·16薪', '35-40K·15薪', '45-65K', '15-30K',
'25-50K·14薪', '25-35K·14薪', '15-25K·16薪', '15-28K·14薪', '18-28K',
'30-50K·13薪', '20-35K·14薪', '15-28K', '20-30K·13薪', '30-50K·16薪',
'18-30K·14薪', '18-22K·15薪', '25-45K·16薪', '13-25K', '14-25K·14薪',
'18-35K·14薪', '25-45K·14薪', '25-40K', '15-26K·13薪', '12-24K',
'25-45K', '20-40K', '20-30K·15薪', '15-25K·15薪', '25-40K·17薪',
'20-30K·14薪', '18-35K', '18-27K', '30-45K', '20-40K·15薪',
'20-30K·16薪', '25-30K·15薪', '17-27K', '28-50K·14薪', '25-35K',
'30-60K·14薪', '30-55K', '35-60K·14薪', '15-22K', '30-50K',
'30-50K·14薪', '40-70K', '30-60K·13薪', '25-50K·15薪', '13-26K·16薪',
'25-50K', '12-24K·14薪', '17-25K·15薪', '18-25K·15薪', '28-40K·16薪',
'30-40K', '28-40K·13薪', '20-25K·16薪', '30-60K·16薪', '25-30K·14薪',
'15-30K·15薪', '25-40K·14薪', '35-65K·16薪', '30-45K·14薪',
'20-35K·16薪', '15-30K·16薪', '35-65K·15薪', '25-26K', '20-25K',
'25-50K·16薪', '18-35K·16薪', '18-25K·14薪', '25-30K', '19-35K',
'12-22K·14薪', '28-45K·14薪', '18-30K', '18-25K', '15-25K·13薪',
'15-25K·17薪', '15-30K·13薪', '40-60K·15薪', '18-30K·15薪',
'25-40K·13薪', '25-30K·13薪', '20-35K·15薪', '18-24K', '30-60K',
'40-70K·14薪', '18-30K·13薪', '16-25K·13薪', '20-28K·15薪',
'15-20K·13薪', '15-20K·14薪', '12-18K', '11-20K', '20-40K·13薪',
'14-28K', '11-17K·13薪', '15-20K', '9-14K', '12-15K', '11-22K',
'10-15K', '12-20K', '12-17K', '9-13K·13薪', '10-15K·14薪',
'10-15K·13薪', '7-12K·14薪', '10-11K', '6-9K', '10-12K',
'20-25K·14薪', '8-10K·13薪', '9-13K·14薪', '7-10K', '7-10K·13薪',
'20-35K·13薪', '25-35K·16薪', '30-40K·13薪', '30-50K·15薪',
'30-60K·15薪', '12-20K·14薪', '28-55K', '23-45K', '8-13K',
'30-35K·15薪', '30-45K·16薪', '15-28K·15薪', '60-90K·16薪', '40-60K',
'30-35K', '12-24K·16薪', '16-30K·15薪', '11-15K·15薪', '15-16K',
'6-10K·13薪', '4-8K', '5-7K', '4-6K', '4-7K', '8-13K·13薪',
'14-20K·13薪', '18-28K·16薪', '6-8K', '35-50K', '11-18K', '6-10K',
'25-35K·15薪', '5-10K·13薪', '8-10K', '5-10K', '12-17K·14薪',
'11-20K·13薪', '10-13K·14薪', '8-12K', '13-25K·14薪', '11-22K·18薪',
'28-40K·14薪', '3-6K', '12-22K', '5-8K', '9-14K·16薪', '13-20K',
'14-20K·14薪', '15-17K·13薪', '5-6K', '6-8K·13薪', '15-17K', '3-5K',
'6-7K·13薪', '18-35K·15薪', '3-4K', '8-13K·14薪', '8-12K·13薪',
'7-12K·13薪', '4-5K', '9-14K·13薪', '5-9K', '12-18K·13薪',
'20-25K·15薪', '9-11K', '8-16K', '13-23K', '14-25K', '7-12K',
'12-15K·13薪', '3-5K·13薪', '12-24K·13薪', '16-23K', '6-10K·15薪',
'11-16K', '7-11K', '16-22K·13薪', '10-20K', '14-22K', '60-90K',
'30-35K·14薪', '35-50K·16薪', '13-22K·14薪', '5-8K·13薪', '10-15K·16薪',
'5-6K·13薪', '13-25K·13薪', '8-11K', '13-26K', '16-32K', '16-28K',
'80-110K·14薪', '9-13K', '12-16K', '21-22K', '20-40K·18薪', '16-30K',
'30-55K·16薪', '11-16K·13薪', '70-100K·14薪', '15-22K·13薪',
'18-25K·13薪', '20-21K', '10-15K·15薪', '9-12K', '23-45K·16薪',
'25-50K·13薪', '25-30K·20薪', '35-50K·15薪', '30-40K·18薪',
'40-70K·16薪', '15-26K', '14-28K·14薪', '18-22K', '35-65K', '15-21K',
'30-55K·18薪', '12-20K·13薪', '21-35K·16薪', '15-30K·17薪', '4-9K',
'9-14K·15薪', '20-40K·17薪', '18-36K', '6-8K·15薪', '4-6K·13薪',
'25-35K·13薪', '16-30K·14薪', '22-27K', '11-18K·13薪', '18-26K',
'28-50K·13薪', '35-40K', '20-24K', '17-25K', '13-21K·13薪',
'12-20K·17薪', '12-24K·15薪', '15-22K·14薪', '12-18K·15薪',
'30-50K·18薪', '8-13K·15薪', '65-95K', '24-38K', '6-11K·13薪',
'6-11K', '9-15K', '11-15K', '7-8K', '8-9K', '2-5K', '7-11K·13薪',
'6-7K', '4-8K·13薪', '3-4K·13薪', '3-7K', '12-13K·13薪', '12-17K·15薪',
'7-9K', '14-28K·13薪', '8-15K', '9-11K·13薪', '10-12K·13薪', '8-14K',
'12-18K·14薪', '4-5K·13薪', '9-14K·14薪', '12-16K·13薪', '5-8K·15薪',
'5-10K·14薪', '11-20K·14薪', '12-20K·15薪', '17-30K·15薪', '6-9K·14薪',
'15-18K·13薪', '40-70K·13薪', '11-22K·14薪', '12-22K·15薪', '15-23K',
'18-23K', '14-28K·15薪', '35-50K·14薪', '50-80K', '13-20K·15薪',
'15-20K·15薪', '6-8K·14薪', '17-30K', '7-8K·13薪', '10-13K',
'4-6K·14薪', '2-4K', '6-12K', '6-11K·14薪', '10-13K·13薪',
'8-12K·14薪', '5-7K·13薪', '35-50K·13薪', '11-12K', '4-5K·14薪',
'10-13K·15薪', '27-40K', '16-25K·14薪', '12-22K·13薪', '11-22K·13薪',
'5-9K·13薪', '13-21K', '13-17K', '11-20K·15薪', '11-19K', '14-18K',
'11-20K·17薪', '3-8K', '13-18K', '10-20K·18薪', '8-11K·13薪',
'45-60K·15薪', '13-26K·14薪', '13-20K·14薪', '15-16K·13薪',
'11-18K·14薪', '2-6K', '8-10K·14薪', '3-5K·14薪', '2-3K',
'10-11K·16薪', '18-20K', '12-13K', '12-13K·15薪', '2-7K',
'8-12K·15薪', '15-30K·18薪', '6-7K·14薪', '5-8K·16薪', '18-22K·18薪',
'11-16K·15薪', '15-25K·20薪', '18-35K·13薪', '14-20K', '13-16K',
'4-7K·13薪', '10-12K·15薪', '7-14K', '12-14K', '3-7K·13薪',
'7-10K·14薪', '22-40K', '4-6K·15薪', '15-24K', '13-22K·16薪',
'26-50K', '10-18K', '6-9K·13薪', '14-15K·14薪', '9-10K', '3-6K·13薪',
'4-9K·13薪', '16-20K·13薪', '12-23K', '1-4K', '11-16K·14薪',
'13-18K·13薪', '12-15K·15薪', '20-28K·13薪', '6-10K·14薪',
'12-17K·13薪', '13-15K', '13-14K', '11-20K·16薪', '50-60K',
'5-7K·14薪', '10-15K·17薪', '13-20K·13薪', '4-9K·14薪', '17-34K',
'20-25K·19薪'], dtype=object)将薪资列的值进行拆分,新增bottom,top两列,作为一个岗位薪资的最低值和最高值
In [74]:
df['bottom']=df['salary'].str.extract('^(\d+).*')
In [75]:
df['top']=df['salary'].str.extract('^.*?-(\d+).*')
有些公司的薪资是单个值,则用bottom列的值填充top列
In [76]:
df['top'].fillna(df['bottom'],inplace=True)
In [77]:
df
Out[77]:
| position | address | company | salary | diploma | experience | lables | bottom | top | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 数据分析 | 北京 | 中信百信银行 | 25-40K·15薪 | 本科 | 5-10年 | 银行 | 25 | 40 |
| 1 | 数据分析 | 北京 | BOSS直聘 | 25-40K·16薪 | 博士 | 1-3年 | 人力资源服务 | 25 | 40 |
| 2 | 数据分析 | 北京 | 京东集团 | 50-80K·14薪 | 本科 | 3-5年 | 电子商务 | 50 | 80 |
| 3 | 数据分析 | 北京 | 一亩田 | 15-25K | 本科 | 3-5年 | O2O | 15 | 25 |
| 4 | 数据分析岗 | 北京 | 建信金科 | 20-40K·14薪 | 硕士 | 5-10年 | 银行 | 20 | 40 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2921 | 助理数据分析员 | 南京 | 万得 | 4-6K | 本科 | 经验不限 | 数据服务 | 4 | 6 |
| 2922 | 数据分析师(经济) | 南京 | 万得 | 4-6K | 本科 | 经验不限 | 数据服务 | 4 | 6 |
| 2923 | (金融)数据分析员 | 南京 | 万得 | 4-6K | 本科 | 经验不限 | 数据服务 | 4 | 6 |
| 2924 | 数据分析员 | 南京 | 万得 | 4-6K | 本科 | 1年以内 | 数据服务 | 4 | 6 |
| 2925 | 助理数据分析员 | 南京 | 万得 | 4-8K | 本科 | 经验不限 | 数据服务 | 4 | 8 |
2926 rows × 9 columns
有些公司有标明年终奖,如14薪等,故新增一列commission_pct作为奖金率,并计算每个岗位的奖金率
In [78]:
df['commision_pct']=df['salary'].str.extract('^.*?·(\d{2})薪')
df['commision_pct'].fillna(12,inplace=True)
df['commision_pct']=df['commision_pct'].astype('float64')
df['commision_pct']=df['commision_pct']/12
将bottom,top,commission__pct列转换为数值形式,并以此计算出每个岗位的平均薪资作为新增列avg_salary
In [79]:
df['bottom'] = df['bottom'].astype('int64')
df['top'] = df['top'].astype('int64')
df['avg_salary'] = (df['bottom']+df['top'])/2*df['commision_pct']
df['avg_salary'] = df['avg_salary'].astype('int64')
In [80]:
df.head()
Out[80]:
| position | address | company | salary | diploma | experience | lables | bottom | top | commision_pct | avg_salary | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 数据分析 | 北京 | 中信百信银行 | 25-40K·15薪 | 本科 | 5-10年 | 银行 | 25 | 40 | 1.250000 | 40 |
| 1 | 数据分析 | 北京 | BOSS直聘 | 25-40K·16薪 | 博士 | 1-3年 | 人力资源服务 | 25 | 40 | 1.333333 | 43 |
| 2 | 数据分析 | 北京 | 京东集团 | 50-80K·14薪 | 本科 | 3-5年 | 电子商务 | 50 | 80 | 1.166667 | 75 |
| 3 | 数据分析 | 北京 | 一亩田 | 15-25K | 本科 | 3-5年 | O2O | 15 | 25 | 1.000000 | 20 |
| 4 | 数据分析岗 | 北京 | 建信金科 | 20-40K·14薪 | 硕士 | 5-10年 | 银行 | 20 | 40 | 1.166667 | 35 |
In [81]:
cols=list(df)
cols.insert(4,cols.pop(cols.index('bottom')))
cols.insert(5,cols.pop(cols.index('top')))
cols.insert(6,cols.pop(cols.index('commision_pct')))
cols.insert(7,cols.pop(cols.index('avg_salary')))
df=df.loc[:,cols]
df
Out[81]:
| position | address | company | salary | bottom | top | commision_pct | avg_salary | diploma | experience | lables | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 数据分析 | 北京 | 中信百信银行 | 25-40K·15薪 | 25 | 40 | 1.250000 | 40 | 本科 | 5-10年 | 银行 |
| 1 | 数据分析 | 北京 | BOSS直聘 | 25-40K·16薪 | 25 | 40 | 1.333333 | 43 | 博士 | 1-3年 | 人力资源服务 |
| 2 | 数据分析 | 北京 | 京东集团 | 50-80K·14薪 | 50 | 80 | 1.166667 | 75 | 本科 | 3-5年 | 电子商务 |
| 3 | 数据分析 | 北京 | 一亩田 | 15-25K | 15 | 25 | 1.000000 | 20 | 本科 | 3-5年 | O2O |
| 4 | 数据分析岗 | 北京 | 建信金科 | 20-40K·14薪 | 20 | 40 | 1.166667 | 35 | 硕士 | 5-10年 | 银行 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2921 | 助理数据分析员 | 南京 | 万得 | 4-6K | 4 | 6 | 1.000000 | 5 | 本科 | 经验不限 | 数据服务 |
| 2922 | 数据分析师(经济) | 南京 | 万得 | 4-6K | 4 | 6 | 1.000000 | 5 | 本科 | 经验不限 | 数据服务 |
| 2923 | (金融)数据分析员 | 南京 | 万得 | 4-6K | 4 | 6 | 1.000000 | 5 | 本科 | 经验不限 | 数据服务 |
| 2924 | 数据分析员 | 南京 | 万得 | 4-6K | 4 | 6 | 1.000000 | 5 | 本科 | 1年以内 | 数据服务 |
| 2925 | 助理数据分析员 | 南京 | 万得 | 4-8K | 4 | 8 | 1.000000 | 6 | 本科 | 经验不限 | 数据服务 |
2926 rows × 11 columns
再次查看数据,发现极端异常值,月薪1000和月薪10万
这些极端值数量都很少,剔除月薪小于2000大于55000的数据
In [82]:
df.describe()
Out[82]:
| bottom | top | commision_pct | avg_salary | |
|---|---|---|---|---|
| count | 2926.000000 | 2926.000000 | 2926.000000 | 2926.000000 |
| mean | 11.980861 | 20.058442 | 1.057929 | 17.056391 |
| std | 7.841004 | 13.824406 | 0.100427 | 12.582388 |
| min | 1.000000 | 3.000000 | 1.000000 | 2.000000 |
| 25% | 6.000000 | 9.000000 | 1.000000 | 7.000000 |
| 50% | 10.000000 | 15.000000 | 1.000000 | 13.000000 |
| 75% | 15.000000 | 30.000000 | 1.083333 | 23.000000 |
| max | 80.000000 | 110.000000 | 1.666667 | 110.000000 |
In [83]:
df=df[(df.avg_salary>2)&(df.avg_salary<55)]
In [84]:
df['diploma'].unique()
Out[84]:
array(['本科', '博士', '硕士', '不限', '大专', '高中', '中技'], dtype=object)对experience列进行清洗
In [85]:
df['experience'].unique()
Out[85]:
array(['5-10年', '1-3年', '3-5年', '经验不限', '5-10年学历', '3-5年学历', '经验不限学历',
'在校/应届', '1-3年学历', '1年以内', '10年以上', '1年以内学历', '1-3年中专/', '经验不限中专/',
'1年以内中专/'], dtype=object)In [86]:
df['experience'].replace('5-10年学历','5-10年',inplace=True)
df['experience'].replace('3-5年学历','3-5年',inplace=True)
df['experience'].replace('经验不限学历','经验不限',inplace=True)
df['experience'].replace('1-3年学历','1-3年',inplace=True)
df['experience'].replace('1年以内学历','1年以内',inplace=True)
df['experience'].replace('经验不限中专/','经验不限',inplace=True)
df['experience'].replace('1年以内中专/','1年以内',inplace=True)
df['experience'].replace('1-3年中专/','1-3年',inplace=True)
df['experience'].unique()
Out[86]:
array(['5-10年', '1-3年', '3-5年', '经验不限', '在校/应届', '1年以内', '10年以上'],
dtype=object)In [87]:
df['diploma'].unique()
Out[87]:
array(['本科', '博士', '硕士', '不限', '大专', '高中', '中技'], dtype=object)In [88]:
df['diploma'].value_counts()
Out[88]:
本科 2153
大专 487
硕士 142
不限 74
中技 10
高中 8
博士 6
Name: diploma, dtype: int64In [89]:
pd.set_option('max_row',100)
观察lables列,对数量较少且为传统行业的数据归入其他行业
In [90]:
df['lables'].value_counts()
Out[90]:
互联网 729
计算机软件 285
移动互联网 269
电子商务 247
数据服务 111
互联网金融 87
游戏 80
在线教育 75
生活服务 72
O2O 69
医疗健康 68
贸易/进出口 52
其他行业 49
企业服务 46
银行 43
物流/仓储 39
通信/网络设备 30
信息安全 29
批发/零售 29
智能硬件 26
环保 25
服装/纺织/皮革 25
咨询 24
食品/饮料/烟酒 21
新零售 21
培训机构 20
广告营销 18
计算机服务 17
人力资源服务 17
社交网络 16
工程施工 15
家具/家电/家居 15
广告/公关/会展 13
医疗/护理/卫生 13
电子/半导体/集成电路 12
其他服务业 9
旅游 9
餐饮 9
汽车生产 9
交通/运输 9
证券/期货 8
制药 7
医疗设备/器械 7
仪器仪表/工业自动化 6
其他专业服务 6
投资/融资 6
日化 6
机械设备/机电/重工 6
新能源 6
文化/体育/娱乐 5
房地产开发 5
装修装饰 4
音乐/视频/阅读 4
检测/认证 3
学术/科研 3
运营商/增值服务 3
农/林/牧/渔 3
地产经纪/中介 3
租赁/拍卖/典当/担保 3
基金 2
4S店/后市场 2
美容/美发 2
汽车零部件 2
电力/热力/燃气/水利 2
建筑设计 2
建材 2
专利/商标/知识产权 2
分类信息 2
物业服务 2
计算机硬件 2
酒店 2
印刷/包装/造纸 1
玩具/礼品 1
石油/石化 1
政府/公共事业 1
化工 1
广播/影视 1
非盈利机构 1
能源/化工/环保 1
媒体 1
法律 1
Name: lables, dtype: int64In [91]:
df.loc[~df['lables'].isin(['互联网','计算机软件','移动互联网','电子商务','数据服务',
'互联网金融','游戏','在线教育','生活服务','O2O','医疗健康','贸易/进出口','企业服务','银行']),'lables']='其他行业'
In [92]:
df['lables'].value_counts()
Out[92]:
互联网 729
其他行业 647
计算机软件 285
移动互联网 269
电子商务 247
数据服务 111
互联网金融 87
游戏 80
在线教育 75
生活服务 72
O2O 69
医疗健康 68
贸易/进出口 52
企业服务 46
银行 43
Name: lables, dtype: int64四、可视化及简要分析
In [99]:
df.avg_salary.groupby(df['address']).agg(['mean','median']).plot.bar(figsize=(16,8))
Out[99]:
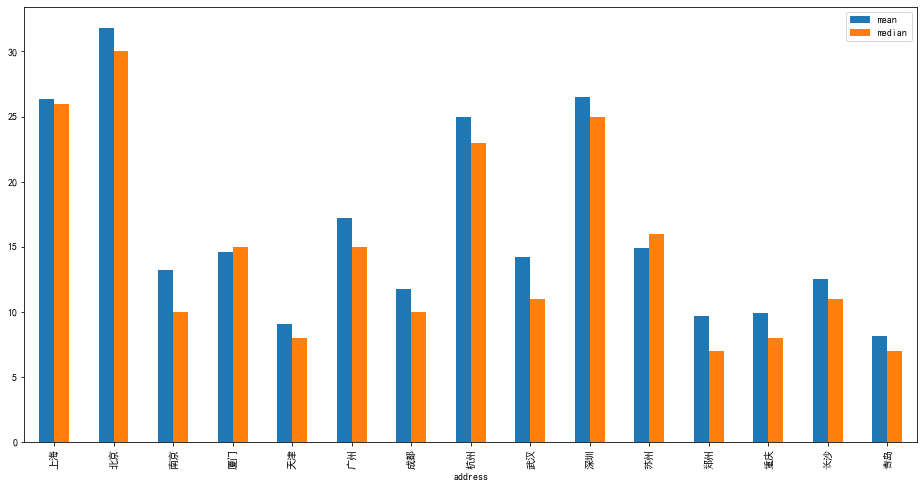
通过上图,可以发现各个城市的均值与中位数差距不大,但是城市之间区别非常大
北上深杭这四个城市的工资水平远远高于其他城市,广州苏州稍为靠后
靠前的这几个城市也是全国经济最为发达的几个城市,而且都发布在东部
中部城市薪资水平普遍低一些
In [108]:
fig=plt.figure(figsize=(12,6),dpi=80)
plt.hist(df['avg_salary'],bins=30,color='#f59311',alpha=0.3,edgecolor='k')
plt.ylabel('岗位数',fontsize=15)
plt.xlabel('薪资',fontsize=15)
plt.xticks(list(range(0,60,5)))
plt.show()
通过上图可以观察到,从总体来看,这个岗位少部分人拿着极高的工资
他们拉高了整个岗位的平均水平
月薪一万至两万的岗位不在少数
然而四千至五千的岗位居然是最多的,那么这些岗位主要是分布在哪些地区或行业呢,下面尝试进行分析
In [128]:
plt.figure(figsize=(16,16),dpi=80)
plt.subplot(121)
temp = df[df.avg_salary<10].groupby('address').avg_salary.count()
plt.pie(temp,labels=temp.index,autopct='% .2f%%')
plt.legend()
plt.title('薪资小于6K各城市占比')
plt.subplot(122)
temp = df[df.avg_salary>10].groupby('address').avg_salary.count()
plt.pie(temp,labels=temp.index,autopct='% .2f%%')
plt.title('薪资大于6K各城市占比')
plt.legend()
Out[128]:
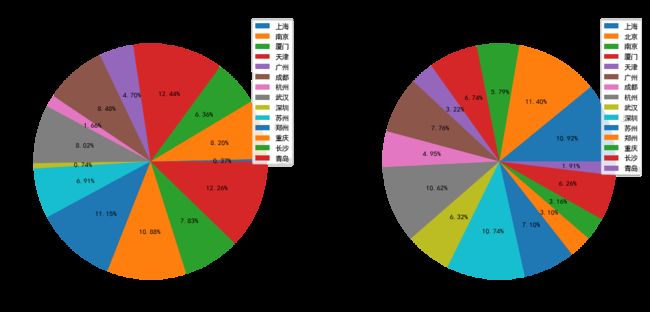
从以上饼图可以看到,各城市间薪资水平差异非常大,薪资水平小于6k的岗位主要集中分布于重庆、郑州、成都、武汉等中西部城市;而北上广深杭等城市基本不存在薪资水平小于6K的情况;而薪资水平大于6K的岗位分布区别则非常明显,北上广深杭的所占比重直接升至10%以上,重庆、郑州、成都、武汉等城市所占比重则减少到3%左右,由此可见,低薪岗位主要分布于中西部城市。
In [37]:
data1=df[df.address=='北京']['avg_salary']
data2=df[df.address=='上海']['avg_salary']
data3=df[df.address=='广州']['avg_salary']
data4=df[df.address=='深圳']['avg_salary']
data5=df[df.address=='杭州']['avg_salary']
plt.figure(figsize=(12,6),dpi=80)
plt.boxplot([data1,data2,data3,data4,data5],labels=['北京','上海','广州','深圳','杭州'],
flierprops={'marker':'o','markerfacecolor':'r','color':'k'},
patch_artist=True,boxprops={'color':'k','facecolor':'#FFFACD'})
ax=plt.gca()
ax.patch.set_facecolor('#FFFAFA')
ax.patch.set_alpha(0.8)
plt.title('主要城市薪资水平箱线图',fontsize=15)
plt.ylabel('薪资(单位:k)',fontsize=12)
plt.show()
选取薪资水平较高的五个城市进行分析
可以发现,北京的薪资水平是最高的,无论是最低值还是最高值,而且均分布在较高的水平
相对来说,杭州上海深圳两级分化最为严重
In [38]:
d = df['avg_salary'].groupby(df['diploma'])
d_avg = d.mean()
c = list(d_avg.index)
v = list(range(1,len(c)+1))
w = d_avg.values.astype('int64')
x = d.median().values.astype('int64')
move = 0.4
plt.figure(figsize=(14,8),dpi=80)
plt.bar(v,w,width=move,color='#eed777')
plt.bar([i+move for i in v],x,width=move,color='#334f65')
a = np.arange(0,7)+1.2
plt.xticks(a,c)
plt.yticks(list(range(0,40,5)))
plt.legend(['均值','中位数'])
plt.title('各学历薪资均值及中位数比较图',fontsize=16)
plt.xlabel('学历',fontsize = 12)
plt.ylabel('薪资(单位K)',fontsize = 12)
for e,f in zip(v,w):
plt.text(e,f,'{}k'.format(f),ha='center',fontsize=12)
for g,h in zip([i+move for i in v],x):
plt.text(g,h,'{}k'.format(h),ha='center',fontsize=12)
plt.show()
从学历方面来看,本科是一个分水岭
是否是本科,对薪资水平的影响还是很大的
而本科与硕士之间并没有特别大的差距
博士的薪资水平远远高于其他学历
In [39]:
data = df['diploma'].value_counts()
y=data.values
plt.figure(figsize=(10,10),dpi=80)
plt.pie(y,labels=data.index,autopct='%.1f %%')
plt.show()

从市场需求来看,要求本科占据绝大多数
该岗位对学历的门槛并不是很高,要求硕士的较少,而博士则是凤毛麟角
不过这也从侧面反映了社会上学历的分布状况,本科生及大专生占绝对多数
虽然市场需求量大,但是本科生就业压力也很大
In [40]:
d = df['avg_salary'].groupby(df['experience'])
d_avg = d.mean()
c = list(d_avg.index)
v = list(range(1,len(c)+1))
w = d_avg.values.astype('int64')
x = d.median().values.astype('int64')
move = 0.4
plt.figure(figsize=(14,8),dpi=80)
plt.bar(v,w,width=move,color='#002c53')
plt.bar([i+move for i in v],x,width=move,color='#0c84c6')
a = np.arange(0,7)+1.2
plt.xticks(a,c)
plt.yticks(list(range(0,40,5)))
plt.legend(['均值','中位数'])
plt.title('各工作年限薪资均值及中位数比较图',fontsize=16)
plt.xlabel('工作经验',fontsize = 12)
plt.ylabel('薪资(单位K)',fontsize = 12)
for e,f in zip(v,w):
plt.text(e,f,'{}k'.format(f),ha='center',fontsize=12)
for g,h in zip([i+move for i in v],x):
plt.text(g,h,'{}k'.format(h),ha='center',fontsize=12)
plt.show()
应届生的工资还是比较低的,和工作经验一年内的差距并不大
但是随着工作年限的增加,迈过3年工作经验这个门槛,工资水平将直线上升
说明这个岗位是一个需要累积丰富经验的岗位
In [41]:
data = df['experience'].value_counts()
y=data.values
plt.figure(figsize=(10,10),dpi=80)
plt.pie(y,labels=data.index,autopct='%.1f %%')
plt.show()
我们发现,市场上对于工作经验的要求还是很强烈的
1-5年的经验要求占绝大多数
而应届生和10年以上的需求则非常少
工作经验是入职成功与否的关键因素
In [42]:
d = df['avg_salary'].groupby(df['lables'])
d_avg = d.mean()
c = list(d_avg.index)
v = list(range(1,len(c)+1))
w = d_avg.values.astype('int64')
x = d.median().values.astype('int64')
move = 0.4
plt.figure(figsize=(14,8),dpi=80)
plt.bar(v,w,width=move,color='#9de0ff')
plt.bar([i+move for i in v],x,width=move,color='#ffa897')
a = np.arange(0,15)+1.3
plt.xticks(a,c)
plt.yticks(list(range(0,40,5)))
plt.legend(['均值','中位数'])
plt.title('各行业薪资均值及中位数比较图',fontsize=16)
plt.xlabel('行业',fontsize = 12)
plt.ylabel('薪资(单位K)',fontsize = 12)
for e,f in zip(v,w):
plt.text(e,f,'{}k'.format(f),ha='center',fontsize=12)
for g,h in zip([i+move for i in v],x):
plt.text(g,h,'{}k'.format(h),ha='center',fontsize=12)
plt.show()
通过上图及下图我们可以发现,互联网行业和电子商务对该岗位的需求非常大,同时薪资水平相比于其他行业也高了很多
而其他传统行业相对来说,无论是需求量还是薪资水平,都低一些
In [43]:
data = df['lables'].value_counts()
y=data.values
plt.figure(figsize=(10,10),dpi=80)
plt.pie(y,labels=data.index,autopct='%.1f %%')
plt.show()

通过以上简要分析,可以发现,如果要成功转行,应该往北上广深行这几个城市考虑,这些城市的薪资水平高
而行业方面应该着眼于互联网及电子商务等新兴行业,这些行业对该岗位的需求都比较大,而且薪资水平也普遍高
工作经验对于该岗位而言非常重要,能否成功转行的关键门槛在于是否有工作经验,与薪资水平呈正相关
而转行成功以后,只有在迈过3年这个坎,才会有比较大的突破。
本章相关数据可以自行通过数据爬取部分引导进行获取保存,若有需要job.csv数据集的伙伴,也欢迎在当下留言or私信我哈!感谢支持,互相共勉!