面试笔记二(总结的答案可能有误,感谢批评指正)
持续更新中……
跟谁学一面(10~16)
好好住 golang实习生 一百多人小厂(1~9):
1.mysql主从复制怎么实现?
笔者把这个问题改为:如何实现 MySQL 的读写分离?MySQL 主从复制原理是啥?如果写入数据量过大,主从延迟较大,怎么办?如果读写分离,写后立刻读,发现读不到数据,怎么办?
如何实现 MySQL 的读写分离?
就是基于主从复制架构,搞一个主库,挂多个从库,用主库来写,用从库来读,然后主库会自动把数据同步到从库。
MySQL 主从复制原理是啥?
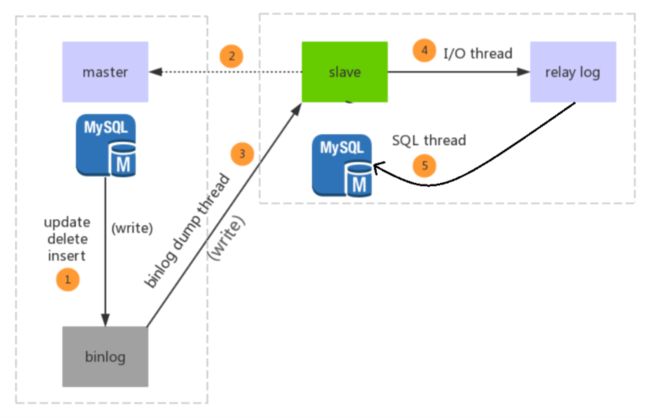
1.主库db的更新事件(updata、insert、delete)被写到binlog。
2.主库创建一个binlog dump thread,把binlog的内容发送到从库。
3.从库创建一个I/O线程,将主库传过来的binlog写入到relay log。
4.从库创建一个SQL线程,从relay log里面读取更新事件并执行,将数据写入从服务器的db中。
写入数据量过大,主从延迟较大,怎么办?
这个问题需要分层回答:
1.上层,流量来源,延迟问题本质上是单位时间内写入过多导致,就比如秒杀活动、跑批,那能不能拉长写入的时间解决呢,把写入限流在时间上分散,降低单位时间内的写入;同时也可以引用消息队列,有队列承接大流量,而队列则控制好并发,逐步消化,确保数据库正常运行。
2.数据库层
a.硬件提升,属于纵向的提升,但提升有限;(不作为主要手段)
b.数据库并行复制技术,传统的主从复制是单线程;通过对业务的事务进行分组,并通过多线程的并发回放,提升从库的写入速度;(当然这个也是有条件的,写入需要分散在多个库表上,单表的写入并行复制效果并不好)
c.切换至DDBS架构,ddbs架构可以理解为数据库并行复制的降维打击,从物理上实现了多点写入,让写入性能具备水平扩容的能力,打散写入压力,确保在从库能承接的范围内。
读写分离,写后立刻读,发现读不到数据,怎么办?
方案a:事务读,即关键的读,如余额、额度等实时性要求高的需求,开启事务读走主库查询数据;
方案b:数据库的同步机制,mysql MGR强同步机制 ; (技术点 raft和paxos一致性协议)
在各节点都写入成功后,才真正写入成功,读各个节点的数据都是一致。(这样也会有一个弊端,写入需要多个节点返回,才算成功,写入性能会有所下降。)
2.怎么看一条sql语句有没有用到索引?
使用explain关键字放在一条执行语句的最前面,执行完后会有两个非常重要的关键字,一个是type,表示访问的类型,如果值是ALL那么走的就是全表扫描,否则是用了其他方法,比如走索引。另一个很重要的关键字是key,表示实际用到的是那个索引字段。
3.联合索引有什么要注意的?
最左前缀法则:如果引用了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
4.怎么加快主从复制效率?
主从复制效率的影响因素主要是binlog的大小。
master端:可以设定哪些数据库需要记录binlog,哪些数据库不需要binlog。
slave端:不仅可以设定哪些数据库需要复制,哪些数据库不需要复制,还可以设定哪些表需要复制,哪些表不需要复制。
只要binlog的大小减小了,实际写入的sql数量就减少了,主从复制效率也就加快了。
5.主从复制是单线程还是多线程?
从mysql5.7开始支持多线程,其中有两个配置选项:
基于数据库(DATABASE):每个数据库只能使用一个线程。
基于逻辑时钟(LOGICAL_CLOCK):可以在一个数据库中并发执行relay log中的事务。
6.redis主从复制怎么实现?
redis的主从复制分为全量同步和增量同步
全量同步:一般发生在从服务器初始化阶段,主服务器执行BGSAVE命令生成RDB快照文件,并将此后所有的写命令记录在缓冲区,主服务器向所有从服务器发送快照文件,从服务器收到快照文件后就丢弃所有旧数据,载入收到的快照文件。主服务器发完快照文件后开始向从服务器发送缓冲区中的写命令,从服务器完成快照载入后就开始接收并执行来自服务器缓冲区的写命令。
增量同步:指从服务器完成初始化后开始正常工作,主服务器发生写操作同步到从服务器的过程。增量同步的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
redis主从同步策略:Redis的策略是,无论如何,首先会尝试进行增量同步,如果不成功,要求重新进行全量同步。
7.用过的数据类型?
点击跳转到第28题:28.redis数据类型(string, set什么的)
8.go的协程有什么用?
主要用来提升CPU的利 用率。go协程可以让用户非常轻松的实现多任务模型,开启一个任务只需要用一个go关键字,同时它是轻量级的,占用资源非常少。
9.进程、线程、协程区别:
进程:进程是资源分配的基本单位,每个进程都有自己独立的内存空间。进程在创建或撤销时,系统都要为之分配或回收资源,同时在进程切换时,还涉及当前CPU环境变量的保存以及新调度过来的进程CPU环境的设置,这些开销都非常大。
线程:线程是CPU调试的基本单位,不拥有资源但可以访问所属进行的资源。线程在切换时只需要保存和设置少量寄存器的内容开销很小。
协程:协程是用户态轻量级线程,所占用内存比线程小,线程是MB级别的,而协程是KB级别的。协程不被操作系统内核管理,完全由用户程序控制,系统开销少,性能高。
背就完事了
总结:我了解的大多数都是底层实现相关知识,面试官都没怎么问(我猜是因为他自己不太懂没敢问),具体使用我经验不多, 有几个相关的没打出来。
但是面试官夸我好学(我当场就笑了),愿意主动了解底层知识。很看好我
结果:拿下!面试后半小时hr就打电话给我谈薪资,其实我只是想拿这个小公司练练手为明天的面试做准备
点击回到目录
跟谁学一面(10~16)
10.介绍下GMP模型
这部分内容很多,但是我当时太紧张了,说了条理感觉不是很清晰,感觉有点可惜
GMP模型:

首先是Goroutine调度器,从上到下分别是:
1.全局队列:存放等待运行的goroutine。
2.P的本地队列:也是存放等待运行的goroutine,每个队列存放的goroutine数量不超过256个,新建goroutine时,goroutine会优先存放在本地队列,如果本地队列满了,则会把本地队列中一半的goroutine移动到全局队列中。
3.P列表:P列表的数量代表可以并行运行的协程数量,P列表的数量可以手动设置,默认等于CPU核心数。
接下来在Goroutine调度器和操作系统调试器之间有一层内核线程M:
M的数量也是可以手动设置的,M是会动态改变的,如果一个M阻塞了,且还有goroutine没有执行完,P就会去找空闲的M,如果没有空闲的,那么P就会创建一个新的M。
M的主要任务就是绑定一个P,然后从P的本地队列中获取一个goroutine,如果本地队列为空则尝试从全局队列拿一些goroutine放到自己的本地队列,如果全局队列为空则尝试通过epoll获取,如果还是没有,则从其他P的本地队列偷一半放到自己的本地队列中。
再往下就是操作系统调试器,负责把内核线程M分配到CPU的核上执行。
调度器的设计策略:
复用线程:避免频繁的创建、销毁线程,而是对线程的复用。
1)work stealing机制
当本线程无可运行的G时,尝试从其他线程绑定的P偷取G,而不是销毁线程。
2)hand off机制
当本线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程执行。
利用并行:GOMAXPROCS设置P的数量,最多有GOMAXPROCS个线程分布在多个CPU上同时运行。GOMAXPROCS也限制了并发的程度,比如GOMAXPROCS = 核 数/2,则最多利用了一半的CPU核进行并行。
抢占:在coroutine中要等待一个协程主动让出CPU才执行下一个协程,在Go中,一个goroutine最多占用CPU 10ms,防止其他goroutine被饿死,这就是goroutine不同于coroutine的一个地方。
全局G队列:在新的调度器中依然有全局G队列,但功能已经被弱化了,当本地获取不到goroutine时,它可以从全局G队列获取G。
"go func()"经历了什么过程:
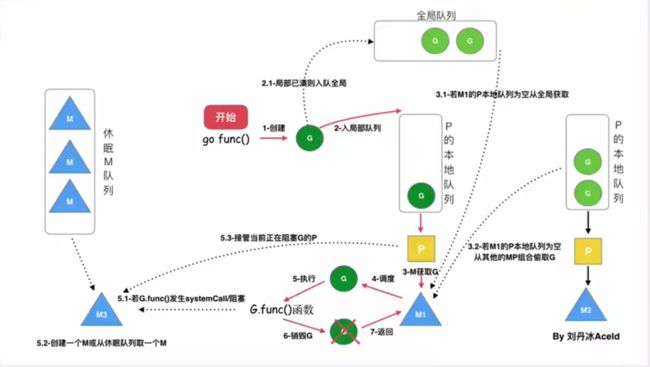

调度器的生命周期: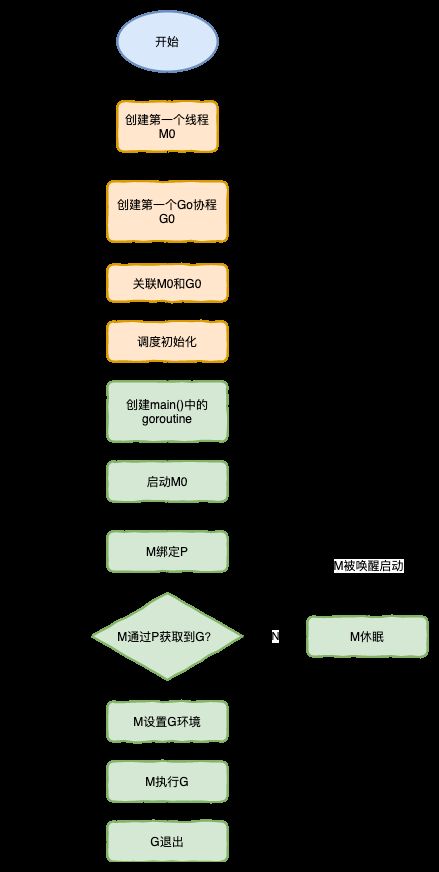
11.介绍下channel?无缓存和有缓存的区别?读关闭的channel会怎样?
都答上了
linux相关:
12.常用什么命令?
vim、man(内容多而详细)、help(只支持查看shell【命令解释器,用户与内核交互的桥梁】里的的命令)
13.了解什么线程资源消耗查看相关的命令?
只记得一个ps -ef |
14.最常用的数据类型?string底层实现?SDS怎么扩容?
15.手写二叉树的三种遍历方式
纸上手写了一遍
16.能说说不用递归的方式怎么实现二叉树先序遍历?谈谈思路
这个题我在LeetCode上见过,当时没写出来,后面就忘了看了,血亏
答了个DFS
3、为什么会想到用DFS
感觉跟先序遍历模式差不多
4、用DFS要用到栈还是队列
被问的脑子有点懵,答了个队列,后面想想应该用栈的
说完队列后我又说了句感觉不对劲,怎么好像变成BFS了。
面试官估计也看出我有点懵了,就没继续追问了
5、栈和队列的区别
先进先出,先进后出
算法环节这一块真的特别搞心态,面试官那信号又不好又吵,老是听不清他在问什么
总结:小厂面试跟大点的厂的面试感觉完全不一样,昨天的小厂问的问题都很浅。跟谁学上来就问底层原理,
喜欢抓住一个地方一直往下问问到你不懂为止。给人的感觉也更加紧张。这一次面试自己感觉自己发挥的不怎么好。
结果:问现在大三是不是还在上课,我说拿到offer可以申请去实习。最后让我下周一下周二保持电话畅通。
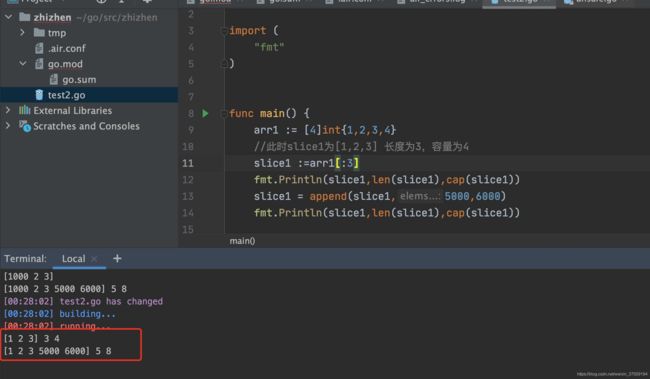
`货拉拉 一面 北京(HR说的是实习,面试官直接说过了发校招offer) 40分钟:` 1、自我介绍 2、有什么想了解的问他 3、切片底层 
举个例子来演示下
package main
import (
"fmt"
)
func main() {
arr1 := [4]int{1,2,3,4}
//此时slice1为[1,2,3] 长度为3,容量为4
slice1 :=arr1[:3]
fmt.Println(slice1,len(slice1),cap(slice1))
slice1 = append(slice1,5000,6000)
fmt.Println(slice1,len(slice1),cap(slice1))
}
此时容量由原来的4扩容到了8,你以为就是简单的2倍吗?那你可真理解错了,你得知道他背后扩容的原因,我来给你计算下
1、原来的容量为4,追加了5000,6000后变为了6个,此时42>6,满足了脑图中的第二种情况,并且元素个数小于1024,先扩容2倍
2、由于64位操作系统下,一个int类型占8个字节,所以88=64
3、此时匹配操作系统预先分配好的内存规格,规则正好匹配了64,所以用64/8=8,所以扩容后的容量为8
咱们再来一个例子看你是否真正理解了他的扩容规则, 这个例子最后容量为10
package main
import (
"fmt"
)
func main() {
arr1 := [4]int{1,2,3,4}
//此时slice1为[1,2,3] 长度为3,容量为4
slice1 :=arr1[:3]
fmt.Println(slice1,len(slice1),cap(slice1))
slice1 = append(slice1,5000,6000,7000,8000,9000,10000)
fmt.Println(slice1,len(slice1),cap(slice1))
}
慌不慌,你是不懂了吗?不懂我给你好好算一下
1⃣️原来容量是4,此时追加了5个元素,变为了9
2⃣️42<9,满足脑图中的第一个条件,由于int类型在64位操作系统下占用8个字节,所以用98=72
3⃣️所以此时需要匹配的内存规格为80
4⃣️用80/8=10,所以此时容量为10
···
元素个数大于1024的我就不给你展示了,原理都是一样的,认认真真看完之后扩容规则肯定就懂了,不用再看其他的了
总结:切片扩容规则和你追加的元素个数有关
切片扩容和你匹配的操作系统分配的内存规格有关
和你定义的切片类型有关
到此这篇关于golang切片扩容规则实现的文章就介绍到这了,更多相关golang切片扩容 内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
4、Channel底层
5、GMP模型
6、GC了解吗? (后面追问写屏障工作原理没答出来)
7、乐观锁介绍下 面试官觉得我答得不好,好像想让我用操作系统的知识点去解释
8、Mysql ACID介绍
9、Mysql 隔离级别
10、Mysql 行锁有用过吗? 没有
11、缓存雪崩、缓存穿透、缓存击穿介绍下,分别有什么解决方法?
淦,八股文背忘了,解决方法想起来一部分
设计题:
有个服务最多支持1000QPS,大于1000就丢掉,让我设计一个算法实现?
提示了令牌桶和滑动窗口,还是不会。。
算法:
记事本写翻转字符串 ???淦,瞧不起人
面试官最后说如果我现在发offer你能不能马上来?见我犹豫直接说我知道现在秋招,后面你要有面试直接在办公室面,要是能去百度腾讯我们也不会拦你
字节电商提前批 一面:
自我介绍
讲下实习中映像最深刻的经历
算法 leetcode143 重排链表 说出时间和空间复杂度
Mysql varchar和text的底层区别
看我项目用了LRU,问为什么OS为什么要页面置换
为什么要有页
无限大内存还需要页吗
为什么map不能并发访问
Http首部有哪些字段
Http长连接短连接,各自有什么优缺点
怎么区别http重定向
Http2.0和1.0的区别
还有一些很细节的问题想不起来了
总结:被吊打。。 八股文真就一点不问,大厂校招面试就跟聊天一样,你说到什么知识点就可能突然深挖,所以别嘴欠说到不熟的点。操作系统和计网考察的很深,卒。
知乎 校招 一面 1小时:
1、自我介绍
2、讲讲实习的经历
先讲了查线上事故的经历(编的),主要是循环开goroutine导致的cpu和内存告警,最后我的解决方法是限制goroutine数量。面试官说这样会导致接口耗时增加,可以试试扩容。
然后讲了一个业务需求,顺便吐槽了下产品。
项目:
1、LRU实现 双链表+map
2、怎么实现热点数据的缓存 LRU分层
看样子你对缓存很了解啊,问问Redis吧:
1、redis zset底层 ziplist 和 字典+跳跃表
2、字典的作用
3、跳跃表实现
4、跳跃表复杂度 回答logn 面试官说这应该是是最优时间吧
5、redis持久化 RDB和AOF
6、AOF文件太大怎么办? 猜了删了AOF改生成RDB
7、分布式锁怎么用? setnx+expire
8、抢到锁的程序还没运行结束锁过期了怎么办? 猜的不断延长生命周期,最后手动释放锁,好像猜对了
9、Redis 怎么保证和DB数据同步 不懂,每答对
MySql:
1、讲B+树
2、聚簇索引
3、Select * 和 select name 哪个快,为什么? 说了半天答错了
4、事务隔离级别
5、讲下MVCC 讲了隐藏字段的部分,面试官很贴心纠正了我的说法,又给我讲了5分钟的readdview原理。
6、Innodb怎么解决幻读问题 mvcc+间隙锁 面试官又跟我聊了半天mvcc能不能解决幻读,说业内没有确定说法。
网络:
1、select、poll、epoll介绍下select
算法:
合并三个有序数组,口述 双指针,两两合并
很多个呢? 分治
不用写代码就是爽
总结:上次被字节虐了之后知乎给了我温暖,整个过程像聊天一样轻松,面试官听声音很年轻,问的问题八股偏多也很具体,知乎好感+1.
百度 智能汽车部门 一面 1小时:
1、自我介绍
2、介绍项目,就让我介绍了下
3、Linux了解嘛?
了解,没问问题!!
4、TCP三次握手为什么三次,四次挥手为什么四次?
5、Mysql慢查询怎么优化?
查看binlog日志根据时间戳找到sql,explain看看索引是否有问题
6、MySQL优化点?
答了水平切分垂直切分和采用自增ID别用uuid
7、Go的协程了解嘛?
8、Go channel有缓冲和无缓冲的区别?
讲了一大堆channel底层,面试官说底层平时做业务又用不到,说说应用场景
无缓存用于协程同步,有缓存用于协程通信
9、Go 有共享内存嘛?
全局变量?后面面试官说好像Go没有哈~。。。
10、其他语言有了解嘛,Python了解嘛?
太久没用忘记了,不会
算法:给你找个简单的吧~
1、翻转切片 ???似曾相识啊,百度怎么跟拉拉一样了
2、判断两个map是否有相同KV
直接记事本手撸
11、感觉这次面试题难度怎么样?
都挺基础的
反问
总结:面试官很和蔼,问的问题都很基础实用,感觉像是真缺人。后面反问说这个部门现在写Go的就两个,其他都是C++,python。难怪问我会不会C++,Python。这点挺坑的呀,看看后面有没有二面吧。
百度健康业务部一面:
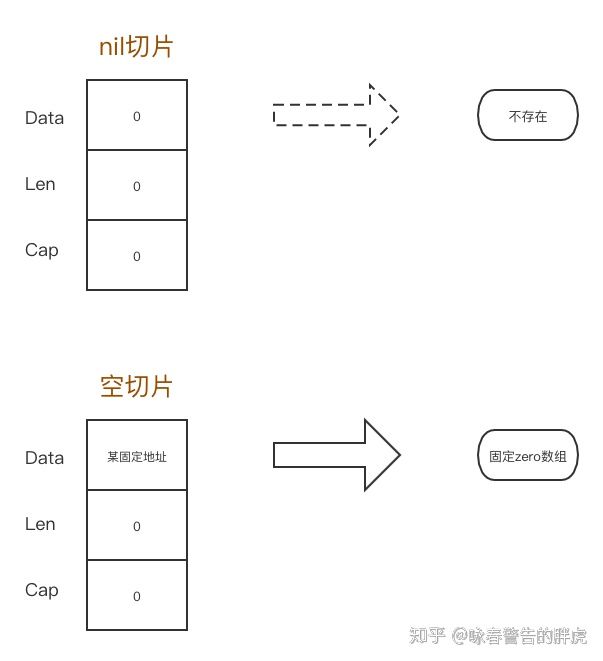
1、nil切片和空切片的区别?
package main
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
var s1 []int // nil切片
s2 := make([]int,0) // 空切片
s4 := make([]int,0) // 空切片
fmt.Printf("s1 pointer:%+v, s2 pointer:%+v, s4 pointer:%+v, \n", *(*reflect.SliceHeader)(unsafe.Pointer(&s1)),*(*reflect.SliceHeader)(unsafe.Pointer(&s2)),*(*reflect.SliceHeader)(unsafe.Pointer(&s4)))
fmt.Printf("%v\n", (*(*reflect.SliceHeader)(unsafe.Pointer(&s1))).Data==(*(*reflect.SliceHeader)(unsafe.Pointer(&s2))).Data)
fmt.Printf("%v\n", (*(*reflect.SliceHeader)(unsafe.Pointer(&s2))).Data==(*(*reflect.SliceHeader)(unsafe.Pointer(&s4))).Data)
}
输出:
s1 pointer:{Data:0 Len:0 Cap:0}, s2 pointer:{Data:824634207952 Len:0 Cap:0}, s4 pointer:{Data:824634207952 Len:0 Cap:0},
false //nil切片和空切片指向的数组地址不一样
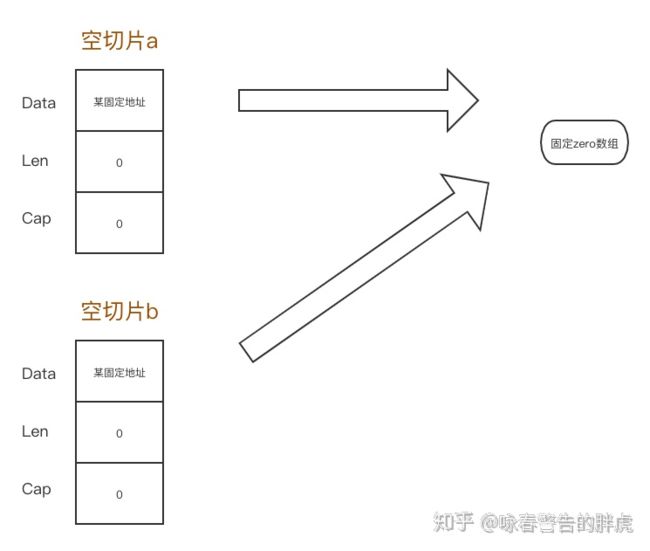
true //两个空切片指向的数组地址是一样的,都是824634207952
nil切片和空切片最大的区别在于指向的数组引用地址是不一样的。
所有的空切片指向的数组引用地址都是一样的
2、协程通信?
用通道channel来实现,channel分为有缓冲和无缓冲的,如果缓冲的大小设为0或者不设置,那么就是无缓冲通道,无缓冲通道就类似操作系统用来互斥操作的信号量,无缓冲通道是同步的,没有数据发送或读取都会阻塞。当channel的缓冲大小大于等于1时,那这个channel就是有缓冲通道,有缓冲通道是异步通道,在缓冲装满或为空之前都不会阻塞。
其他忘了
Mysql相关:
1、mysql有什么索引?怎么选择?
2、慢sql怎么查询?怎么优化?
如何打开慢查询 : SET GLOBAL slow_query_log = ON;
将默认时间改为1S: SET GLOBAL long_query_time = 1;
(设置完需要重新连接数据库,PS:仅在这里改的话,当再次重启数据库服务时,所有设置又会自动恢复成默认值,永久改变需去my.ini中改)
找到慢sql,后然后用explain放在一个sql的最前面来分析sql,里面最重要的是type字段,如果值是ALL或者Index,说明就需要优化了,可以从sql语句编写考虑优化,或者建索引。还有一个字段是key,如果走了索引,这个key的值显示的是用到了哪个索引字段
3、如果设计一个简单的购物数据库,会涉及什么表?
用户表、商品表、订单表、日志表、管理员表,如果要做分库分表的话,使用垂直拆分时把把表拆得更细,比如把用户表拆成基本表和信息表,基本表只包含用户id、用户名、密码,这个表可以单独部署在一台服务器上,主要用户处理登录业务,然后后另一个是用户id、手机号、收货地址等,主要是用于处理订单业务。
订单表,商品表 小姐姐说少答了个用户表,问题不大
Redis相关:
1、redis数据类型?有什么区别?
2、你常用哪些类型?
3、雪崩,穿透,击穿?
Docker相关:
1、启动容器命令?
启动一个镜像:docker run + 镜像名(相当于docker create + 镜像名、docker start + 容器名)
启动一个已经停止的容器:docker start + 容器名
Docker start
2、搜索镜像?
Docker search / docker pull
搜索镜像:docker search (docker search java这条命令搜索存放在 Docker Hub中的镜像。执行该命令后, Docker就会在Docker Hub中搜索含有 java这个关键词的镜像仓库。)
下载镜像:docker pull 从远程下载镜像
列出镜像:docker images
删除镜像:docker rmi + 镜像名
列出正在运行的容器:docker ps
列出所有容器:docker ps -a
停止容器:docker kill + 容器名或容器id
docker端口映射:docker run -t -p -d ip:服务器端口:容器端口 启动脚本位置
dockerfile命令:
FROM:指定镜像基于哪个基础镜像创建,比如FROM java:8,基于java8这个版本创建镜像,到时运行时会自动拉取这个镜像
ADD: ADD 《src》 《destination》destination是容器内的路径。source可以是URL或者是启动配置上下文中的一个文件。
CMD:提供了容器默认的执行命令。
Dockerfile中的命令COPY和ADD命令有什么区别
COPY与ADD的区别COPY的SRC只能是本地文件,ADD的SRC可以是远程的URL,其他用法一致
Linux相关:
1、怎么查询一个文件的行数?
这个不会。。
wc -l filename 就是查看文件里有多少行
wc -w filename 看文件里有多少个word。
wc - c 统计字节数。
wc -L filename 文件里最长的那一行是多少个字
2、怎么查看CPU占用?
TOP(可以查看CPU、内存利用率)
3、怎么查看端口占用?
Netstat -anp | prep 3306(查看3306端口占用)和lsof -i:6379()
4、怎么在文件中找到指定文本位置?
Cat 文件| grep ‘文本’
算法: 给你出个简单的吧~(这句话我是第几次听到了)
1、两数之和…
总结:挺基础的,约了明天下午二面。