Deep Virtual-to-Real Distillation for Pedestrian Crossing Prediction(行人横穿马路预测,论文翻译)
(机翻)
原文地址:https://arxiv.org/abs/2211.00856#:~:text=To%20this%20end%2C%20we%20formulate%20a%20deep%20virtual,real%20data%20with%20a%20simple%20and%20lightweight%20implementation.
Abstract
行人过街是最典型的与车辆自然行驶行为相冲突的行为之一。 因此,行人过路预测是影响车辆安全驾驶规划的主要任务之一。 然而,目前依赖于实际驾驶场景中实际收集的数据的方法无法描绘和覆盖真实交通世界中的各种场景条件。 为此,我们通过引入可以方便地生成的合成数据,制定了一个深度虚拟到真实的蒸馏框架,并借用合成视频中丰富的行人运动信息,以简单轻量的方式对真实数据中的行人过马路进行预测。 执行。 为了验证这个框架,我们用拥有大约 745k 帧的 4667 个虚拟视频构建了一个基准(称为 Virtual-PedCross-4667),并在真实驾驶情况下收集的两个具有挑战性的数据集上评估所提出的方法,即。 e., JAAD 和 PIE 数据集。 详尽的实验分析证明了该框架的最新性能。 数据集和代码可以从网站上下载。
Introudction
弱势道路使用者(行人、骑自行车的人和摩托车)是占据车辆先行权的主要角色,占世界卫生组织(WHO)调查的所有道路交通死亡人数的一半以上。 它们的运动不可避免地与车辆的自然行驶行为发生冲突,其中交叉行为最为典型。 面对自动驾驶或辅助驾驶系统的发展趋势,预测弱势道路使用者的穿越行为对于安全驾驶至关重要。
在这项工作中,我们关注以历史视频观察作为输入的行人过马路预测问题,并预测未来时间行人是否过马路,如图 1 所示。 在这个领域,2D 姿势、行人边界框、光流、场景上下文、车辆速度、轨迹、车辆的自我运动在以前的工作中被使用。 同时,近年来采用了深度学习模型,例如 I3D、基于 LSTM/RNN 的时间模型以及 transformer。 然而,由于行人的高机动性,先前工作的预测结果并不相互认可,特别是对于行人显示小尺度的开始时间。 此外,大尺度的变化、多变的光照条件、多变的天气条件、车辆复杂的相机运动等,都对本课题构成了挑战。
在实际驾驶场景中,行人过马路行为往往出现在道路交叉口和主干道上。 同时,为了安全驾驶,车速越高,越早预测人行横道,即使是小尺度。 此外,天气条件是该领域的另一个关键问题,雨天、雾天、雪天等恶劣天气条件导致前方行人的示范不清晰。 但是,这些情况在驾驶体验中很少出现。 因此,很难收集涵盖不同光照和天气条件的大规模数据集,并且可能需要进行大量费力的注释工作。 因此,上述问题造成了一个小样本问题,制约了行人过街预测的性能,并导致一个主要问题:如何收集足够多的人行横道数据,涵盖各种光照、天气、场合条件?
然而,在实际驾驶中很难解决这个问题。 最近的一项工作探索了 CARLA 模拟的虚拟数据,它收集了大规模的动作预测数据集并定义了交叉情况。 然后,该工作采用微调模块将合成数据的分布转移到真实数据的分布。 但是,为了使分布可迁移,该工作仅考虑行人的边界框。 尽管如此,边界框没有场景信息,任何过马路行为(不限于行人过马路)都可以被视为行人过马路(误报),如图1所示。 同时,大量先前的方法验证了其他外观信息、运动信息、场景信息等是有用的。 然而,更多的输入信息将花费更多的计算成本来表示这些信息的知识,而我们在实际使用中需要一个轻量级的实现。 因此,与微调模式不同,我们探索了行人过街检测的知识蒸馏(KD)。
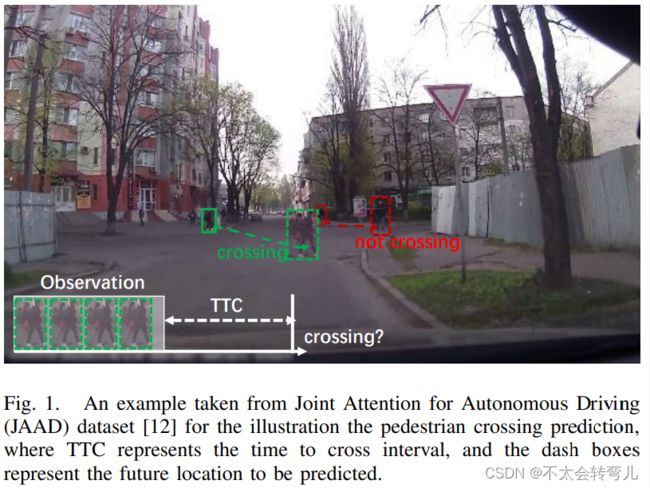
为了利用各种场景条件下合成数据中的交叉行为知识,我们为行人交叉预测(称为 VR-PCP)制定了一个深度虚拟到真实的蒸馏框架。 蒸馏框架包含一个用合成视频训练的教师 PCP 网络,以及一个轻量级的学生 PCP 模型,用于在一些实际平台中进一步实施。 同时,蒸馏框架可以在教师PCP的帮助下吸收行人过街行为的丰富信息,包括运动、位置、场景上下文,并将它们传递给学生PCP。 为了训练老师 PCP,构建了一个新的行人过路处预测基准,其中包含 4667 个合成视频,拥有 745k 帧(称为 Virtual-PedCross4667,在实验中描述)。 基于对两个具有挑战性的数据集的详尽实验,i。 例如,自动驾驶联合注意(JAAD)和行人意图估计(PIE),所提出的方法优于其他最先进的方法。
Related work
A. 视频中的动作预期
视频中的动作预期追求对即将到来的视频流中的对象展示的准确动作预测。 与行人过街行为不同,该行为可能发生在任何场合,但现有的行为预测工作涉及行人参与者。
以前的大部分工作都利用了部分观察到的动作与整个视频中的动作之间的时空一致性。 因此,一些工作探索了部分观察到的视频的局部时空特征与整个视频的全局特征对齐的顺序关系。 为了准确预测动作,部分观察到的视频的局部特征的对齐顺序很重要。 因此,许多作品都专注于全局特征学习。 为了获得准确的动作预期,除了时空一致性考虑外,动作语义一致性也很重要。 对于这些信息,许多工作从对象交互、场景的结构或层次图关系、场景上下文信息等中提取语义特征。
至于我们的工作,最相关的工作是自我中心视频(也称为第一人称视频)中的动作预期。 在这个域中,观察者的意图、观察者与场景中的物体的交互都集中了。 刘等人。 探索有意的手部动作,共同了解以自我为中心的手部动作、交互热点和未来行动的深层关系。 张等。 提出了一个反事实分析框架来推断动作的语义和视觉因果特征。
B. 行人过路预测
在行人过马路预测中,许多工作将行人过路预测问题表述为行人轨迹预测任务。 例如,薛等人。 提出了一种编码器-解码器 LSTM 网络来预测过马路行人的轨迹。 吴等。 提出了一种在预测中涉及行人意图和行为信息的行人轨迹预测方法。 此外,要过马路的行人通常会表现出与即将到来的车辆的互动,即。 e., 有意图的沟通。 通常,身体姿势和注视方向是交流中的两个主要信号。 因此,一些工作研究了行人姿势、联合注意等,以对交叉路口特征进行编码。 著名的工作是自动驾驶的联合注意(JAAD)。
行人过路处具有发生的特殊上下文信息,i。 e.,以道路边界为标志。 因此,上下文信息在行人过路处预测任务中被广泛利用。 例如,Rasouli 等人。 考虑到行人的场景动态和视觉特征,并提出了一种堆叠的 RNN 来推断时间预测。 在同一个研究小组中,他们构建了著名的行人意图估计(PIE)数据集。
由于无标记道路上人行横道的罕见性,Achaji 等人。 提出了一项在大规模模拟数据上训练的新工作,它强调仅使用行人的边界框可以利用准确的行人过路预测。 然而,这项工作没有考虑遇到恶劣天气条件、弱光条件时行人过街问题的少镜头问题。 此外,行人过街处在道路区域的特殊背景下,仅靠边界框信息无法反映道路背景,任何类似于过马路行为的运动都可以被接受。
C. 行为预测的知识蒸馏
关于这项工作,知识蒸馏(KD)最近被用于一般视频中的动作预测任务,它将其他完整视频中的完整信息转移到部分观察到的视频中,用于未来的动作预测。 例如,Camporese 等人。 使用知识蒸馏来平滑完整视频和部分视频之间的标签,教师模型提取动作预期的语义先验信息。 王等。 提出了一个教师模型来识别完整视频中的动作,以及一个学生模型来预测部分视频中的早期动作。 类似地,在完整视频上训练的特征嵌入和动作分类器在教师模型中被提炼出来用于预测。 最近,协作知识蒸馏旨在解决多视角相机中观察到的动作预测问题。
如今,KD 在行人过路处预测中是缺席的。 至于复杂环境条件下的少样本问题或样本短缺问题,KD 可能会有用,将在我们的工作中进行研究。
METHOD
A. 问题表述
在合成数据的帮助下,我们制定了一个虚拟到真实的蒸馏框架,以提高对真实数据(简称 VRPCP)的行人过街预测的性能。 因此,这项工作建立了一个模型,其中教师模型 T 在合成数据上训练,学生模型 S 适应真实数据。 在这个框架下,两个问题是如何将T在合成数据上学到的丰富特征借用给S,并使S易于实现和轻量级。
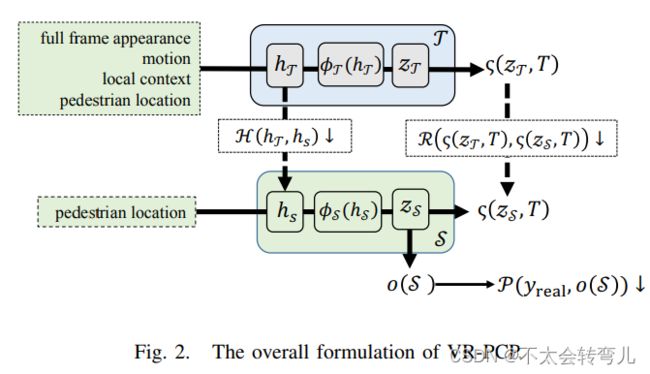
因此,我们将这项工作中的问题定义为最小化以下目标函数。
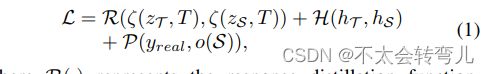
其中 R(. ) 表示响应蒸馏函数,它将教师模型输出的 logits zT 转移到学生模型的 ones zS。 这里的对数表示交叉或不交叉的二维指标。 H(.)表示特征蒸馏函数,它将T在合成数据上学习到的丰富特征信息hT吸收到真实数据训练S中的特征hS。 P指定使用S来近似真实数据中交叉或不交叉的groundtruth(yreal)的预测模型。 ζ(. )和o(S)分别是logits蒸馏的概率函数和S的交叉预测函数。 ζ(. )通常定义为一个softmax函数,超参数T控制logits各值的重要性,T越大则重要性越高。 为了清楚地演示该公式,我们在图 2 中展示了 VR-PCP 的概览。
logits zT是归一化前的目标向量(交叉或非交叉),由教师模型的提示层中的特征变换得到,记为φT(hT)。 同样,zS=φS(hS)。 另外,预测模型o(S)表示为ζ(zS,T=1),表示一个通用的softmax函数。 因此,行人过路处预测问题可以表述为对教师 PCP 模型 T、学生 PCP 模型 S、R(.) 和 H(.) 的蒸馏函数以及预测模型 P(.) 进行建模。
B. Modeling T
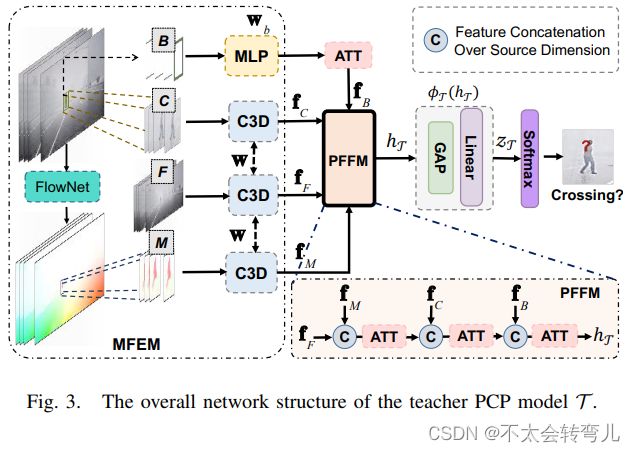
众所周知,在知识蒸馏框架中,学生模型的表现依赖于教师模型的学习能力。 通常,教师模型拥有复杂的架构来学习数据集中的丰富知识。 为了更好地对教师 PCP 模型 T 进行建模,我们使用跨模态特征融合模块对其进行建模。 具体来说,边界框、局部上下文、行人运动和全帧被认为可以实现丰富的特征学习。 值得注意的是,我们将全帧添加到特征学习中以考虑道路结构。 T的示意流程图如图3所示。 我们可以看到教师PCP模型有两部分模块:多模态特征嵌入模块(MFEM)和渐进特征融合模块(PFFM)。
- MFEM:假设我们输入 N 帧 F={ft}N t=1,并预测第 f 帧的交叉或未交叉标签,其中交叉时间(TTC)间隔为 fm−fN 帧。 对于运动信息,我们选择了光流图像。 假设局部上下文区域、边界框和一个行人的局部运动区域表示为 C={ct}N t=1, B={bt}N t=1, M={mt}N−1t= 1,分别。 ct 是 ft 的子区域,它包围 bt 的大小是 bt 的 1.5 倍。 同样,mt 的尺度与ct 的尺度相同。 运动区域mt实际上是Flownet2.0在帧ft和ft−1上得到的光流图像的子区域。 在这项工作中,我们采用 3 层 MLP 来获得每个 bt 的嵌入和 3D 卷积网络(C3D)对于 F、C 和 M 的特征,如:
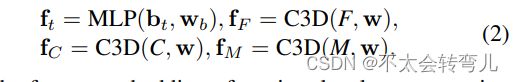
其中运动特征嵌入、局部上下文区域和全帧共享相同的权重w,wb是三层MLP的权重。 fF、fC和fM具有相同的128维形状,分别是行人位置、帧外观、局部上下文和局部运动区域的特征向量。
2)PFFM:虽然我们在合成数据中有多种信息,但它们对于行人过路预测的重要性可能不同。 因此,这项工作设计了一个渐进式特征融合模块(PFFM),用于从全局到局部的角度选择有用的多模态特征,并且每个融合步骤都由一个 selfATTention 模块(ATT)完成。 PFFM更强调局部特征,因为与行人的关系更密切,背景干扰更弱。
对于时间 t 的行人位置特征向量 ft,这项工作提取了 N 帧位置的时间注意特征 fB,并探索了时间步长的时间重要性。 因此,我们也取可学习的self-ATTention module(ATT),定义为:
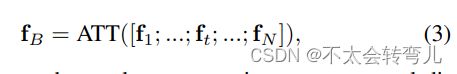
这里[; ]表示时间维度上的堆栈连接。 然后,我们采用渐进融合策略融合位置特征、帧特征、局部上下文特征和运动特征,并指定为:
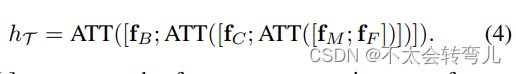
这里, [; ]表示特征模态维度上的特征连接。 级联特征表示定义为ffuse∈R128×K,其中K表示特征模态的数量,并设置为2用于渐进融合策略。 ATT(ffuse) 定义为:
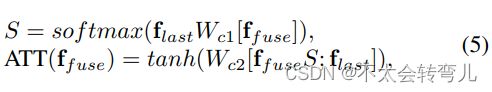
其中flast表示ffuse的最后一列值,Wc1和Wc2是全连接层的权重。
对于hT,它由全局平均池化(GAP)层建模的二元分类器φ(hT)判断,2个全连接层,并生成由softmax层分类的teacher logits zT,用于交叉或不交叉确定。
C. modeling S
利用 T 学习的丰富信息,我们旨在设计一个轻量级的学生 PCD 网络 S 以供实际实施。 为了获得轻量级学生 PCD,主要有两个考虑因素:1)简化输入信息,以及 2)减少 S 的参数。在这项工作中,我们同时考虑了这两个见解。
为了简化输入信息,我们只在N帧中选择行人位置B={bt}N t=1,其中bt是(x, y, height, width)的4维信息,(x, y)表示 中心坐标。 N 帧上的行人位置信息被馈送到由一些轻量级网络实现的学生 PCP 模型 S。
虽然S更注重利用行人的位置信息,但经过T的蒸馏后,可以吸收运动、场景上下文等信息,其中包括不同光照和天气条件的影响。 因此,在实际使用中,蒸馏后的 S 对于行人过马路任务是有效且有意义的。
为了减少 S 的参数,我们采用了四种轻量级架构。 它们是权重大小分别为 4.77M、10.79M、3.32M 和 2.12M 的 naive Transformer、ResNet18、MobileNet 和 ShuffleNet。 为了使行人位置信息直接用于这些轻量级网络,我们引入了一个嵌入层,用于将 B∈RN×4 转换为 B^∈RN×4×64,嵌入 64 维。 嵌入层通过以下方式实现:
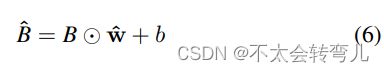
其中 w∈R4×64为embedding层的权重,b为偏置值,表示点积运算。 B可以直接馈入轻量级网络。 然后通过Net(B^)得到学生PCP模型的特征表示hS,其中Net()表示轻量级网络。
使用hS,二元分类器φ(hS)与φ(hT)相同,由全局平均池化(GAP)层建模,2个全连接层,并生成学生logits zS,由softmax层分类,用于交叉或不交叉确定 .
D. 虚拟到真实的蒸馏
通过对教师 PCP 模型 T 和学生 PCP 模型 S 的建模,本小节描述了虚拟到真实的蒸馏。 假设教师PCP模型是用合成数据离线训练的,蒸馏过程是通过将真实数据输入到训练好的T和S中同时进行训练来实现的。 值得注意的是,为了吸收 T 的表示能力,我们需要获得与合成数据相同的信息配置。 因此,在蒸馏之前,我们首先在真实视频数据上生成光流图像。 然后,将真实数据的完整视频帧、光流图像、真实数据的行人的位置和局部视觉上下文输入 T 以生成教师模型的 logits zT。 只有行人的位置被输入到 S 并生成 logits zS。
如公式 1 中所述,R(ζ(zT, T), ζ(zS, T)) 和 H(hT, hS) 桥接了 T 和 S 之间的蒸馏过程。在这项工作中,我们采用 Kullback-Leibler 散度 (KLD)和均方对数损失来定义响应蒸馏函数R(.)和特征蒸馏函数H(.),定义为:
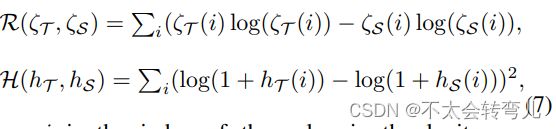
其中 i 是 logits zS 或 zT 中值的索引。 ζT=ζ(zT, T)), ζS=ζ(zS, T)), ζ(., T)) 表示超参数温度 T 的 softmax 函数,在本文中设置为 2。
通过对 VR-PCP 中的模块进行这些建模,可以通过最小化等式 1 中定义的函数来进行蒸馏过程。 在下文中,我们将通过详尽的实验评估所提出的方法。
Experiments

图四:Virtual-Pedcross-4667 数据集中的一些人行横道示例。 过马路的行人用红色边界框标记。 同一列展示了同一场景下不同光照和天气条件下的样本,其中(a)、(b)、(c)和(d)分别代表晴天、傍晚、夜间和雨天。
A. Dataset: Virtual-PedCross-4667
在这项工作中,我们使用 CARLA 模拟器生成大量具有行人过街行为的虚拟驾驶视频。 特别地,在数据生成中考虑了场景地图、天气和光照条件、行人年龄和性别。 继JAAD和PIE数据集之后,收集了前向行车记录仪视频,并收集了4667个视频序列(称为Virtual-PedCross-4667),由2862个行人过街序列和1804个非过街序列组成。 总共保存了745k分辨率为1280×720的视频帧。 Virtual-Pedcross-4667 数据集中一些典型的人行横道示例如图 4 所示。 在行人过马路序列中,每个序列中都有一个行人表现出过马路行为,而对于行人不过马路序列,每个序列中会随机出现1到3个不过马路的行人。 此设置有助于将整个视频序列视为正样本或负样本。 每个行人过马路序列包含200个视频帧,而非过马路序列包含100个视频帧。 每一帧都会自动标记五个属性:场合、天气、性别、年龄和行人的边界框坐标。
表一:VIRTUAL-PEDCROSS-4667 与其他现有行人过路处数据集的比较。 S. /R.:合成或真实数据。
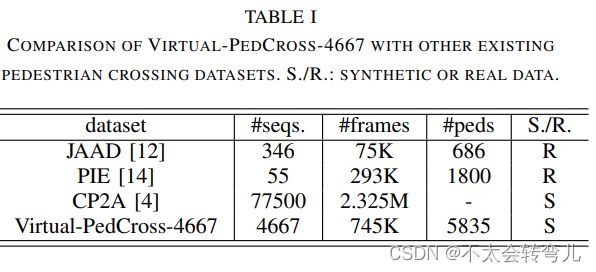
我们在序列号、帧数和行人计数方面将我们的数据集统计数据与 JAAD、PIE 和 CP2A(最近报告)进行了比较,如表 I 所示。此外,由于行人规模对预测精度有很大影响, 我们在图 5 中比较了我们的数据集 JAAD 和 PIE 的行人尺度统计数据。 从这个图中,我们可以看到我们的数据集覆盖了更多的小规模行人样本,这对于早期的交叉行为预测很有用。
B. 实施细节
我们使用 Virtual-PedCross-4667 训练模型 T,并使用 PIE 和 JAAD 数据集训练模型 S。 所有视频帧都缩放为224×224,因此输入维度设置为[batchsize, N, 224, 224, 3]。 行人边界框的非视觉信息维度为[batch size, N, 4]。 本工作中的批量大小设置为 2。 观察帧数N设置为16,0.5秒(30fps)。 穿越时间 (TTC) 设置为 1-2 秒(30-60 帧)。 测试时,虽然T需要丰富的人行横道信息,但我们只评估S的性能,不会影响S的执行效率。
对于训练 T,我们训练模型 T,训练周期为 20,学习率为 5×10−5。 在训练期间添加了 0.5 的 dropout。 在获得训练模型 T 后,我们进行蒸馏过程并使用 Adam 优化器训练模型 S,学习率分别为 5×10-5 和 PIE 和 JAAD 数据集的 epoch 为 60 和 120。 训练和测试设置与其他更新作品相同,,。
指标:根据更新后的工作,我们采用准确性(Acc)、F1score(F1)、精度(Pre)和召回率(Rec)以及曲线下面积(Auc)指标来评估性能。 这些指标更喜欢更大的值。
C. 消融研究
在这项工作中,我们将四种信息输入到教师 PCP 模型中。 哪种组合最适合行人过路预测和蒸馏过程? 我们详尽地评估了蒸馏过程中不同信息组合的性能差异。 在比较中,我们还切换了轻量级学生 PCP 模型,i。 例如,Transformer(Trans.)、ResNet18(R.Net)、MobileNet(M.Net) 和 ShuffleNet(S.Net)。 性能比较结果如表所示。 二。 从结果中我们可以看出,性能随着信息的增加而增加,与其他学生 PCP 模型相比,轻量级模型 Transformer 产生的性能最好。 值得注意的是,我们还展示了没有蒸馏过程的学生 PCP 模型的结果(BB w/o distill.)。
表二:学生 PCP、W. R. T.、不同输入信息(INFO.)和不同轻量级学生网络(NET.)的性能比较。 局部上下文区域、边界框、局部运动区域和全局上下文区域分别缩写为LC、BB、LM、GC。
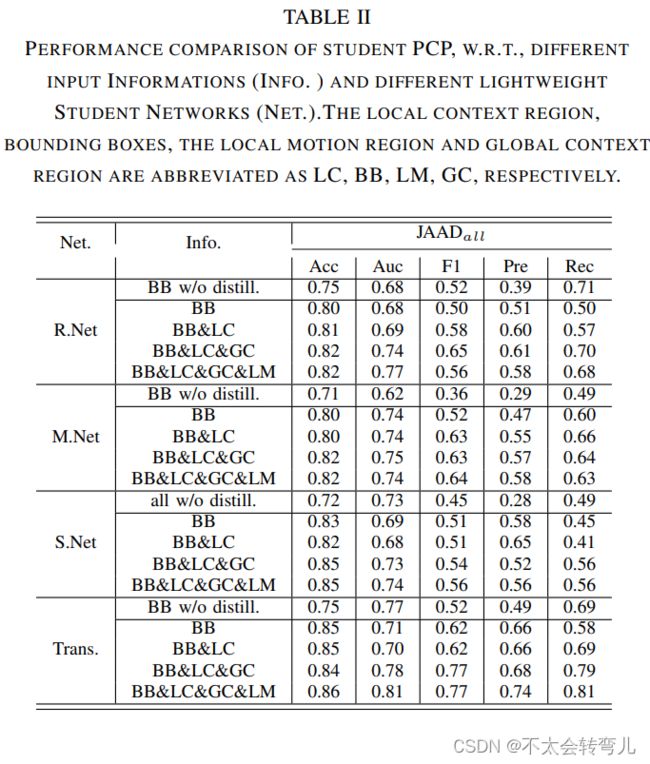
由于 JAAD 数据集中负样本数量多于正样本数量,几乎所有方法的召回值都大于精度值。 实际上,样品不平衡问题在蒸馏过程中很重要。 从“BB w/o distill”的结果可以看出,与没有蒸馏过程相比,recall 和 precision 值之间的差距比蒸馏后的要大。 因此,借助教师PCP模型,我们可以更好地限制样本不平衡问题。
D. 与最先进技术的比较
在这项工作中,我们将所提出的方法与 JAAD 数据集和 PIE 数据集上的九种最先进的方法进行了比较。 这些方法列在表 III 中,其中 ATGC 由传统的 AlexNet 建模。 SPI-Net、SingleRNN、MultiRNN 和 SFRNN 采用相同的门控循环单元 (GRU) 对行人运动观察的时间特征进行建模。 实际上,这项工作中的大多数竞争对手都考虑了序列观察的特征编码的多个信息,而我们的虚拟到真实蒸馏的工作(学生 PCP 模型)只考虑了边界框。 同时,大多数作品都采用相同的设置,观察时间为0.5秒,穿越时间(TTC)为1-2秒。 结果见表三是从他们的作品中报道。
表三:JAADall、JAADbehavior 和 PIE 数据集上基线和最新技术的性能比较。
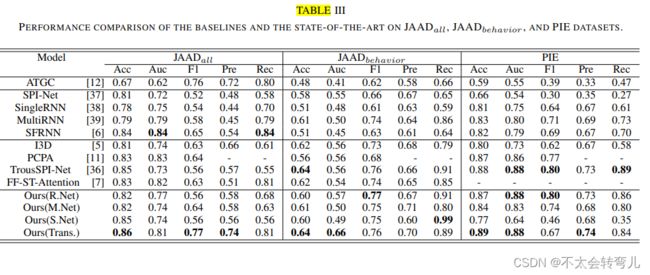
从表III,我们可以看到我们的方法,尤其是“Ours(Trans.)”和“Ours(R.Net)”在 PIE 数据集上产生了比较性能,“Ours(Trans.)”最适合 JAAD 数据集。 TrousSPI-Net 在 PIE 数据集上展示了良好的性能,它将边界框、车速、行人姿势融合在一起,并且拥有比我们的工作更多的参数。 因此,我们可以得出结论,从虚拟数据集到真实数据集的蒸馏过程对行人过街预测很有用。
在图 6 中,我们还展示了一些帧截图,比较了权重大小为 29.72M 的 PCPA 和我们的方法(Ours(Trans.))的权重大小为 4.77M。 从演示的帧来看,过马路的行人在开始时显示出较小的尺度,而未过马路的行人在观察中具有与过马路相同的移动方向,这加强了预测,我们的方法以相当低的计算成本显示出有希望的结果。

表6:通过 PCPA 和我们的方法在(a)JAAD 数据集和(b)PIE 数据集中交叉(C)或不交叉(NC)的预测结果的一些帧截图。 GT代表真实情况。 行人用红色框标记
conclusion
在本文中,我们提出了一种深度虚拟到真实的蒸馏框架,用于驾驶场景中的行人过马路预测。 构建了一个名为 Virtual-Pedcross4667with745k 帧的大规模虚拟数据集,并仔细考虑了光照和天气条件。 通过蒸馏过程,我们可以简化学生行人过路预测模型的架构并产生有希望的预测性能。 基于与许多最先进的方法的比较,所提出方法的优越性通过详尽的实验得到验证。 未来,我们将探索更先进的知识蒸馏框架和更好的师生模型。 此外,我们将收集更多真实道路上的交叉场景,以增强结果的可靠性。