【论文阅读】Frustratingly Simple Few-Shot Object Detection
从几个例子中检测稀有物体是一个新出现的问题。 先前的工作表明Meta-Learning是一种有希望的方法。 但是,微调技术很少引起注意。 我们发现,在稀有类上只对现有探测器的最后一层进行微调对于 Few-Shot Object Detection至关重要。 这样一种简单的方法在当前基准上比元学习方法高出大约2~20个百分点,有时甚至比以前的方法提高了一倍的准确率。 然而,少数样本中的高方差(high variance)往往导致现有基准的不可靠性。 我们通过对多组训练样本的抽样来修正评估协议,以获得稳定的比较,并基于三个数据集:Pascal VOC、COCO和LVIS建立新的基准。 同样,我们的微调方法在修订后的基准上效果也更好。
引入
The ability to generalize from only a few examples (so called few-shot learning) has become a key area of interest in the machine learning community.
But, current evaluation protocols suffer from statistical unreliability, and the accuracy of base-line methods, especially simple fine-tuning, on few-object detection are not consistent in the literature.
在基于微调的模型设计和训练中,我们重点研究了目标检测器的训练调度和实例级特征归一化。
现有评估协议的几个问题阻碍了相关模型的比较:精度测量有很高的方差,使结果不可靠。 另外,以往的评价只报告了新类的检测精度,而没有对基类进行评价。 为了解决这些问题,我们在三个数据集上构建新的基准:Pascal VOC、COCO和LVIS(Gupta et al.,2019)。 我们对不同组的few-shot training examples进行多次实验,以获得稳定的精度估计,并定量分析不同评估指标的方差。 新的评估报告了基类和新类的平均精度(AP),以及所有类的平均精度,referred to as the generalized few-shot learning setting in the few-shot classification literature.
我们的微调方法在基准上建立了新的技术状态。 在具有挑战性的LVIS数据集上,我们的两阶段训练方案将稀有类(<10幅图像)的平均检测精度提高了大约4点,将常见类(10~100幅图像)的平均检测精度提高了大约2点,而对频繁类(>100幅图像)的检测精度损失可以忽略不计。
Related Work
Meta-learning
元学习的目标是获取任务级的元知识(task-level meta knowledge),帮助模型快速适应新的任务和环境with very few labeled examples.
Some learn to 微调并旨在获得一个良好的参数初始化,该参数初始化可以适应新任务with a few scholastic gradient updates。 关于元学习的另一个流行研究路线是在适应新任务时使用参数生成。 Gidaris&Komodakis(2018)提出了一种基于注意力的权重生成器来生成新类的分类器权重。 王等人(2019a)通过为特征层生成参数来构造task-aware feature embeddings。 这些方法已被用于用于few-shot 图像分类,not目标检测等更具挑战性的任务。
Metric-learning
Intuitively, if the model can construct distance metrics to estimate the similarity between two input images, it may generalize to novel categories with few labeled instances.
最近,一些(Chen et al.,2019;Gidaris&Komodakis,2018;Qi et al.,2018)采用了基于余弦相似度的分类器来减少few-shot 分类任务的内部方差,与许多基于Meta-Learning的方法相比,这导致了更好的性能。 我们的方法还采用了一个余弦相似分类器来对region proposals的类别进行分类。 然而,我们将重点放在实例级的距离测量上,而不是图像级的距离测量。
Few-shot object detection
元学习: 文献1(2019)和 Meta rcnn (2019)在元学习器的帮助下,将 feature reweighting 方案应用于单级对象检测器(YOLO V2)和两级对象检测器(Faster R-CNN),该元学习器将支持图像(即少量新/基类的标记图像)以及bounding box annotations作为输入。 王等人(2019b)提出了一个权重预测元模型,从少量样本中学习category-specific的例子,同时从基类样本中学习类别不可知(category-agnostic)的例子。
在所有这些工作中,基于微调的方法被认为是比基于元学习的方法性能更差的基线。 他们考虑联合优化 (jointly finetuning:指基类和新类一起训练),并微调整个模型(检测器首先只在基类上训练,然后在一个既有基类又有新类的平衡集上微调)。 相比之下,我们发现只对平衡子集上的目标检测器的最后一层进行微调,并保持模型的其余部分不变,可以显著提高检测精度,优于现有的所有基于元学习的方法。 这表明,从基类学习的特征表示可能能够转移到新的类,对box predictor的简单调整可以提供强大的性能增益。
Algorithms for Few-Shot Object Detection
用于训练的新集合是平衡的,即每个类具有相同数量的annotated objects(即,k-shot)
The few-shot object detector is evaluated on a test set of both the base classes and the novel classes, which is different from the N-way-K-shot setting commonly used in few-shot classification
Two-stage fine-tuning approach
two-stage fine-tuning approach (TFA):
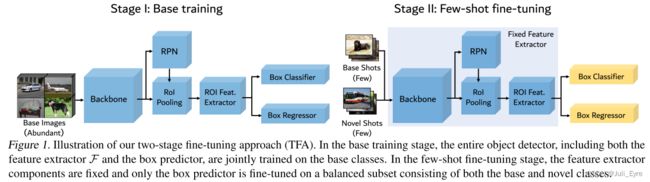
The feature learning components, referred to as F F F, of a Faster R-CNN model include the backbone (e.g.,ResNet, VGG16), the region proposal network (RPN), as well as a two-layer fully-connected (FC) sub-network as a proposal-levelfeature extractor.
直观地说,主干特性和RPN特性都是类无关的(class-agnostic)。 因此,从基类学习的特性很可能转移到新的类,而不需要进一步的参数更新。 该方法的关键部分是将the feature representation learning
and the box predictor learning分为两个阶段。
Base model training 在第一阶段,我们只在基类 C b C_b Cb上训练特征提取器和盒预测器,共同损失是,

Few-shot fine-tuning 在第二阶段,我们创建一个小的平衡训练集,每个类有k shots,包含基础类和新类。 在保持整个特征提取器固定不变的情况下,我们对新类的box prediction网络随机初始化权值,只对分类和回归网络(即检测模型的最后一层)进行微调。 我们在方程1中使用相同的损失函数和较小的学习速率。 在我们所有的实验中,学习率比第一阶段降低了20。
Cosine similarity for box classifier the weight matrix W W W
The output of the box classifier C C C is scaled similarity scores S S S of the input feature F ( x ) F(x) F(x) and the
weight vectors of different classes.
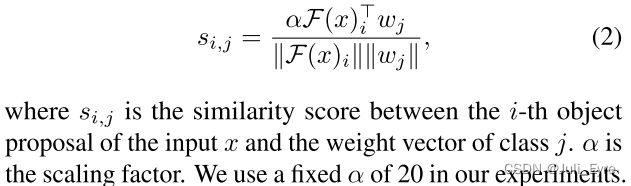
实验结果表明,与基于FC的分类器相比,基于余弦相似度的分类器采用实例级特征归一化的方法可以减少类内方差,提高新类的检测精度,而基类的检测精度下降较小,特别是在训练样本数较少的情况下。
Meta-learning based approaches
在本节中,我们描述了现有的基于元学习的少镜头目标检测网络,包括FSRW(Kang et al.,2019)、Meta R-CNN(Yan et al.,2019)和MetaDet(Wang et al.,2019b),以与我们的方法进行比较。 图2说明了这些网络的结构。
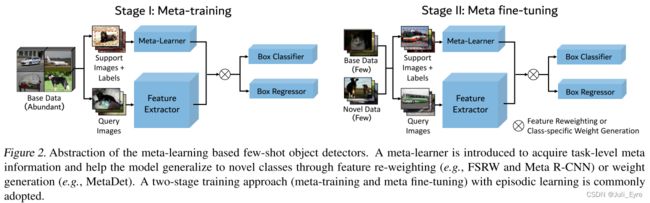
在元学习方法中,除了采用单阶段或两阶段的基本对象检测模型外,还引入了元学习器meta-learner,通过feature re-weighting(如FSRW和Meta R-CNN)或class-specific 权重生成(如MetaDet)来获取class-leval meta knowledge,并帮助模型推广到新的类。 元学习器的输入是一小组带有目标对象边界框注释的支持图像。
The base object detector和meta-learner通常使用情景训练(episodic training)共同训练。 Each episode由N个对象的支持集和一组查询图像组成。 在FSRW和Meta R-CNN中,支持图像和标注对象的二进制掩码被用作元学习器的输入,元学习器生成类重加权向量来调制查询图像的特征表示。 如图2所示
训练过程还分为元训练阶段和元微调阶段,元训练阶段只在基类的数据上训练模型,元微调阶段中支持集包括新类的少数示例和基类的子集。
元学习方法和我们的方法都有两个阶段的训练方案。 然而,我们发现,在元学习方法中使用的情节学习(episodic learning)可能会随着支持集中类的数量的增加而非常缺乏记忆效率。 我们的微调方法只对网络的最后几层进行微调,这是一个正常的批训练方案,which is much more memory efficient.
实验
Implementation details. We use Faster R-CNN as our base detector and Resnet-101 with a Feature Pyramid Network as the backbone.
Existing few-shot object detection benchmark
我们将我们的方法与Meta-Learning方法如FSRW、Meta-RCNN和MetaDet以及基于微调的方法进行了比较。 jointly training, denoted by F R C N / Y O L O + j o i n t FRCN/YOLO+joint FRCN/YOLO+joint, where the base and novel class examples are jointly trained in one stage, and fine-tuning the entire model, denoted by F R C N / Y O L O + f t − f u l l FRCN/YOLO+ft-full FRCN/YOLO+ft−full, where both the feature extractor F F F and the box predictor ( C C C and R R R) are jointly fine-tuned until convergence in the second fine-tuning stage. FRCN is Faster R-CNN for short. Fine-tuning with less iterations, denoted by FRCN/YOLO+ft.
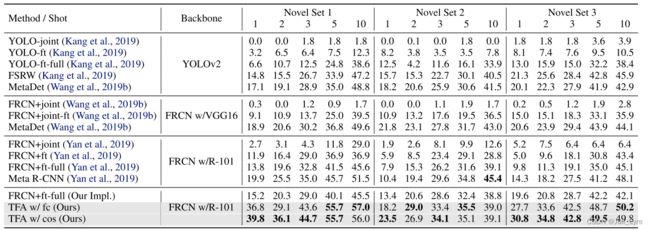
We also compare the cosine similarity based box classifier (TFA+w/cos) with a normal FC-based classifier (TFA +w/fc) and find that TFA +w/cos is better than TFA +w/fc on extremely low shots (e.g., 1-shot), but the two are roughly similar when there are more training shots, e.g., 10-shot.
Generalized few-shot object detection benchmark
我们发现现有基准存在几个问题。 首先,以前的评估协议只关注新类的性能。 这忽略了基类中潜在的性能下降,从而忽略了网络的整体性能。 其次,由于训练样本较少,样本方差较大。 这使得很难从与其他方法的比较中得出结论,因为性能差异可能不大。
我们报告基类的AP(BAP)和整体AP以及新类的AP(NAP)。 这使我们可以观察基础类和新类的性能趋势,以及网络的整体性能。
另外,我们在训练镜头的不同随机样本上训练我们的模型进行多次运行,以获得平均值和置信区间。 在图3中,我们显示了在Pascal VOC的第一次分裂时,在K=1,3,5,10的40次重复运行中的累积均值和95%置信区间。 尽管在第一个随机样本上性能很高,但随着使用更多样本,平均值显著下降。 此外,前几次运行的置信区间很大,尤其是在低镜头场景中。 当我们使用更多的重复运行时,平均值稳定,置信区间变小,这允许更好的比较。

Ablation study and visualization
Weight initialization 在少镜头微调前,我们探讨了两种不同的初始化方法:(1)随机初始化和(2)微调a predictor on the novel set 并使用分类器的权值作为初始化。我们比较了两种方法在K=1,3,10,Pascal VOC和COCO的分裂3上的结果,如表5所示。 在Pascal VOC上,简单的随机初始化可以优于使用微调的新权重的初始化。 在COCO上,使用新的权值可以改善随机初始化的性能。 这可能是由于与Pascal VOC相比,COCO的复杂性和类的数量增加了。 我们对所有Pascal VOC实验使用随机初始化,对所有COCO和LVIS实验使用新颖初始化。
Scaling factor of cosine similarity
可视化
失败情况包括将新对象错误地分类为类似的基本对象,例如,行2列1、2、3和4,错误地定位对象,例如,行2列5,以及丢失检测,例如,行4列1和5。
Meta-learning的一些基本概念
文献1:Few-shot Object Detection via Feature Reweighting论文阅读