redis缓存集群及集群负载均衡方案设计
一、缓存模块设计
采用分布式缓存:

说明:
(1)Web服务器端只负责调用接口获取/更新数据,不必关心业务数据处理;
(2)接口负责具体的数据处理,包括缓存数据的写入/更新;
(3) 缓存集群用于缓存服务器宕机后,数据仍然高可用。
二、缓存写入规则
用户访问业务数据时,查询缓存,如果没有值,则从数据库载入redis,并设置过期时间(基于时间过期的更新策略)。
• 针对每一个模块,仅有一块内容的情况:存储k/v一条记录;
• 针对每一个模块,有多块不同内容的情况:每块内容存储一条k/v记录,同时,"模块key"存储模块下面所有内容的“内容key”值。其中,"内容key"按照一定规则生成,尽管模块对应的内容有多块,但是内容key规则只有一条。
以热门班次模块为例来说明模块有多块不同内容的情况:热门班次对应的key是rmbc,对应的内容key规则是rmbc_city_cityId。热门班次下面有很多不同的城市,每一个城市属于热门班次不同的内容,广州、上海对应cityId分别是10、11。在缓存广州热门班次的时候,会缓存一条rmbc_city_10/...的数据,同时会缓存一条rmbc/rmbc_city_10的数据,在缓存上海热门班次的时候,会缓存一条rmbc_city_11/...的数据,同时,修改rmbc/rmbc_city_10为rmbc/rmbc_city_10,rmbc_city_11。在进行手动实时更新时,首先查询rmbc的key,知道有rmbc_city_10,rmbc_city_11对应的数据进行了缓存,然后可以具体操作哪条数据进行立即更新。
三、缓存更新规则
时间过期+规则过期:
上面基于时间过期的更新策略,在过期时间内,将一直从缓存读取数据;在过期之后,则需要重新从数据库加载数据到缓存。这种策略的问题是大并发访问时,容易造成数据库瞬间高并发读。解决的办法是添加“基于规则过期”的更新策略。
添加规则过期的策略之后,当从缓存拿到数据后,首先检查该数据离设定的过期时间是否小于一定的值,如果小于一定值,则读取数据库更新缓存,进行提前更新,从一定程度上避免了大并发访问时,数据库瞬间高并发读;当从缓存读取不到数据时,从数据库读取,并更新缓存。
以上更新策略,在缓存数据过期后才读取的时候,仍有可能造成数据库瞬间高并发读。
五、后台功能设计
5.1、后台功能设计目的
能够对模块对应的缓存数据进行手动选择性实时更新,实时更新包括:立即实时更新和延迟实时更新。
• 立即实时更新是指:对模块对应的缓存数据进行删除操作,当下一次请求到来时,将从数据库读取数据更新缓存,达到实时更新的目的。
• 延迟实时更新是指:对模块对应的缓存数据重新设置随机不同的、间隔较短的过期时间,当下一次请求到来时,将不一定从数据库读取数据更新缓存,在缓急服务器、数据库压力的前提下,达到实时更新的目的。
5.2、后台功能数据表
(1)后台添加key规则表:ecm_keyrole
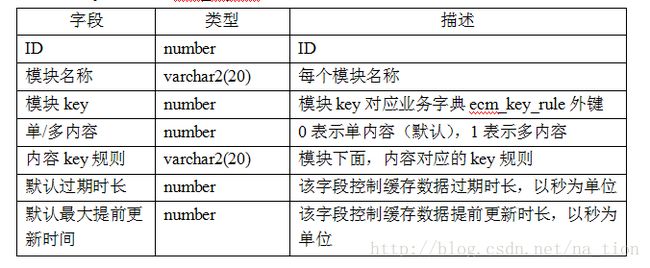
(2)key规则数据表各字段设计目的
•模块名称:每一个模块的名称;
•模块key:模块在k/v缓存对应的key值;value值是模块对应的不同的内容key值;
•单/多内容:表示模块对应的缓存内容有多部分还是一部分
•内容key规则:模块内容对应的key规则。每个模块有不同内容,但是内容key规则只有一个;
•默认过期时长:模块缓存数据默认的过期时间;
•默认最大提前更新时间:控制缓存数据允许提前更新的最大时长。
(3)key数据表读取与管理
•读取:数据表由于被频繁使用,所以可以放在缓存或者服务全局变量中;当从缓存或全局变量中不到时,从数据库读取,更新缓存或全局变量。这里解决集群中循环写服务器的问题,key规则表放在缓存中。
•CRUD:数据表在被修改时,在更新数据库后,通过调用提供的接口更新缓存
(4)频道表:ecm_channel

(5)频道模块表:ecm_channel_keyrole
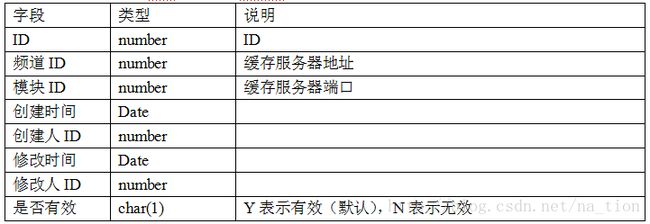
(6)缓存集群表读取与管理
•读取:数据表由于被频繁使用,所以可以放在缓存或者全局变量中;当从缓存或全局变量中不到时,从数据库读取,更新缓存或全局变量。这里为减少读取缓存次数,提高服务速度,以及方便主机切换,和key规则表一样放在全局变量中。
•CRUD:缓存集群表在被修改后,在更新数据库后,通过服务重启加载全局变量
5.3、后台需要实现的功能
(1)对key规则表进行管理;其中,模块key字段、模块对应的内容key规则字段为业务字典中值。对key规则表进行增加/修改之后,在更新数据库之后,需要调用提供的接口更新系统全局变量;对key规则表进行删除操作时,一方面,需要调用提供的接口更新系统全局变量,另一方面,需要调用提供的接口进行缓存中缓存数据的删除。
(2)根据key规则表对缓存内容进行实时更新:
(a)能够根据频道ID查询出属于该频道的有哪些模块数据进行了缓存,频道与模块的关系由key规则数据表存储;其中,频道与模块是多-多的关系;
(b)通过调用提供的接口,能够对模块中缓存的所有数据进行实时更新;
(c)如果某一模块有多部分内容,如热门班次有很多城市,不同城市属于不同内容。后台还需要能够根据缓存中“模块key”存储的"内容key"值,进行某一块内容缓存数据的更新。其中,"内容key"在缓存时由前台功能存入“模块key”中。更新多内容中某一块内容时,可以输入key值进行更新,也可以全部列出模块中有哪些不同内容,选择更新。
(3)实时更新应该包括:立即实时更新和延迟实时更新。
(4)设置所有模块的总的默认过期时间。
(5)设置所有模块的总的默认的允许提前更新时长。
(6)对缓存集群表进行管理:
对缓存集群表进行修改之后,在更新数据库之后,通过服务重启加载全局变量。
(7)日志记录开关功能:通过调用接口,进行日志记录开关设置,当开关打开时,接口可以记录都调用了那些接口。
(8)后台缓存手动实时更新实现的效果图:
(a)对于有些模块,会出现在不同的页面,为实现手动更新一次达到该模块不同页面的数据都更新,需要建立频道与模块关系表。如果不同页面现实的条数不同,则在缓存中缓存最多的纪录。
(b)模块有单内容或者多内容,由key规则表的“单/多内容”字段进行控制。
六、缓存集群
6.1、主从复制;
6.2、宕机处理:
两种高可用性集群方案:
(a)主-主(Active-Active)工作方式:(HAProxy)
最常用的集群模型,它提供了高可用性,并且在只有一个节点时也能提供可以接受的性能,该模型允许最大程度的利用硬件资源。每个节点都通过网络对客户机提供资源,每个节点的容量被定义好,使得性能达到最优,并且每个节点都可以在故障转移时临时接管另一个节点的工作。所有的服务在故障转移后仍保持可用,但是性能通常都会下降。
这种模式的最大优点是不会有服务器的“闲置”,两台服务器在正常情况下都在工作。但如果有故障发生导致切换,应用将放在同一台服务器上运行,由于服务器的处理能力有可能不能同时满足数据库和应用程序的峰值要求,这将会出现处理能力不够的情况,降低业务响应水平。
(b)主-从(Active-Standby)工作方式(Keepalived)
是HA中最简单的一种,为了提供最大的可用性,以及对性能最小的影响,主-从工作方式需要一个在正常工作时处于备用状态的节点,主节点处理客户机的请求,而备用节点处于空闲状态,当主节点出现故障时,备用节点会接管主节点的工作,继续为客户机提供服务,并且不会有任何性能上影响。
(c)如果是做Failover而非负载均衡的话,Keepalived的效率肯定是超过HAProxy的
七、奖池规则实现的缓存集群方案
7.1、负载均衡需求设计
(a)对集群中redis节点进行负载均衡,能够随机访问集群中的任意正常节点;
(b)节点发生故障时,能够自动撤销节点;
(c)节点恢复后,能够自动添加节点;
(d)能够记录集群中每个节点的运行参数、访问量;
(e)缓存数据持久化。
7.2、集群概要设计
7.2.1、缓存集群分组
(1)不同的服务可以用不同的缓存集群,也可以使用相同的缓存集群;应用服务器根据需要,筛选出所需的redis节点;
(2)缓存节点变化,或者节点的访问权重发生变化,各应用服务器需要重启;
(3)同一集群中权重之和等于100。
7.2.2、二维表
(1)二维表格式

(2)二维表维护
(a)系统在启动时根据节点权重计算出随机数区间,随机数区间在1~100;
(b)在访问缓存节点之前,产生随机数r,(1<=r<=100);
(c)随机数r在哪个节点的随机数区间,则首先访问该缓存节点,此处假设首先访问17节点;
(d)访问17节点,如果17故障,将17节点的有效标记设置为N,随机数区间置零,进行(e)步骤,否则进行(f)步骤;
(e)根据正常节点权重,重新生成各自的随机数区间,区间范围仍为1~100,之后进行(c)步骤;
(f)从17节点取到缓存数据,则直接返回,否则从下一个缓存节点获取。从下一个节点获取数据的循环次数不超过预设的某一值;
(g)定时器每段时间主动检测每个节点的健康状况,进行故障节点的撤销、故障恢复之后节点的恢复。
7.3、定时器
定时器每段时间运行一次,运行时:
(1)记录日志,日志内容包括:集群中每个节点当前的有效标记、访问区间、累计访问次数;
(2)当某一节点累计访问次数达到预设最大值时,所有节点访问次数都设为预设最小值;
(3)对二维表进行主动维护。
7.4、缓存数据持久化
配置redis缓存数据持久化参数
八、缓存系统流程图

九、缓存系统评价
缓存系统评价从下面三个方面进行综合考虑:
(1)速度;
(2)及时性;
(3)命中率。