mysql8索引与顺序无关_如何理解MYSQL索引最左匹配原则?
今天来讲讲MySQL索引的相关问题,谈到索引,其实算是有个非常有深度的问题,本人才疏学浅,能力有限,理解不当之处,请各位大佬批评指正!不胜感激;
言归正转,回到今天要说的MYSQL索引最左匹配原则问题;
测试表结构,有三个字段,分别是id,name,cid
CREATE TABLE `stu` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name_cid` (`name`,`cid`)
);
索引方面:id是主键,(name,cid)是一个多列复合索引。
下面是有疑问的两个查询:
explain select * from stu where cid=1001;

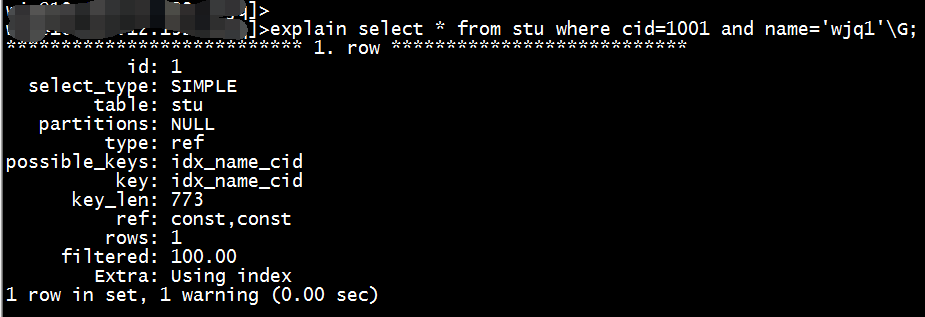
explain select * from stu where cid=1001 and name='wjq1';
疑问是:sql查询用到索引的条件是必须要遵守最左前缀原则,为什么上面两个查询还能用到索引?
讲上面问题之前,我先补充一些知识,因为我觉得你对索引理解是狭隘的,因为最开始的时候我就存在这样疑惑:
上述你的两个查询的explain结果中显示用到索引的情况类型是不一样的。,可观察explain结果中的type字段。
查询中分别是:
1. type: index
2. type: ref
解释:
index:这种类型表示是mysql会对整个该索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者某个复合索引的一部分,mysql都可能会采用index类型的方式扫描。但是呢,缺点是效率不高,mysql会从索引中的第一个数据一个个的查找到最后一个数据,直到找到符合判断条件的某个索引。
如下是官方文档解释:
The index join type is the same as ALL, except that the index tree is scanned. This occurs two ways:
If the index is a covering index for the queries and can be used to satisfy all data required from the table, only the index tree is scanned. In this case, the Extra column says Using index. An index-only scan usually is faster than ALL because the size of the index usually is smaller than the table data.
A full table scan is performed using reads from the index to look up data rows in index order. Uses index does not appear in the Extra column.
链接:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#jointype_index
所以:对于你的第一条语句:
explain select * from stu where cid=1001;
判断条件是cid=1001,而cid是(name,cid)复合索引的一部分,没有问题,可以进行index类型的索引扫描方式。explain显示结果使用到了索引,是index类型的方式。
ref:这种类型表示mysql会根据特定的算法快速查找到某个符合条件的索引,而不是会对索引中每一个数据都进行一一的扫描判断,也就是所谓你平常理解的使用索引查询会更快的取出数据。而要想实现这种查找,索引却是有要求的,要实现这种能快速查找的算法,索引就要满足特定的数据结构。简单说,也就是索引字段的数据必须是有序的,才能实现这种类型的查找,才能利用到索引。
如下是官方文档解释:
All rows with matching index values are read from this table for each combination of rows from the previous tables. ref is used if the join uses only a leftmost prefix of the key or if the key is not a PRIMARY KEY or UNIQUE index (in other words, if the join cannot select a single row based on the key value). If the key that is used matches only a few rows, this is a good join type.
链接:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#jointype_ref
有些了解的人可能会问,索引不都是一个有序排列的数据结构么。是这样没错,不过答案说的还不够完善,那只是针对单个索引,而复合索引的情况可能就不太了解了。
下面就说下复合索引:
以该表的(name,cid)复合索引为例,它内部结构简单说就是下面这样排列的:
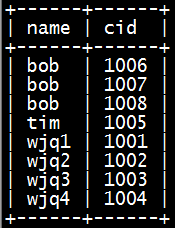
mysql创建复合索引的规则是首先会对复合索引的最左边的,也就是第一个name字段的数据进行排序,在第一个字段的排序基础上,然后再对后面第二个的cid字段进行排序。其实就相当于实现了类似 order by name cid这样一种排序规则。
所以:第一个name字段是绝对有序的,而第二字段就是无序的了。所以通常情况下,直接使用第二个cid字段进行条件判断是用不到索引的,当然,可能会出现上面的使用index类型的索引。这就是所谓的mysql为什么要强调最左前缀原则的原因。
那么什么时候才能用到呢?
当然是cid字段的索引数据也是有序的情况下才能使用咯,什么时候才是有序的呢?观察可知,当然是在name字段是等值匹配的情况下,cid才是有序的。发现没有,观察两个name名字为bob的cid字段是不是有序的呢。从上往下分别是1006,1007,1008 。
这也就是mysql索引规则中要求复合索引要想使用第二个索引,必须先使用第一个索引的原因。(而且第一个索引必须是等值匹配)。
所以对于你的这条sql查询:
explain select * from stu where cid=1001 and name=’wjq1′;
没有错,而且复合索引中的两个索引字段都能很好的利用到了!因为语句中最左面的name字段进行了等值匹配,所以cid是有序的,也可以利用到索引了。
你可能会问:我建的索引是(name,cid)。而我查询的语句是cid=1001 AND name=’wjq1′; 我是先查询cid,再查询name的,不是先从最左面查的呀?
好吧,我再解释一下这个问题:首先可以肯定的是把条件判断反过来变成这样 name=’wjq1′ and cid=1001; 最后所查询的结果是一样的。
那么问题产生了?既然结果是一样的,到底以何种顺序的查询方式最好呢?
说明:where中and条件的先后顺序对如何选择索引是无关的。因为优化器会去分析判断选用哪个索引。
所以,而此时那就是我们的mysql查询优化器该登场了,mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。所以,当然是我们能尽量的利用到索引时的查询顺序效率最高咯,所以mysql查询优化器会最终以这种顺序进行查询执行。
这里需要注意的是:mysql的执行计划和查询的实际执行过程并不完全吻合。如何证明这一点呢?
真正的执行过程可以通过mysql的trace工具来分析一下:
针对上述的两个查询,我们来看一下具体的执行过程:
explain select * from stu where cid=1001;
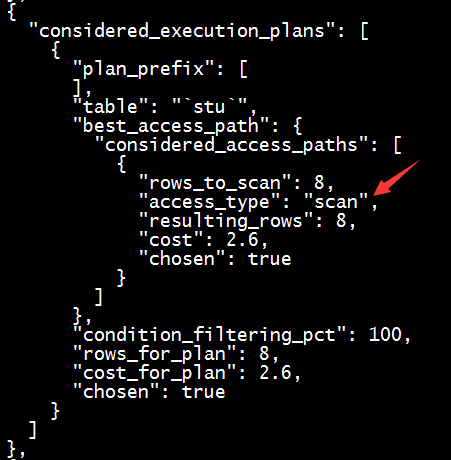
可以看到并没有使用索引,而是进行了全表扫描。
下面再来看一下另一个SQL的的trace结果;
explain select * from stu where cid=1001 and name=’wjq1′;
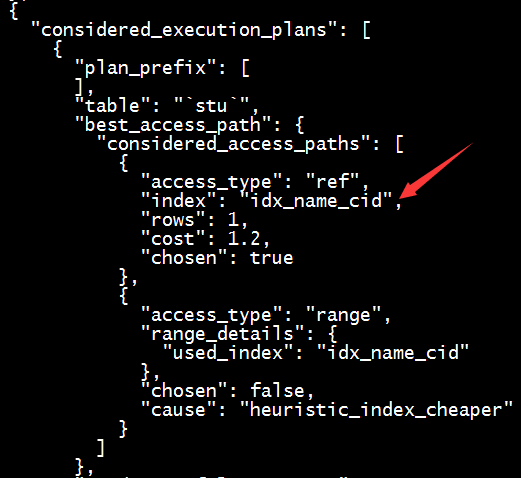
可以看出最终使用的索引是idx_name_cid。

如果您觉得本站对你有帮助,那么可以收藏和推荐本站,帮助本站更好地发展,在此谢过各位网友的支持。
转载请注明原文链接:如何理解MYSQL索引最左匹配原则?