mysql 单表使用索引及常见的索引失效的情况总结
单表使用索引及常见的索引失效的情况
目录
单表使用索引及常见的索引失效的情况
1. 全值匹配我最爱
1.1 有以下SQL语句
1.2 建立索引
2. 最佳左前缀法则
3. 不要在索引列上做任何操作
3.1 在查询列上使用了函数
3.2 在查询列上做了转换
4. 索引列上有范围查询时,范围条件右边的列将失效
5. 使用不等于(!= 或者<>)的时候索引失效
6. is not null 不能使用索引,is null可以使用索引
7. like以通配符%或_开头索引失效
8. 字符串不加单引号索引失效
9. 减少使用or
10. 尽量使用覆盖索引
1. 全值匹配我最爱
1.1 有以下SQL语句
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid=4
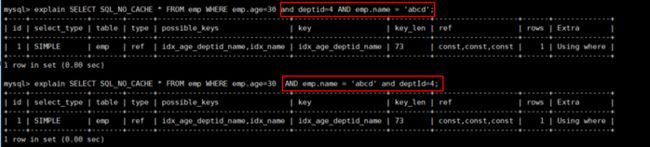
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid=4 AND emp.name = 'abcd'
1.2 建立索引
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME);
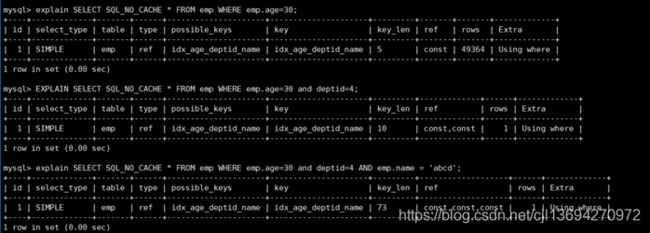
结论:全值匹配我最爱指的是,查询的字段按照顺序在索引中都可以匹配到!
SQL中查询字段的顺序,跟使用索引中字段的顺序,没有关系。优化器会在不影响SQL执行结果的前提下,给你自动地优化。
2. 最佳左前缀法则

查询字段与索引字段顺序的不同会导致,索引无法充分使用,甚至索引失效!
原因:使用复合索引,需要遵循最佳左前缀法则,即如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
结论:过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。
3. 不要在索引列上做任何操作
不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描。
3.1 在查询列上使用了函数
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE age=30;
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE LEFT(age,3)=30;
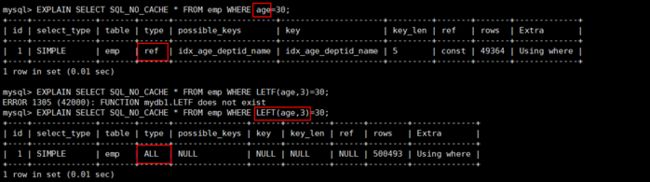
结论:等号左边无计算!
3.2 在查询列上做了转换
| create index idx_name on emp(name); |
| explain select sql_no_cache * from emp where name='30000'; |
| explain select sql_no_cache * from emp where name=30000; |
字符串不加单引号,则会在name列上做一次转换!

结论:等号右边无转换!
4. 索引列上有范围查询时,范围条件右边的列将失效
| explain SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid=5 AND emp.name = 'abcd'; |
| explain SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid<5 AND emp.name = 'abcd'; |
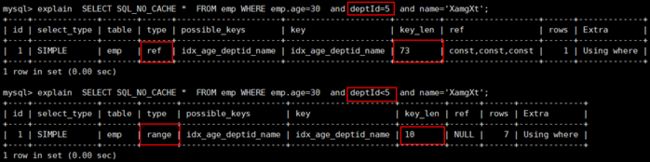
建议:将可能做范围查询的字段的索引顺序放在最后
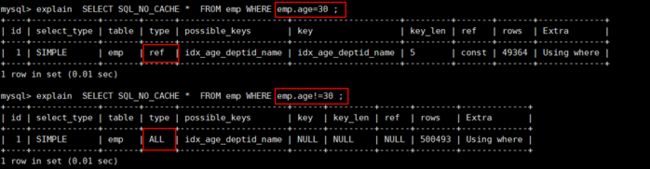
5. 使用不等于(!= 或者<>)的时候索引失效
mysql 在使用不等于(!= 或者<>)时,有时会无法使用索引会导致全表扫描。
6. is not null 不能使用索引,is null可以使用索引
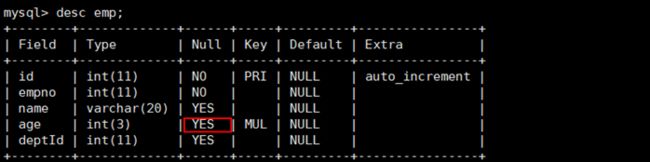
当字段允许为Null的条件下:
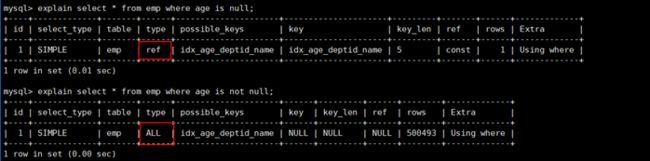
is not null用不到索引,is null可以用到索引。
7. like以通配符%或_开头索引失效
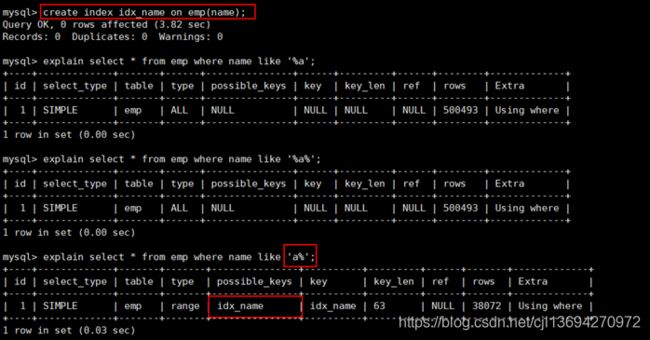
前缀不能出现模糊匹配!
8. 字符串不加单引号索引失效
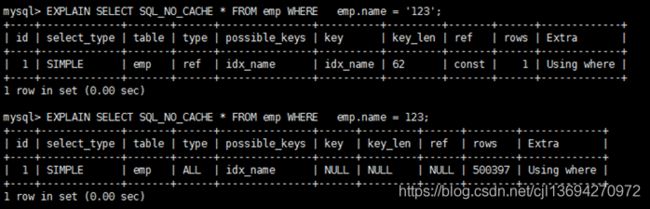
9. 减少使用or

使用union all或者union来替代:

10. 尽量使用覆盖索引
即查询列和索引列一致,不要写select *!
| explain SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptId=4 and name='XamgXt'; |
| explain SELECT SQL_NO_CACHE age,deptId,name FROM emp WHERE emp.age=30 and deptId=4 and name='XamgXt'; |

覆盖索引是select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖