网络爬虫之Selenium(可视化)爬虫
一、网络爬虫介绍
1、什么是爬虫:
网络爬虫(web crawler)也叫网页蜘蛛,网络机器人,是一种用来自动浏览万维网的程序或者脚本。爬虫可以验证超链接和HTML代码,用于网络抓取(Web scraping)。网络搜索引擎等站点通过爬虫软件更新自身的网站内容(Web content)或其对其他网站的索引。
2、爬虫的由来(为什么会有爬虫):
随着时代的发展,信息时代引领时代潮流,但我们到网上去搜集信息时,查找网上的海量信息就像大海捞针,森罗万象,要提取到对我们有用的信息,我们需要一种能自动获取网页内容并可以按照指定规则提取相应内容的程序,就这样爬虫就诞生了。
3、爬虫的原理:
爬虫首先从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
用eclipce来实现爬虫技术:
1、将浏览器加载到jvm
2、创建浏览器对象
3、打开对应网址对应的网站
4、爬虫的爬取对象:
包括互联网所有可以爬回的数据、文字、视频、图片,以及非结构化数据。
二、爬虫(selenium可视化爬虫)具体案例:
1、关于python爬虫的说法,这里有一个误解,爬虫并不是Python独有的,可以做爬虫的语言有很多,例如:
PHP,JAVA,C++,Python等等,到多数程序员选择Python做爬虫,是因为Python相对来说简单,而且功能比较齐全。今天我跟大家分享爬虫在JAVA语言导入selenium做的
2、实操:
一、爬虫的准备工作:(用JAVA语言来做爬虫,并且用的是Maven项目,也可以用web项目,)
步骤:
1、在Eclipse中创建一个Maven项目,创建之后要将Maven依赖,以及web版本,还有pom.xml、project.Facets配置好。
2、导入selenium相关依赖
org.seleniumhq.selenium selenium-java 3.141.0 mysql mysql-connector-java 5.1.47 要是用web项目去爬虫,就要导入相关的jar包:
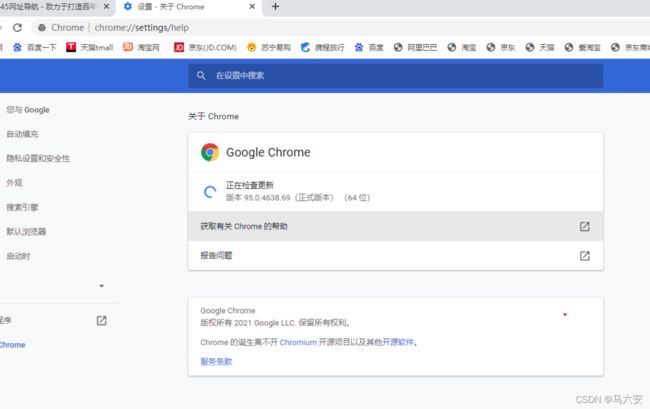
3、下载与浏览器版本相同的压缩包,我用的是谷歌浏览器,在网页主界面点击帮助关于即可查看自己所用浏览的版本:
如果没有相同版本的压缩包,就选版本最近的压缩包:我的浏览器版本是95.0.4638.69,没有这个版本就下载相近的版本:
点进去之后,无论是什么浏览器,都选择chromedriver_win32.zip,这个文件夹:
vccccccccccccccc
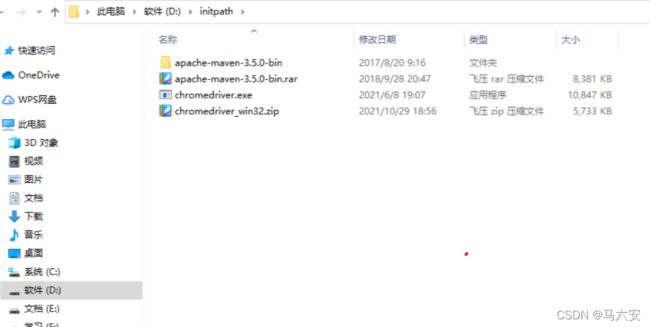
4、将下载的驱动包放置到一个英文文件夹中:
就这样爬虫的准备工作就已经完成了。


二、案例来讲解爬虫
案例一:获取到百度网页:
1、用JAVA语言做爬虫的思路:
1、将浏览器加载到jvm
2、创建浏览器对象
3、打开对应网址对应的网站
2、具体代码:
package com.zking.selenium; import org.openqa.selenium.WebDriver; import org.openqa.selenium.chrome.ChromeDriver; public class demo1 { public static void main(String[] args) { System.setProperty("webdriver.chrome.driver", "D:\\initpath\\chromedriver.exe");//以键值对的形式设置, // webdriver.chrome.driver是那个驱动包, // D:\\initpath\\chromedriver.exe是指那个解压文件的路径 WebDriver driver=new ChromeDriver();//得到一个谷歌浏览器, driver.get("http://www.baidu.com");//得到百度页面 } }3、运行效果:

案例二:获取博客:爬取博客内容分为爬取博客的标题,博客的摘要以及博客的发布时间:
先跟大家讲一讲思路:(注意:要用到找规律的思想)
1、首先获取到跳转到我的博客网页的网站
2、获取到最近全部的博客元素,注意只有三十篇。
3、获取每篇文章的标题、摘要以及发布时间的Xpath。
4、遍历最近博客数组,之后将以上三个元素内容全部打印出来。
先从网上抓一篇博客,就拿自己的博客做案例:
1、首先获取到跳转到我的博客网页的网站:
我的博客的网站为:"https://blog.csdn.net/boy_10?t=1"
相关代码:
System.setProperty("webdriver.chrome.driver", "D:\\pachong\\chromedriver.exe"); WebDriver driver = new ChromeDriver(); driver.get("https://blog.csdn.net/boy_10?t=1");2、获取到最近全部的博客元素(不是全部):
根据节点找到对应的元素数组方法:(列一行代码)
Listboxs = driver.findElements(By.className("blog-list-box")); 获取到该节点里全部的博客:
Listboxs = driver.findElements(By.className("blog-list-box")); System.out.println(boxs.size()); 3、获取每篇文章的标题、摘要以及发布时间的Xpath。
首先讲解一下怎么获取到对应元素的Xpath:(以获取摘要内容为例:)
3.1获取关于标题的Xpath:

获取单个节点的方法:
driver.findElement(By.xpath());第一篇博客标题的Xpath:
[@id="floor-user-profile_485"]/div/div[2]/div/div[2]/div/div[2]/div/div/div[1]/article/a/div[1]/h4获取一篇标题还不够,我将要获取到全部标题的Xpath,这就要使用到了找规律的思想,找三篇博客的Xpath进行对比:
第一篇博客标题的Xpath:[@id="floor-user-profile_485"]/div/div[2]/div/div[2]/div/div[2]/div/div/div[1]/article/a/div[1]/h4 第二篇博客标题的Xpath:[@id="floor-user-profile_485"]/div/div[2]/div/div[2]/div/div[2]/div/div/div[2]/article/a/div[1]/h4 第三篇博客标题的Xpath:[@id="floor-user-profile_485"]/div/div[2]/div/div[2]/div/div[2]/div/div/div[3]/article/a/div[1]/h4可以得出规律,在每一篇博客标题的Xpath中,发现在atricle前的数字是依次增加的。
所以可以写出得到最近全部博客标题的Xpath,在遍历的时候将数字替换成i;
博客标题的遍历:WebElement titleEle = driver.findElement( By.xpath("//*[@id=\"floor-user-profile_485\"]/div/div[2]/div/div[2]/div/div[2]/div/div/div[" + i + "]/article/a/div[1]/h4"));3.2获取关于摘要、发布时间Xpath:
摘要Xpath:
第一个摘要Xpath:[@id="floor-user-profile_485"]/div/div[2]/div/div[2]/div/div[2]/div/div/div[1]/article/a/div[2] 第二个摘要Xpath:[@id="floor-user-profile_485"]/div/div[2]/div/div[2]/div/div[2]/div/div/div[2]/article/a/div[2] 第三个摘要Xpath:[@id="floor-user-profile_485"]/div/div[2]/div/div[2]/div/div[2]/div/div/div[3]/article/a/div[2]可以写出得到最近全部摘要的Xpath,在遍历的时候将数字替换成i;
博客摘要的遍历:WebElement summaryEle = driver.findElement( By.xpath("//*[@id=\"floor-user-profile_485\"]/div/div[2]/div/div[2]/div/div[2]/div/div/div[" + i + "]/article/a/div[2]"));发布时间Xpath:
第一个发布时间Xpath: [@id="floor-user-profile_485"]/div/div[2]/div/div[2]/div/div[2]/div/div/div[1]/article/a/div[3]/div[2]/span[3] 第二个发布时间Xpath:[@id="floor-user-profile_485"]/div/div[2]/div/div[2]/div/div[2]/div/div/div[2]/article/a/div[3]/div[2]/span[3] 第三个发布时间Xpath:[@id="floor-user-profile_485"]/div/div[2]/div/div[2]/div/div[2]/div/div/div[3]/article/a/div[3]/div[2]/span[3]所以可以写出得到最近全部博客发布时间的Xpath,在遍历的时候将数字替换成i;
博客发布时间的遍历:WebElement timeEle = driver.findElement( By.xpath("//*[@id=\"floor-user-profile_485\"]/div/div[2]/div/div[2]/div/div[2]/div/div/div[" + i + "]/article/a/div[3]/div[2]/span[3]"));4、遍历最近博客数组:
代码:
package com.test; import java.util.List; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.chrome.ChromeDriver; /** * 在校生博客抓取案例 * @author Administrator * */ public class demo2 { public static void main(String[] args) { System.setProperty("webdriver.chrome.driver", "D:\\pachong\\chromedriver.exe"); WebDriver driver = new ChromeDriver(); driver.get("https://blog.csdn.net/boy_10?t=1"); Listboxs = driver.findElements(By.className("blog-list-box")); System.out.println(boxs.size()); for (int i = 1; i <= boxs.size(); i++) { WebElement titleEle = driver.findElement(By.xpath("//*[@id=\"floor-user-profile_485\"]/div/div[2]/div/div[2]/div/div[2]/div/div/div["+i+"]/article/a/div[1]/h4")); System.out.println(titleEle.getText()); WebElement summaryEle = driver.findElement(By.xpath("//*[@id=\"floor-user-profile_485\"]/div/div[2]/div/div[2]/div/div[2]/div/div/div["+i+"]/article/a/div[2]")); System.out.println(summaryEle.getText()); WebElement timeEle = driver.findElement(By.xpath("//*[@id=\"floor-user-profile_485\"]/div/div[2]/div/div[2]/div/div[2]/div/div/div["+i+"]/article/a/div[3]/div[2]/span[3]")); System.out.println(timeEle.getText()); } } } 注意事项:注意遍历数组时,数字是从1开始:
运行结果:


案例三:获取二进制文件:比如图片、音乐、视频。
这个案例是讲解如何获取网站图片:
1、注意:接下来的代码可以抓取没有对应网站限制的资源
网站限制的方式有以下三种:
1、在某一时间段/min访问60次,会被拉入黑名单--->IP黑名单 2、对应网站会甄别,是人工访问,还是程序访问,是程序访问,就会被访问 3、携带请求的session2、二进制文件资源抓取的思路:
1、按照文字抓取的方式,获取资源的具体地址 2、根据具体地址,通过IO流下载到本地 2.1将具体地址的资源转换成输入流 2.2将对应资源写到本地,需要构建输出流3.代码:
3.1、按照文字抓取的方式,获取资源的具体地址:
System.setProperty("webdriver.chrome.driver", "D:\\inits\\chromedriver.exe"); WebDriver driver = new ChromeDriver(); driver.get("放网页路径");3.2、根据具体地址,通过IO流下载到本地
3.2.1:将具体地址的资源转换成输入流:
// 通过统一资源定位符,获取资源对象 URL url = new URL(src); // 将资源对象转换成输入流 InputStream in = url.openStream();3.2.1:将对应资源写到本地,需要构建输出流:
// 获取图片格式 src = src.substring(src.lastIndexOf("."));// 下载图片格式 FileOutputStream fout = new FileOutputStream("D:/novel/" + UUID.randomUUID().toString() + src);//构建输入流 BufferedOutputStream bout = new BufferedOutputStream(fout);//buffer增加效益 byte[] b = new byte[1024]; while (true) { int len = in.read();//.read()方法返回的是0到255范围的内的int字节值 System.out.println(len); if (len == -1)//到达流末尾而没有可用的字节,就会停止下载 break; bout.write(b, 0, len);三个参数分别是:b:读取文件字节值最大值为1024,0:读取文件从0开始,len:每次读取文件时,写入的字节长度。 }.write() 这个方法的意思是:读取一个文件从0开始,最大值只有1024,但是一个文件字节值只有10,那么就只读取到10就把该文件给读取完了,如果该文件字节值比1024还要大,分两种情况:1、读到1024就停止对该文件的读取2如果想要继续读,就要定义b的大小。根据文件的最大值来定,可以是2048
4.运行效果:
nove文件夹为空:
运行之后结果:
4.1、对应资源网站:(图片我就不放了)
4.2、运行过程中的控制台:
运行结果之后:novel文件夹就下好了图片。



案例四:爬取音乐,和爬取图片是一样的原理。
1、二进制文件资源抓取的思路:
1、按照文字抓取的方式,获取资源的具体地址 2、根据具体地址,通过IO流下载到本地 2.1将具体地址的资源转换成输入流 2.2将对应资源写到本地,需要构建输出流2、代码:
package com.zking.selenium; import java.io.BufferedOutputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.net.URL; import java.util.List; import java.util.UUID; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; import org.openqa.selenium.WebElement; import org.openqa.selenium.chrome.ChromeDriver; public class demo4 { public static void main(String[] args) throws Exception { System.setProperty("webdriver.chrome.driver", "D:\\inits\\chromedriver.exe"); WebDriver driver = new ChromeDriver(); driver.get("https://houzi8.com/peiyue/qingyinyue-0-0-0-0-0?usid=22876&bd_vid=10917515020733932303"); /* * 二进制文件资源抓取 1.按照文字爬取的方式,获取到资源的具体地址 ①、将具体地址的资源转换成输入流 ②、将对应资源写到本地,需要构建输出流 * selenium jsoup */ ListaudioEles = driver.findElements(By.className("play-button-wrapper"));//获取整个音乐---->数组 for (WebElement audioEle : audioEles) { audioEle.click(); WebElement playEle = driver.findElement(By.xpath("//*[@id=\\\"wavesurferPlayer\\\"]/audio"));//找到对应的Xpath System.out.println(playEle.getAttribute("src"));//获取资源路径 downloadImg(playEle.getAttribute("src")); } } private static void downloadImg(String src) throws Exception { // 通过统一资源定位符,获取资源对象 URL url = new URL(src); // 将资源对象转换成输入流 InputStream in = url.openStream(); src = src.substring(src.lastIndexOf(".")); FileOutputStream fout = new FileOutputStream("D:/novel1/" + UUID.randomUUID().toString() + src);//下载到本地路径 BufferedOutputStream bout = new BufferedOutputStream(fout); byte[] b = new byte[1024]; while (true) { int len = in.read(b); if (len == -1) break; bout.write(b, 0, len); } } }