韦东山 嵌入式Linux应用开发基础知识 下【串口 IIC SPI
10 串口
因为UART没有时钟信号,无法控制何时发送数据,也无法保证双方按照完全相同的速度接收数据。因此,UART为每个字节添加额外的起始位和停止位,以帮助接收器在数据到达时进行同步;
双方还必须事先就传输速度达成共识(设置相同的波特率,例如每秒9600位)。
02 硬件介绍
信息格式
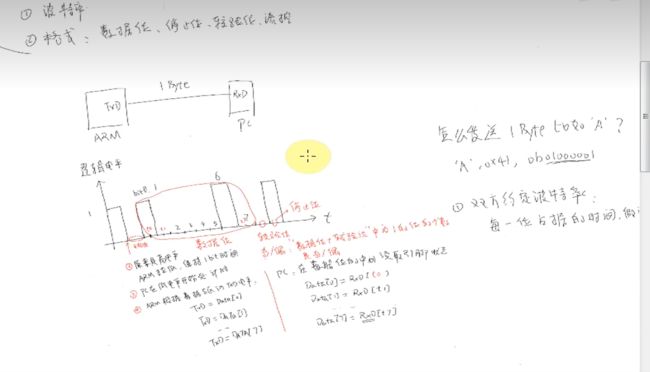 波特率是指每一bit数据占据的时间
波特率是指每一bit数据占据的时间
串口信息的格式是
开始位【把常态的高电平拉低
数据位【从低位数据开始发
奇校验【把电平为1的数据位凑成奇数个 【偶校验同理【但这年头基本不用校验了
停止位【拉高电平

在115200的波特率下,如果每次发送一个字节【8个bit】无奇偶校验位【n】一个停止位【1】
那么每帧数据要占的是10个位【默认开始帧1个bit】因此1秒能发11520帧信息。
硬件实现
【接收端在读取电平信息时,取的是电平变化区间的中间位置,以获得稳定、正确的信息。】
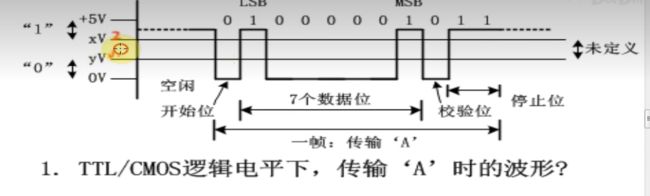
TTL电平,电压范围小,传输距离短。开发板上通常用TTL。
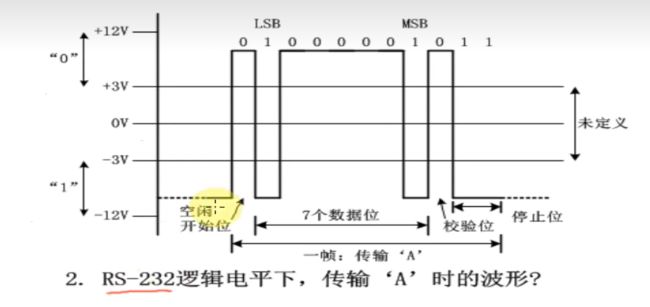
232,电压范围大,传输距离远。电脑用的串口是232的
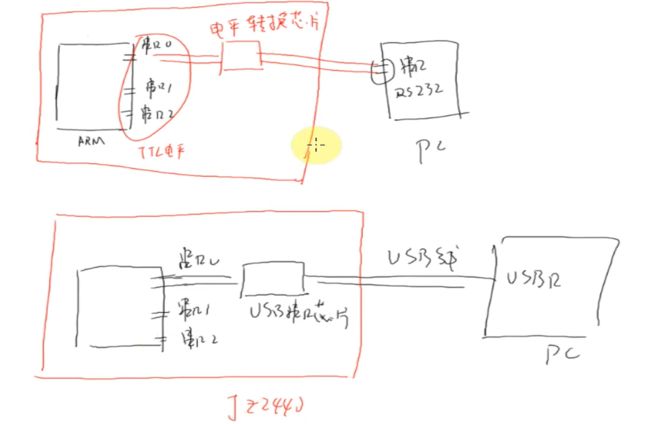
用电平转换芯片或者USB转接
【在arm芯片内部还会有一个
内存 - 串口专用缓冲区 - 串口的发送/接收移位寄存器 - 导线 - [电压转换模块] - 设备的串口接口
这样的流程】
03 tty
tty就是个输入输出的【显示器&键盘】设备,是跟处理器进行通信/调试/交互用的设备。
以前是每个人一个tty,好几个tty设备连接一个处理器大家一起用。
现在每个人都有处理器了,一个人可以用好多tty设备,但没必要搞那么多硬件,所以就可以用一个tty【显示器&键盘】然后在里面开好几个虚拟的tty界面【跟我们开好几个浏览器标签页,开虚拟桌面,是一个道理】

- 把信息输出到3号tty界面【截图里的这个界面就在tty3
- 把信息输出到4号tty界面【4号界面会出现信息
- 把信息输出到前台程序的界面【tty0指的是“当前界面”,会随着界面切换进行更新的那种】
- 为了直观效果,写了一个while循环,一直把信息打印到 ”当前界面“ tty0 , 所以当我们切换到其他tty界面时也能收到输出信息
- 把信息输出到显示屏正显示着的tty界面【tty指的是现在正在用的界面,不会跟着切换】
【可以这样记:我知道要往哪个tty输出,那我直接就写上数字了;我不知道我现在的tty是几号,所以我不填,就是现在的这个界面;我想在切换掉界面的时候还能接收到
之前程序的输出,那我就用0指代所有tty界面】
【另外,串口设备也可以是一个tty终端,它也能从电脑接线出来,接收信息,发送信息,它的代号一般是ttyS0 也可能是ttySAC0】
可以注意到,tty在的位置是/dev/tty 在相同位置还有 /dev/console 其实就是一个权限比较大的tty 。console就是为了打印比较重要的内核信息,而指定了现存的某个tty设备 让它当console 然后在那个界面打印内核信息。可以将console赋值为tty0
04 行规程
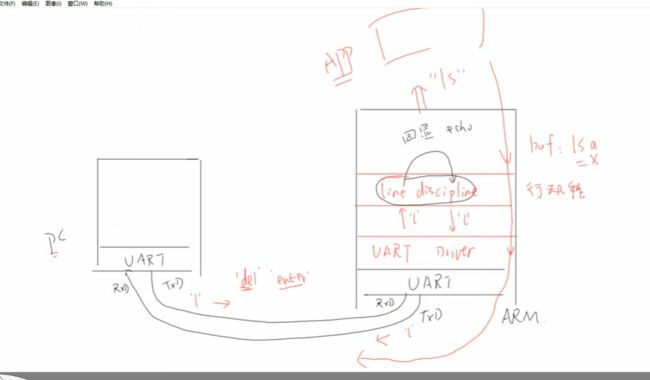
键盘输入信息之后就直接从显示屏上冒出来是理所当然的吗/狗头
键盘输入按键信号 - 串口发送给处理器 - 处理器把数据给行规程进行分析【如果是字母就传回去显示,如果是回车或者退格之类的功能键就进行对应的函数操作】
我们能自己设定行规程
别人写的笔记
05 驱动程序开发相关 .dtb文件
为了读取到扩展板上的串口引脚,需要修改一些底层驱动代码。用专门的编译器编译之后会生成.dtb文件。然后挂载NFS文件系统【大概吧】
对于传统字符驱动的编写有两种方式:
一是在驱动程序中,直接写死硬件资源,如:GPIO、寄存器地址、中断号等,使得硬件改动时,必须修改驱动程序。【单片机开发应该是这类吧?】
二是采用总线驱动platform模型,将硬件资源与驱动软件分离,在platform_device中描述硬件资源,arch/arm/mach-xxx对应的文件,便是以platform_device描述各自CPU对应的硬件资源;在platform_driver中分配/设置/注册 file_operations结构体,
并从platform_device获得硬件资源。这种编写方式使得驱动易于扩展,硬件改动时只需修改platform_device或者platform_driver,这就导致linux内核产生大量的冗余代码。使用设备树的特点在于,在设备树dts文件指定硬件资源,dts被编译为dtb文件,
在启动单板时,U-boot会将dtb文件传给内核,使得驱动程序与硬件分离,我们只需要修改dts文件,便能实现需求。这就是设备树易于扩展,硬件有变动时不需要重新编译内核或驱动程序,只需要提供不一样的dtb文件。
设备树学习(一、设备树基础)
早期的Linux内核(Linux-3.0以前)里的设备信息(platform_device)和驱动信息(platform_driver)都是通过C代码硬写入到Linux内核里去了,这些源文件都在arch/arm/mach-xxx或plat-xxx下。
Linux-3.x之后的内核统一启用Device Tree机制之后,所有的设备硬件信息描述都会放到 arch/arm/boot/dts/
路径下的 xxx.dts文件中描述。这些dts(Device Tree Source)文件并不是C代码,而是具有相应语法格式的源文件。
Linux内核DTB文件启动的几种方式
Linux内核驱动的演变【要看很久】
linux dtb的编译打包过程_小白带你探索Linux设备树1_框架篇V1
Linux设备树DeviceTree快速入门
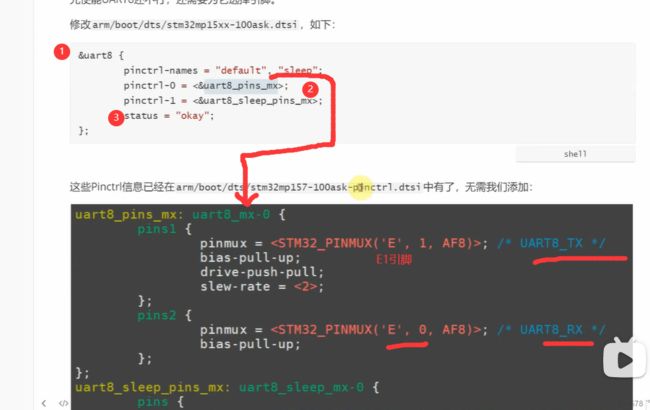
- 这一片灰色区域的代码是需要我们添加到代码文件的底部的。主要功能是使能这个串口
- 尖括号内指向的数据是已经被确定了的引脚,这里系统分配的是E1 和E0引脚
- 赋值为使能
下图就是目标文件的代码,都是前辈呢。

06 串口应用编程
串口教程之母
翻译文档
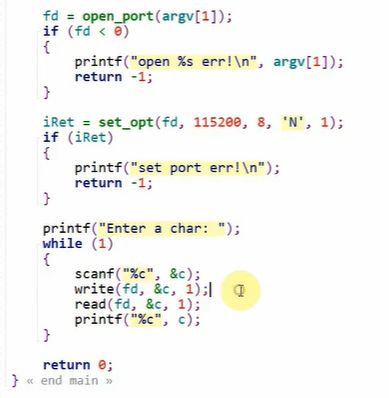
编写一个程序: 读取键盘数据,把数据通过串口发送出去,但串口引脚TXD直接连RXD发送回来,然后程序读取回来的数据并显示在终端上。
在运行这个程序的时候需要输入设备路径,这个设备路径应当是上一步驱动程序里开启后挂载到dev/目录上的对应的tty接口。
open_port()和st_opt() 是我们用户自己写的子函数。
open_port()内部调用了 :
open() //可以设置【[ctrl]+c 等功能键是否作为指令】
fcntl() //可以设置【读数据时是否阻塞】
st_opt() 不仅能设置波特率那些,还能设置【等多久、读多少个字母后再传回数据,这个要在函数里改变量,具体会影响到read()的效果】
07 GPS模块应用

从模块里读一行数据

从数据缓冲区解析数据。但是这样读取数据会读到逗号。

[^,]表示忽略逗号
我的练习
唔,我之前用的微雪的SPI转CAN模块。它用的是python,底层被封装了。。
我是在系统上 通过界面设置 使能了SPI引脚,应该就是对应.dtb文件的设置?
11 IIC
硬件结构
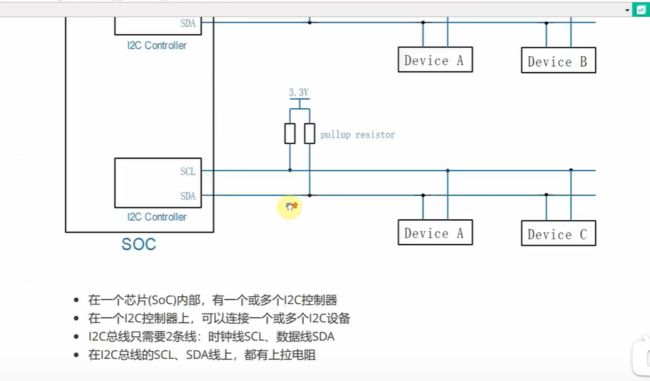
只需要两根线
SCL
SDA
主设备和从设备都能修改SDA这条线上的电平【也都能改SCL的,原理一样的】
两个设备控制一条线的电压,不能直接输出电压,会短路。
所以两个设备控制的是mos管,只要设备置1 使mos管接地,就能拉低电压。
加一个上拉电阻,让电平维持在高电平。
所以,只有俩人都撒手,才是高电平,只要有一个人扯着,就是低电平。
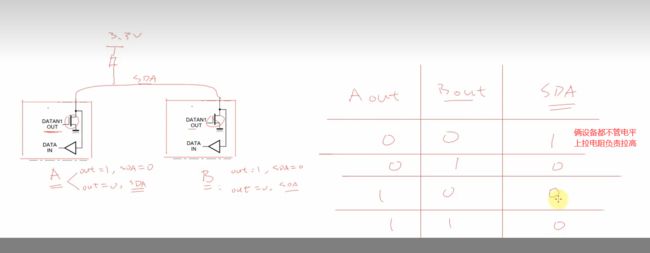
IIC的信号动作定义
两个设备都能控制线上的电平,这样的线居然只需要两根就能多设备通信了。
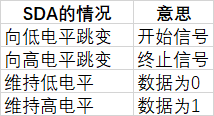
那两根线,各自有【低电平】【高电平】【向低电平跳变】【向高电平跳变】这几种情况。可以组合使用。
通信需要传数据,而且需要信号来做格式区分。串口是用起始位,数据,[可有可无的校验位],停止位。 所以别的通信的基础操作也是这三个吧。【IIC如果非要校验,是通过 多发一帧数据 来实现的,真奢侈啊】
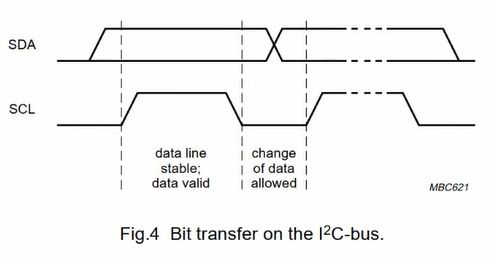
SCL在高电平的时候 SDA的数据才是有效的。
SCL在低电平的时候,SDA要变换电平。而且从设备如果没准备好数据,就会主动拉低SCL,让主设备知道要等着。
SCL在跳变的时候不管事,没啥作用,就是要跳变。。因为只有当两边都撒手,电压才能为1的,所以只有当SCL为1的时候才能确认SDA的数据。


无论读写都需要主设备发起start信号并指定目标设备地址,而且设备都要先回应,然后一方读/写之后另一方要回应。
串口是一对一的,不像总线有那么多设备,所以串口没收到很快就能发现,不需要靠发送回应数据进行确认。
但是,在IIC通信中,起始信号是必须的,结束信号和应答信号都不是必需的。 也就是说,虽然没有应答信号就会确认不了,但你不在乎的话就没关系。
大部分时间是主设备在控制SCL进行数据传输,
从设备要应答的原理就是:在需要应答的时候,主设备撒手了SDA和SCL,如果从设备没在 那也SCL和SDA都被撒手了,那SCL为1读到了为1的SDA,就是凉凉;如果从设备在线,那就会主动把SDA拉低,所以应答信号是低电平。

应用到数据读写,需要规定一些发送内容的信息格式
上一小节提到的读写格式只是最基础的读写动作。而实际上在进行读写的时候还必须要指定数据的寄存器地址。所以地址本身也是数据,需要被发送过去。
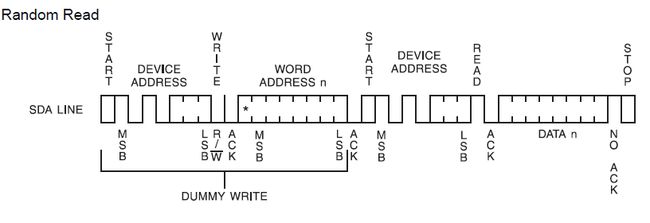
要读从设备里的数据,还得指定从设备里的数据寄存器的地址。所以要先发一个写指令,向那个设备发去它的寄存器的地址。然后再开始新的起始信号,读取从设备传回的数据。

这个例子要发送两次开始指令,所以需要定义两个msg变量来发送。
第0个的buf是主设备要求的目标寄存器地址,是写命令
第1个的buf是一个存储用的变量,保存接收到的data
在终端查看IIC设备情况

列出所有的IIC总线。上图显示有0 1 2 三个IIC总线
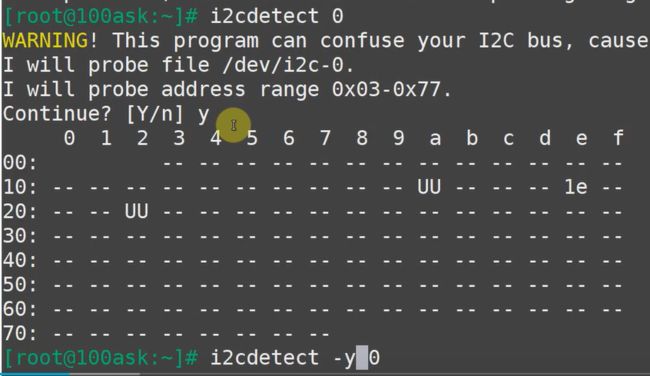
在第0个IIC总线上 挂着3个设备,字母UU表示在地址0x1a 0x22 的设备已经有驱动程序了 直接显示地址0x1e的那个设备是没有对应驱动程序的。【总之,设备地址是到手了】
然后按照模块的数据手册去操作寄存器就行

下图里,Usage后面是信息格式,[ ]里的是可选设置
【注意:下面提到的两个指令是SMBus协议里的指令】【SMBus对于IIC就好像CANopen对于CAN。SMBus协议多限制了一些电压条件,而且必须在一次性传输多个数据之前先发一帧数据说清楚”总数据的长度“然后再发送具体数据】
我们用写指令 通过0号I2CBUS 往0x1e这个地址挂载的设备里的 0号寄存器 写入0x4 让这个从设备进行复位。
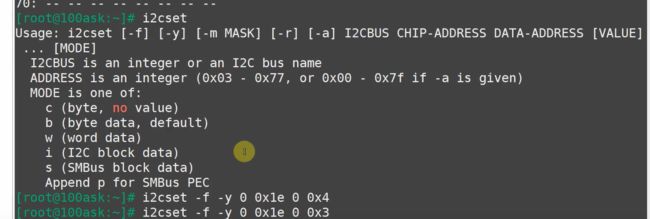
我们用读指令 通过0号I2CBUS 从0x1e这个地址挂载的设备里的 0xc号寄存器 读取数据,如果要一次性读俩字节,就加个w
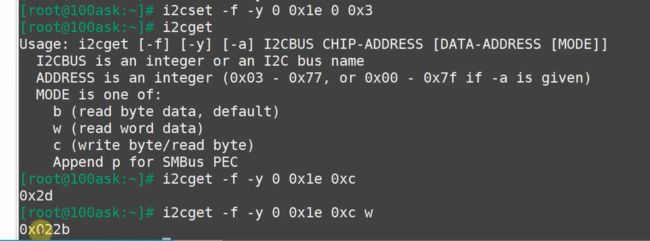
下面这个指令是IIC的基础指令
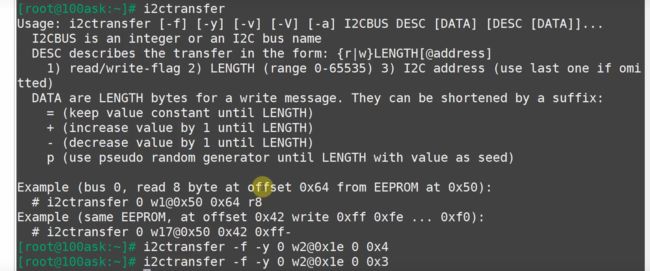

在写代码的时候使用IIC通信

不过,有封装好的可以用。。

SPI
【本小节不是韦东山教程,是SPI协议详解(图文并茂+超详细)
SPI是一个同步的数据总线,也就是说它是用单独的数据线和一个单独的时钟信号来保证发送端和接收端的完美同步。
产生时钟的一侧称为主机,另一侧称为从机。总是只有一个主机(一般来说可以是微控制器/MCU),但是可以有多个从机(后面详细介绍);
SPI是“全双工”(具有单独的发送和接收线路),因此可以在同一时间发送和接收数据,另外SPI的接收硬件可以是一个简单的移位寄存器。这比异步串行通信所需的完整UART要简单得多,并且更加便宜;
硬件结构
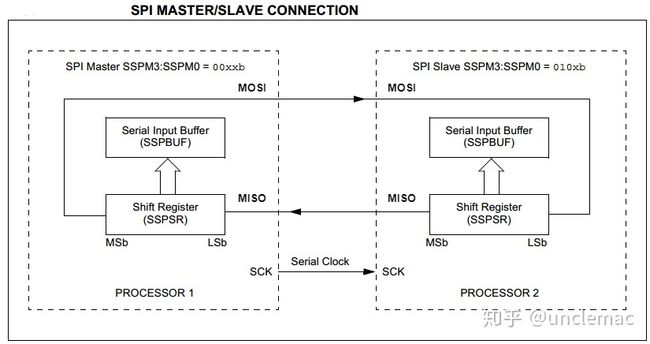
SPI总线包括4条逻辑线,定义如下:
MISO:Master input slave output 主机输入,从机输出(数据来自从机);
MOSI:Master output slave input 主机输出,从机输入(数据来自主机);
SCLK :Serial Clock 串行时钟信号,由主机产生发送给从机;
SS:Slave Select 片选信号,由主机发送,以控制与哪个从机通信,通常是低电平有效信号。
其他制造商可能会遵循其他命名规则,但是最终他们指的相同的含义。以下是一些常用术语;
MISO也可以是SOMI,DIN,DI,SDO或SO【大概吧,不太确定
MOSI也可以是SIMO,DOUT,DO,SDI或SI【查一查手册试一试比较靠谱
SCLK也可以是SCK;
NSS也可以是CE,CS或SSEL;
多从机连接方法
前面说到SPI总线必须有一个主机,可以有多个从机,那么具体连接到SPI总线的方法有以下两种:
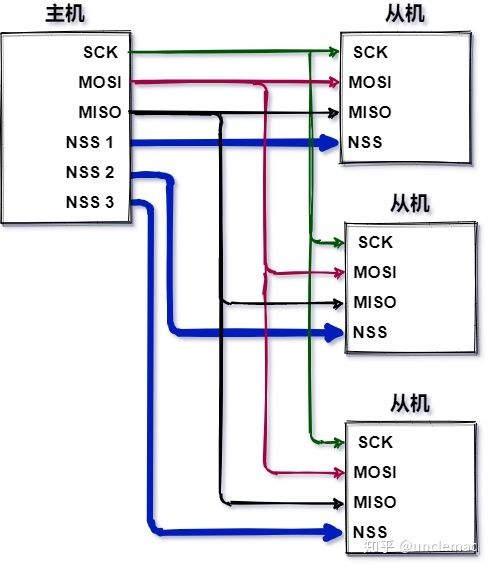
第一种方法:多NSS
通常,每个从机都需要一条单独的SS线。
如果要和特定的从机进行通讯,可以将相应的NSS信号线拉低,并保持其他NSS信号线的状态为高电平;如果同时将两个NSS信号线拉低,则可能会出现乱码,因为从机可能都试图在同一条MISO线上传输数据,最终导致接收数据乱码。
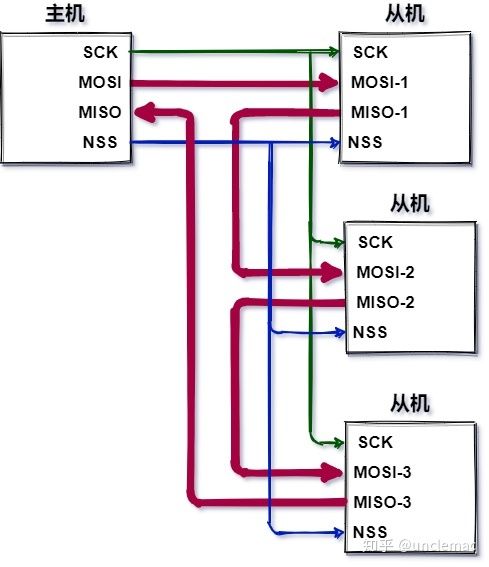
第二种方法:菊花链
菊花链模式充分使用了SPI其移位寄存器的功能,整个链充当通信移位寄存器,每个从机在下一个时钟周期将输入数据复制到输出。
菊花链的最大缺点是因为是信号串行传输,所以一旦数据链路中的某设备发生故障的时候,它下面优先级较低的设备就不可能得到服务了;
另一方面,距离主机越远的从机,获得服务的优先级越低,所以需要安排好从机的优先级,并且设置总线检测器,如果某个从机超时,则对该从机进行短路,防止单个从机损坏造成整个链路崩溃的情况;
通信流程
主机在MOSI线上发送一位数据,从机读取它,而从机在MISO线上发送一位数据,主机读取它。
就算只进行单向的数据传输,也要保持这样的顺序。这就意味着无论接收什么数据,都必须实际发送一些东西!在这种情况下,我们称其为虚拟数据;【强行礼尚往来】
主机先将NSS信号拉低,这样保证开始接收数据;
当接收端检测到时钟的边沿信号时,它将立即读取数据线上的信号,这样就得到了一位数据(1bit);
由于时钟是随数据一起发送的,因此指定数据的传输速度并不重要,尽管设备将具有可以运行的最高速度(稍后我们将讨论选择合适的时钟边沿和速度)。
主机发送到从机时:主机产生相应的时钟信号,然后数据一位一位地将从MOSI信号线上进行发送到从机;
主机接收从机数据:如果从机需要将数据发送回主机,则主机将继续生成预定数量的时钟信号,并且从机会将数据通过MISO信号线发送;
参数设置
时钟速率
从理论上讲,只要实际可行,时钟速率就可以是您想要的任何速率,当然这个速率受限于每个系统能提供多大的系统时钟频率,以及最大的SPI传输速率。
时钟极性CKP
根据硬件制造商的命名规则不同,时钟极性通常写为CKP或CPOL。时钟极性和相位共同决定读取数据的方式,比如信号上升沿读取数据还是信号下降沿读取数据;您必须参考设备的数据手册才能正确设置CKP和CKE。
CKP = 0:时钟空闲IDLE为低电平 0;
CKP = 1:时钟空闲IDLE为高电平1;
时钟相位(或边沿)CKE
根据硬件制造商的不同,时钟相位通常写为CKE或CPHA;
顾名思义,时钟相位/边沿,也就是采集数据时是在时钟信号的具体相位或者边沿;
CKE = 0:在时钟信号SCK的第一个跳变沿采样;
CKE = 1:在时钟信号SCK的第二个跳变沿采样;
优缺点
使SPI作为串行通信接口脱颖而出的原因很多:
全双工串行通信;
高速数据传输速率。
简单的软件配置;
极其灵活的数据传输,不限于8位,它可以是任意大小的字;
非常简单的硬件结构。从站不需要唯一地址(与I2C不同)。从机使用主机时钟,不需要精密时钟振荡器/晶振(与UART不同)。不需要收发器(与CAN不同)。
SPI的缺点:
没有硬件从机应答信号(主机可能在不知情的情况下无处发送);
通常仅支持一个主设备;
需要更多的引脚(与I2C不同);
没有定义硬件级别的错误检查协议;
与RS-232和CAN总线相比,只能支持非常短的距离;