iceberg-Spark3.0SQL 测试案例
参考:官网,调研传送门
测试使用的Spark3.0版本
一、配置及参数
1、配置jar包:
iceberg0.11.0版本,官网下载jar包,放到spark的jars目录下。
点击下载spark2.4和spark3的驱动包。
注意:要在Spark中使用Iceberg,请首先配置catalogs(注意:Spark2.4不支持DDL操作)
2、注意:
1、iceberg命名空间:V1和V2表:
v1表:使用自己启动时的本地空间,创建的表直接写入本地所指定的位置。
注意:iceberg中,v1表是不能用的,创建的iceberg表 hive、spark都是不认同的。所以必须切换到v2表进行操作。
v2表:创建Session时,catalog指定的名称。
use zdm.test切换后的表,创建的表直接写入到Hive元数据所指定的位置,建表写入数据均正常,且Hive可以查询到数据。
注意:V2表只能看到iceberg表。hive其他表无法看到,v2表建表后,Spark下show create table 是查不到建表语句的。只能desc查看表数据,如果想看建表语句,则需要用hive看,spark建表语句和hive是不同的。



3、参数及启动
创建一个名字叫zdm的catalog链接。
1、HIVE
spark.sql.catalog.zdm=org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.zdm.type=hive #hive
spark.sql.catalog.zdm.uri=thrift://metastore-host:port
#hive.metastore.uris 可以去hive-site.xml里查看
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions #SQL扩展,开启支持merge及CALL操作
2、HDFS
spark.sql.catalog.zdm=org.apache.iceberg.spark.SparkCatalog
conf spark.sql.catalog.zdm.type=hadoop
conf spark.sql.catalog.zdm.warehouse=hdfs://HDFS81339//tmp/iceberg
3、其他
查看目录和空间名称:SHOW CURRENT NAMESPACE
切换本地/Hive库:use zdm.test
4、启动
spark3-sql --master yarn \
--conf spark.sql.catalog.zdm=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--conf spark.sql.catalog.zdm.type=hive \
--conf spark.sql.catalog.zdm.uri=thrift://metastore-host:port
二、Spark3.0-SQL测试案例
DDL操作
1、建表
create table iceberg_spark(id int ,name string,dt String) using iceberg PARTITIONED by (dt);
2、插入数据
hive> insert into table iceberg_table values(5,'e');
3、删除表
hive> insert into table iceberg_table values(5,'e');

4、重命名
ALTER TABLE zdm.test.iceberg_spark RENAME TO zdm.test.iceberg_spark1;

5、新增列(FIRST和AFTER更改顺序):
ALTER TABLE zdm.test.iceberg_spark1 ADD COLUMN sex String AFTER id;

6、删除列:
ALTER table iceberg_spark1 DROP COLUMN flag;

7、分区操作
新增/更改/删除分区字段:
添加分区字段是元数据操作,不会更改任何现有表数据。新数据将使用新分区写入,旧数据还在改之前分区中。
对于元数据表中的新分区字段,旧数据文件将具有空值。
注意:
1、启动时必须加SQL扩展参数;
2、不要删除分区操作,删除分区时显示成功,但是测试中发现,会删除元数据,导致后续命令desc和insert 失败。
ALTER TABLE zdm.test.iceberg_spark ADD PARTITION FIELD catalog;
ALTER TABLE zdm.test.iceberg_spark ADD PARTITION FIELD truncate(dt, 4);
ALTER TABLE zdm.test.iceberg_spark ADD PARTITION FIELD years(dt); --dt必须是timestamp类型
ALTER TABLE zdm.test.iceberg_spark DROP PARTITION FIELD truncate(dt, 4); --慎重

8、设置顺序写入
表写顺序不能保证查询的数据顺序。它仅影响将数据写入表的方式。比如 MERGE INTO 在Spark中将使用表排序。
ALTER TABLE zdm.test.iceberg_spark1 WRITE ORDERED BY id
DML操作
1、插入数据
insert into/overwrite table iceberg_spark values(1,"a","2021"),(2,"b","2021"),(3,"c","2021");
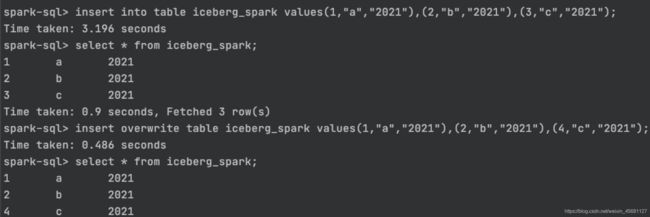
2、删除数据
delete from zdm.test.iceberg_spark where id=4;

3、merge数据
merge测试有异常,因为SQL扩展未能成功,Yarn UI上查看的确已经加载了扩展的jar包,也有了加载参数,但是却始终报未加载成功异常,社区提issus之后也未能解决。暂时使用官网案例。
MERGE INTO prod.db.target t -- a target table
USING (SELECT ...) s -- the source updates
ON t.id = s.id -- condition to find updates for target rows
WHEN ... -- updates
----------------------------------------------------------------------
WHEN后面跟条件
WHEN MATCHED AND s.op = 'delete' THEN DELETE
WHEN MATCHED AND t.count IS NULL AND s.op = 'increment' THEN UPDATE SET t.count = 0
WHEN MATCHED AND s.op = 'increment' THEN UPDATE SET t.count = t.count + 1
----------------------------------------------------------------------
不匹配则插入:
WHEN NOT MATCHED THEN INSERT *
----------------------------------------------------------------------
插入还支持其他条件:
WHEN NOT MATCHED AND s.event_time > still_valid_threshold THEN INSERT (id, count) VALUES (s.id, 1)
其他运维操作
1、查看版本信息(必须写全表namespace.database.table.history):
select * from zdm.test.iceberg_spark.history;

2、展示元数据信息
select * from zdm.test.iceberg_spark.manifests;
![]()
3、显示一个表的数据文件和每个文件的元数据
select * from zdm.test.iceberg_spark.files

4、查看快照信息
SELECT * FROM zdm.test.iceberg_spark.snapshots

5、使用CALL对表进行运维操作
以下是扩展运维,SQL操作iceberg表。(类似于存储过程)
可以从任何已配置的Iceberg目录中使用程序CALL。所有过程都在名称空间中system。
CALL支持按名称(推荐)或按位置传递参数。不支持混合位置和命名参数。
1、回滚数据到某个版本:
CALL catalog_name.system.rollback_to_snapshot(‘zdm.test.iceberg_spark’, 1)
回滚数据到一天前:
CALL catalog_name.system.rollback_to_timestamp(‘db.sample’, date_sub(current_date(), 1))
2、设置表当前快照ID(此过程会使所有引用受影响的表的缓存Spark计划无效):
CALL catalog_name.system.set_current_snapshot(‘test.iceberg_spark’, 1)
3、创建新快照,只能选择追加和动态覆盖快照(此过程会使所有引用受影响的表的缓存Spark计划无效):
CALL catalog_name.system.cherrypick_snapshot(snapshot_id => 1, table => ‘my_table’ )
4、从快照表版本中恢复数据:
CALL catalog_name.system.cherrypick_snapshot(‘my_table’, 1)
5、删除快照:
每次对数据进行变化都会创建一个新快照,每个快照生成一个文件,为了删除用不掉的旧文件,减少压力,可以定期进行删除快照。
删除10天前的快照,但保留最近100个快照:
CALL hive_prod.system.expire_snapshots(‘db.sample’, date_sub(current_date(), 10), 100)
删除所有早于当前时间戳的快照,但保留最后5个快照:
CALL hive_prod.system.expire_snapshots(table => ‘db.sample’, older_than => now(), retain_last => 5)
6、删除Iceberg表的任何元数据文件中未引用的文件
列出所有可能需要删除的文件,只列出不删除:
CALL catalog_name.system.remove_orphan_files(table => ‘db.sample’, dry_run => true)
删除任何在 tablelocation/data下,与表db.sample 不关联的文件,
CALL catalog_name.system.remove_orphan_files(table => ‘db.sample’, location => ‘tablelocation/data’)
7、重写用于加速查询的manifests文件,manifests文件是与分区对应的,重写会执行Spark程序。(此过程会使所有引用受影响的表的缓存Spark计划无效):
重写,默认开启Spark缓存,可以加参数false禁止Spark缓存:
CALL catalog_name.system.rewrite_manifests(‘db.sample’)
CALL catalog_name.system.rewrite_manifests(‘db.sample’, false)
8、使用快照创建临时表:
使用快照表创建临时表,不会在数据目录data下生成新数据,数据存储在快照目录下,测试完临时表直接dtop table即可,不影响快照表:
CALL catalog_name.system.snapshot(‘db.sample’, ‘db.snap’)
创建的临时表数据也可以放到指定位置:
CALL catalog_name.system.snapshot(‘db.sample’, ‘db.snap’, ‘/tmp/temptable/’)
使用完直接drop即可。
drop table db.snap;
9:将其他表迁移成iceberg表。
迁移后,表的结构,分区,属性不变。如果不是avro,parquet、orc文件格式的表,会迁移失败。
CALL catalog_name.system.migrate(‘db.sample’)
3、删除及更新(不可用)
hive> delete from iceberg_table where id=5;
尝试使用不支持这些操作的事务管理器进行更新或删除操作
![]()
F&Q
1、Spark是否可以查看hive创建的ice表?
无法看到

2、Spark创建的表,hive是否可以删除?
可以删除操作,删除后hive和spark执行show tables,无法看到表信息;
但是只删除元数据,HDFS上依然可以看到删除的文件目录及数据文件。
但不影响重新创建该表,重新再创建,MSCK修复,也无法读取到数据,
总结
没啥总结的,测试时问题超多,尤其是catalog,还需要切换这一点,很费劲。