Elasticsearch 原理解析(介绍)
介绍
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
实时分析的分布式搜索引擎。
可以扩展到上百台服务器,处理 PB 级别的结构化或非结构化数据。
基本概念
对应关系

一个文档的数据,通常是 json 格式
{"name" : "John","sex" : "Male","age" : 25,"birthDate": "1990/05/01","about" : "Hello world","interests": [ "sports", "game" ]}
复制代码
名词解析
-
集群(cluster):由一个或多个节点组成, 并通过集群名称与其他集群进行区分
-
节点(node):单个 ElasticSearch 实例
-
索引(index):在 ES 中, 索引是一组文档的集合
-
分片(shard):因为 ES 是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES 自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节,一个分片默认最大文档数量是 20 亿.
-
副本(replica):ES 默认为一个索引创建 5 个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由 5 个主分片成本, 而每个主分片都相应的有一个 copy.
分片及副本的分配是高可用及快速搜索响应的设计核心。主分片与副本都能处理查询请求, 它们的唯一区别在于只有主分片才能处理索引请求。
架构
集群

节点架构图:

分片
每一个 shard 就是一个 Lucene Index,包含多个 segment 文件,和一个 commit point 文件。
在 es 配置好索引后,集群运行中是无法调整分片配置的。如果要调整分片数量,只能新建索引对数据进重新索引(reindex),该操作很耗时,但是不用停机。
分片时主要考虑数据集的增长趋势,不要做过度分片。
每个分片都有额外成本:
-
每个分片本质上就是一个 Lucene 索引, 因此会消耗相应的文件句柄, 内存和 CPU 资源
-
每个搜索请求会调度到索引的每个分片中. 如果分片分散在不同的节点倒是问题不太. 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降
-
每个搜索请求会遍历这个索引下的所有分片
-
ES 使用词频统计来计算相关性. 当然这些统计也会分配到各个分片上. 如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差
es 推荐的最大 JVM 堆空间时 30~32G,所以如果分片最大容量限制为 30G,假如数据量达到 200GB,那么最多分配 7 个分片就足够了。过早的优化是万恶之源,过早的分片也是。
流程
写入数据
-
客户端选择一个 node 发送请求过去,这个 node 就是 coordinating node (协调节点)
-
coordinating node,对 document 进行路由,将请求转发给对应的 node
-
实际上的 node 上的 primary shard 处理请求,然后将数据同步到 replica node
-
coordinating node,如果发现 primary node 和所有的 replica node 都搞定之后,就会返回请求到客户端
其中步骤 3 中 primary 直接落盘 IO 效率低,所以参考操作系统的异步落盘机制:
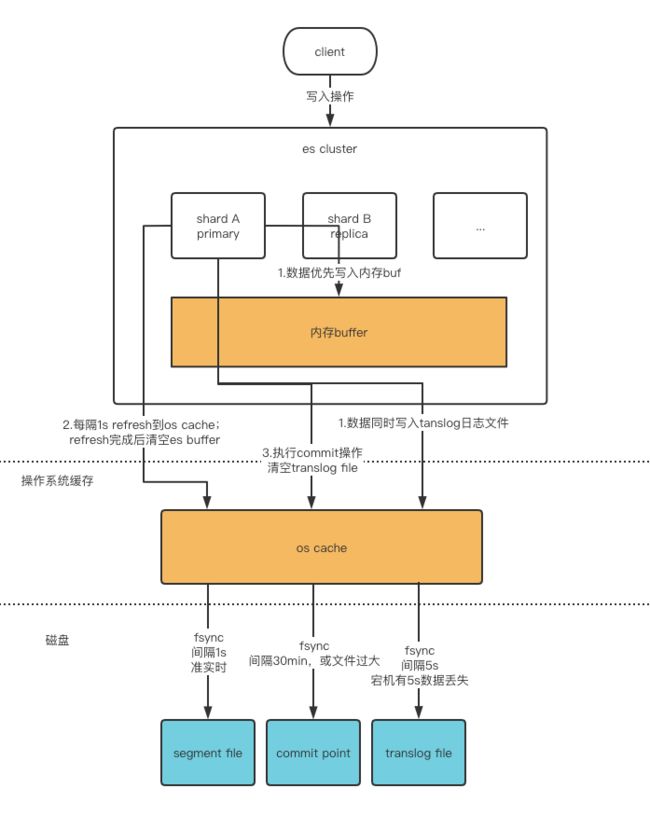
-
ES 使用了一个内存缓冲区 Buffer,先把要写入的数据放进 buffer;同时将数据写入 translog 日志文件(其实是些 os cache)。
-
refresh:buffer 数据满/1s 定时器到期会将 buffer 写入操作系统 segment file 中,进入 cache 立马就能搜索到,所以说 es 是近实时(NRT,near real-time)的
-
flush:tanslog 超过指定大小/30min 定时器到期会触发 commit 操作将对应的 cache 刷到磁盘 file,commit point 写入磁盘,commit point 里面包含对应的所有的 segment file
-
translog 默认 5s 把 cache fsync 到磁盘,所以 es 宕机会有最大 5s 窗口的丢失数据
读取数据
-
客户端发送任何一个请求到任意一个 node,成为 coordinate node
-
coordinate node 对 document 进行路由,将请求 rr 轮训转发到对应的 node,在 primary shard 以及所有的 replica 中随机选择一个,让读请求负载均衡,
-
接受请求的 node,返回 document 给 coordinate note
-
coordinate node 返回给客户端
搜索过程
-
客户端发送一个请求给 coordinate node
-
协调节点将搜索的请求转发给所有的 shard 对应的 primary shard 或 replica shard
-
query phase:每一个 shard 将自己搜索的结果(其实也就是一些唯一标识),返回给协调节点,有协调节点进行数据的合并,排序,分页等操作,产出最后的结果
-
fetch phase ,接着由协调节点,根据唯一标识去各个节点进行拉去数据,最总返回给客户端
索引
一切设计都是为了提高搜索的性能
为了提高搜索的性能,难免会牺牲某些其他方面,比如插入/更新,否则其他数据库不用混了。前面看到往 Elasticsearch 里插入一条记录,其实就是直接 PUT 一个 json 的对象,这个对象有多个 fields,比如上面例子中的 name, sex, age, about, interests,那么在插入这些数据到 Elasticsearch 的同时,Elasticsearch 还默默的为这些字段建立索引--倒排索引,因为 Elasticsearch 最核心功能是搜索。
倒排索引

假如数据如下
那么建立的索引如下
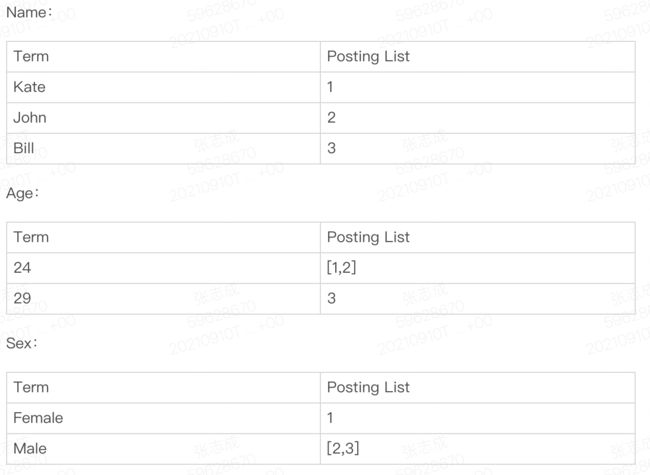
Posting List
es 分别为每个 field 都建立了一个倒排索引,Kate, John, 24, Female 这些叫 term,而[1,2]就是 Posting List。Posting list 就是一个 int 的数组,存储了所有符合某个 term 的文档 id。
数据有两种情况,一种是 term 特别多,一种是 posting list 特别多。es 对此分别进行优化,优化方式是添加索引(提升时间效率),压缩(提升空间效率)
Term dictionary
Elasticsearch 为了能快速找到某个 term,将所有的 term 排个序,二分法查找 term,logN 的查找效率,就像通过字典查找一样。
Term Index
B-Tree 通过减少磁盘寻道次数来提高查询性能,Elasticsearch 也是采用同样的思路,直接通过内存查找 term,不读磁盘,但是如果 term 太多,term dictionary 也会很大,放内存不现实,于是有了 Term Index,就像字典里的索引页一样,A 开头的有哪些 term,分别在哪页,可以理解 term index 是一颗树:
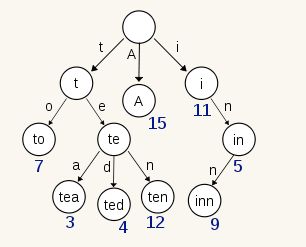
这棵树不会包含所有的 term,它包含的是 term 的一些前缀。通过 term index 可以快速地定位到 term dictionary 的某个 offset,然后从这个位置再往后顺序查找。
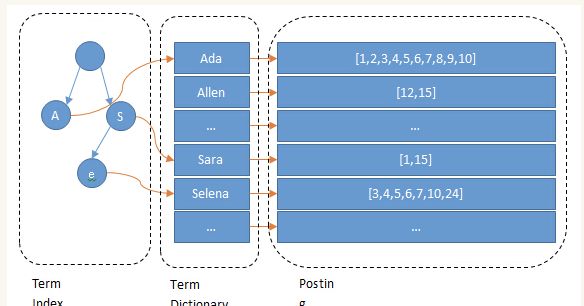
Term Index 不需要存所有 term,只是一个前缀数,再结合 FST 压缩技术,存放到内存中。通过 TermIndex 定位到 TermDictionary 在磁盘上的 block 后,在顺序查找磁盘,降低随机读磁盘的次数
压缩技巧
Posting List 压缩
比如以性别作为倒排索引,es 数据有成千上万条,那么 Posting List 数据量也会特别大。需要进行压缩存储
5。0 版本之前 Lucene 直接使用 bitMap 的形式进行压缩。假设某个 posting list:
[1,3,4,7,10]
对应的 bitMap 是:
[1,0,1,1,0,0,1,0,0,1]
单这样压缩方式仍然不够高效,如果有 1 亿个文档,那么需要 12.5MB 的存储空间,这仅仅是对应一个索引字段(我们往往会有很多个索引字段)。于是有人想出了 Roaring bitmaps 这样更高效的数据结构。
Roaring bitmap(RBM)
Bitmap 的缺点是存储空间随着文档个数线性增长,RBM 需要打破这个魔咒就一定要用到某些指数特性:
将 posting list 按照 65535 为界限分块,比如第一块所包含的文档 id 范围在 0~65535 之间,第二块的 id 范围是 65536~131071,以此类推。再用<商,余数>的组合表示每一组 id,这样每组里的 id 范围都在 0~65535 内了
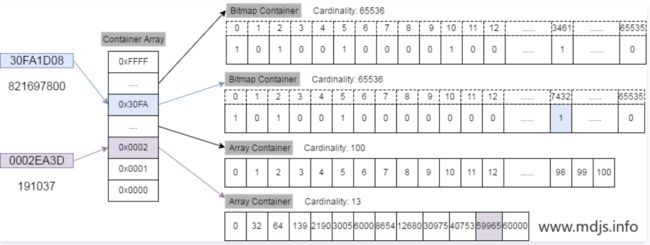
举个栗子说明就好了。现在我们要将 821697800 这个 32 bit 的整数插入 RBM 中,整个算法流程是这样的:
-
821697800 对应的 16 进制数为 30FA1D08, 其中高 16 位为 30FA, 低 16 位为 1D08。
-
我们先用二分查找从一级索引中找到数值为 30FA 的容器(如果该容器不存在,则新建一个),从图中我们可以看到,该容器是一个 Bitmap 容器。
-
找到了相应的容器后,看一下低 16 位的数值 1D08,它相当于是 7432,因此在 Bitmap 中找到相应的位置,将其置为 1 即可。
联合索引
-
利用跳表(Skip list)的数据结构快速做“与”运算,或者对最短的 posting list 中的每个 id,逐个在另外两个 posting list 中查找看是否存在,最后得到交集的结果。
-
利用上面提到的 bitset 按位“与”直接按位与,得到的结果就是最后的交集。
总结
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用及其苛刻的态度使用内存。
注意事项
-
不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
-
同样的道理,对于 String 类型的字段,不需要 analysis 的也需要明确定义出来,因为默认也是会 analysis 的
-
选择有规律的 ID 很重要,随机性太大的 ID(比如 java 的 UUID)不利于查询
-
上面看到的压缩算法,都是对 Posting list 里的大量 ID 进行压缩的,那如果 ID 是顺序的,或者是有公共前缀等具有一定规律性的 ID,压缩比会比较高;
注意事项 2
-
拒绝大聚合
-
拒绝模糊查询
-
拒绝深度分野 ES 获取数据时,每次默认最多获取 10000 条,获取更多需要分页,但存在深度分页问题,一定不要使用 from/Size 方式,建议使用 scroll 或者 searchAfter 方式。scroll 会把上一次查询结果缓存一定时间(通过配置 scroll=1m 实现),所以在使用 scroll 时一定要保证 search 结果集不要太大。
-
拒绝多层嵌套,不要超过 2 层,避免内存泄漏
-
拒绝 top》100 的潮汛 top 查询是在聚合的基础上再进行排序,如果 top 太大,cpu 的计算量和耗费的内存都会导致查询瓶颈
实战
es 常见用法
有些小伙伴不知道本文内容和更多相关学习资料的请点赞收藏+评论转发+关注我,后面会有很多干货。我有一些面试题、架构、设计类资料可以说是程序员面试必备!所有资料都整理到网盘了,需要的话欢迎下载!私信我回复【000】即可免费获取
