pandas中drop用法_如何使用drop方法对数据进行删减处理

在我们进行数据分析时,某些情况下我们会需要对数据作出一系列的删减处理。今天就为大家推荐一下在Python中常用于数据删减的drop方法。
在Pandas 中,以 .drop 开头的方法都与数据的删减有关。
下面我们先简单说一下drop的用法及一些主要参数:
drop函数:drop(labels, axis=0, level=None, inplace=False, errors='raise')
关于参数axis:
axis为0时表示删除行,axis为1时表示删除列,还是一样~
关于参数errors:
errors='raise'会让程序在labels接收到没有的行名或者列名时抛出错误导致程序停止运行,errors='ignore'会忽略没有的行名或者列名,只对存在的行名或者列名进行操作,没有指定的话也是默认‘errors='raise'’。
其他主要参数:

介绍完函数体,下面我们还是一样从例子出发:
(大家记得每次打代码之间记得看下有没有导入库,我偶尔会忘了粘上库的代码)
import pandas as pd
import numpy as np
cities = pd.DataFrame(np.random.randn(5, 5),
index=['a', 'b', 'c', 'd', 'e'],
columns=['shenzhen', 'guangzhou', 'beijing', 'nanjing', 'haerbin'])
cities
还是之前的那个城市的数据表。
(1)删除掉第a行:
df1=cities.drop(labels='a')
df1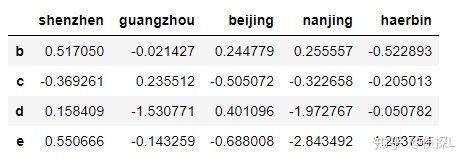
df2=cities.drop(index='a')
df2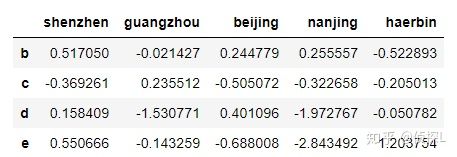
可以看到,因为这里我们是删除行,所以我们用labels、index都是可以的。不过还是推荐使用labels。而已还是要注意~drop默认对原表不生效,如果要对原表生效,需要添加参数:inplace=True
(2)删除非连续的多行:
和上面一样,我们可以通过labels来控制删除行或列的个数,如果是删多行/多列,需写成labels=[1,3],不能写成labels=[1:2],在这里用“:”号的话会报错。
举个例子:
df1=cities.drop(labels=['a','c','e'])
df1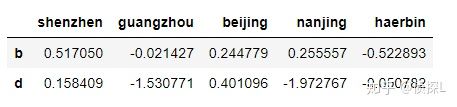
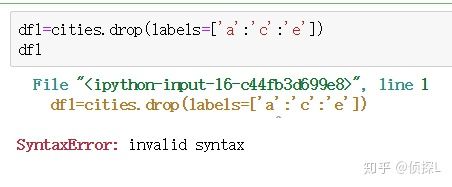
这里我们要插播一下比较细节的东西,大家以后可能会遇到的一个问题:
为了方便看,我们这次不设置索引名,下面重新创建一下数据表:
city = pd.DataFrame(np.random.randn(5, 5),
columns=['shenzhen', 'guangzhou', 'beijing', 'nanjing', 'haerbin'])
city
我们还是删掉第1行(1实际上是第二行),而已这一次我们加上inplace=True:
city.drop(labels=1,axis=0,inplace=True)然后我们看一下原来的数据表city:

可以看到,第1行确实被删掉了,看上去好像没什么问题。
如果这个时候,我们再输入一次:
city.drop(labels=1,axis=0,inplace=True)(报错了,很应该啊,好像也没什么,毕竟第1行本来就被我们删掉了)
但是!!!注意了,我们在这里想说明的是:
如果我们没标注索引,而已把数据一行一行删掉的话,该行对应的索引也是被我们删掉的!
比如说一个数据表里一共有5行,我们把第2、第3行给删掉了,就会顺道对应把索引2、索引3删掉,这时候数据的索引就会变成[1、4、5],即使这个时候原来的第4行数据现在变成第2行了,现在也无法用索引第2行的方式来获取现在的第2行(原来的第4行),因为索引已经乱了。
所以说,大家在用drop的时候还是要注意这一点的。同时,我们该如何解决这个问题呢?
答案是要将索引重置,这样后面再次使用才不会因为索引不存在而报错。
重置索引的方法是:reset_index
reset_index,默认(drop = False),当我们指定(drop = True)时,则不会保留原来的index,会直接使用重置后的索引。
我们来实验一下:
----------------------------------------------------------------------------------------------
这是原来删掉第1行后的数据表:

很明显索引没重置,所以在我们再次删除时,出现了下面这种情况:

下面我们使用reset_index进行索引重置:

可以看到,此时数据表增加了一列新的索引,同时原来的索引被被保留了下来。
如果我们想直接使用重置后的索引,不保留原来的index,就可以加上(drop = True),如下所示:
city.reset_index(drop=True)也就是说这个时候,原来被我们删除的那行数据已经没了,但是索引没有变乱。
这个时候我们再试试删除第1行,果然没有问题了。
-----------------------------------------------------------------------------------------------
补充完上面的解释,我们接下去介绍drop的其他用法。
(3)删除连续的多行:
当我们想删除连续多行时,如果还是一个一个标签输入的话,显得不太智能,所以我们可以用更简便的方法:
再建一个新的数据表:
people= pd.DataFrame(np.random.randn(6, 6),
columns=['jack', 'rose', 'mike', 'chenqi', 'amy','tom'])
people
当我们想删去第2-4行时,可以用如下表示:
df2=people.drop(labels=range(2,5),axis=0)
df2
注意了,不能用这种方法尝试删除列,会报错。
(4)删除列:
在最新的表中删除‘jack’这一列:
df2=people.drop(labels='jack',axis=1)
df2
同时删除‘rose’、‘mike’这两列:
df2=people.drop(labels=['rose','mike'],axis=1)
df2
以上便是<如何使用drop方法对数据进行删减处理>的内容,感谢大家的细心阅读,同时欢迎感兴趣的小伙伴一起讨论、学习,想要了解更多内容的可以看我的其他文章,同时可以持续关注我的动态~