Alluxio架构、场景与部分配置参数详解
Alluxio架构、场景与部分配置参数
Alluxio:架构及数据流 - 简书 (jianshu.com)
Alluxio-基于内存的虚拟分布式存储系统_机器爱上学习的博客-CSDN博客_alluxio
1 架构
1.1 概述
Alluxio作为大数据和机器学习生态系统中的一个新的数据访问层,配置在任何持久性存储系统(如Amazon S3、Microsoft Azure对象存储、Apache HDFS或OpenStack Swift)和计算框架(如Apache Spark、Presto或Hadoop MapReduce)之间。**请注意,Alluxio不是一个持久化存储系统。**使用Alluxio作为数据访问层有如下好处:
1.对于用户应用程序和计算框架,Alluxio提供了快速存储,促进了作业之间的数据共享和局部性,而不管使用的是哪种计算引擎。因此,当数据位于本地时,Alluxio可以以内存速度提供数据;当数据位于Alluxio时,Alluxio可以以计算集群网络的速度提供数据。第一次访问数据时,只从存储系统上读取一次数据。为了得到更好的性能,Alluxio推荐部署在计算集群上。
2.对于存储系统,Alluxio弥补了大数据应用与传统存储系统之间的差距,扩大了可用的数据工作负载集。当同时挂载多个数据源时,Alluxio可以作为任意数量的不同数据源的统一层。
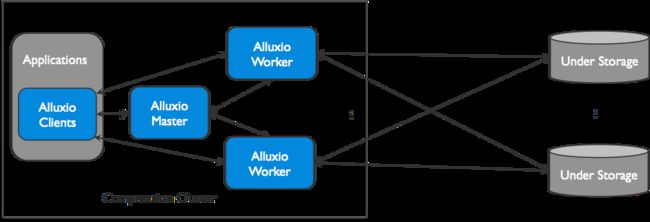
Alluxio可以被分为三个部分:**masters、workers以及clients。**一个典型的设置由一个主服务器、多个备用服务器和多个worker组成。客户端用于通过Spark或MapReduce作业、Alluxio命令行或FUSE层等应用程序与Alluxio服务器通信。
Alluxio使用了单Master和多Worker的架构,Master和Worker一起组成了Alluxio的服务端,它们是系统管理员维护和管理的组件,Client通常是应用程序,如Spark或MapReduce作业,或者Alluxio的命令行用户。Alluxio用户一般只与Alluxio的Client组件进行交互。
1.1.1Master
Alluxio主服务可以部署为一个主master和几个备用master,以实现容错。当主master奔溃时,备用master可以被选为新的主master。

Master: 负责管理整个集群的全局元数据并响应Client对文件系统的请求。在Alluxio文件系统内部,每一个文件被划分为一个或多个数据块(block),并以数据块为单位存储在Worker中。Master节点负责管理文件系统的元数据(如文件系统的inode树、文件到数据块的映射)、数据块的元数据(如block到Worker的位置映射),以及Worker元数据(如集群当中每个Worker的状态)。所有Worker定期向Master发送心跳消息汇报自己状态,以维持参与服务的资格。Master通常不主动与其他组件通信,只通过RPC服务被动响应请求,同时Master还负责实时记录文件系统的日志(Journal),以保证集群重启之后可以准确恢复文件系统的状态。Master分为Primary Master和Secondary Master,Secondary Master需要将文件系统日志写入持久化存储,从而实现在多Master(HA模式下)间共享日志,实现Master主从切换时可以恢复Master的状态信息。Alluxio集群中可以有多个Secondary Master,每个Secondary Master定期压缩文件系统日志并生成Checkpoint以便快速恢复,并在切换成Primary Master时读取之前Primary Master写入的日志。Secondary Master不处理任何Alluxio组件的任何请求。
(1)主master
Alluxio中只有一个master进程为主master。主master用于管理全局的元数据。这里面包含文件系统元数据(文件系统节点树)、数据块元数据(数据块位置)、以及worker的容量元数据(空闲或已占用空间)。Alluxio clients与主master通信用来读取或修改元数据。所有的worker都会定期的向主master发送心跳。主master会在一个分布式的持久化系统上记录所有的文件系统事务,这样可以恢复主master的信息。这组日志被称为journal。---------------导致的问题,Master内存爆了,client与master的通信过于频繁!!!
(2)备用master
备用master读取主master写入的journal日志,以保持与主master的状态同步。它们会对journal日志写入检查点,用于快速恢复。它们不处理来自Alluxio组件的任何请求。
1.1.2Worker
Worker: Alluxio Master只负责响应Client对文件系统元数据的操作,而具体文件数据传输的任务由Worker负责,如图,每个Worker负责管理分配给Alluxio的本地存储资源(如RAM,SSD,HDD),记录所有被管理的数据块的元数据,并根据Client对数据块的读写请求做出响应。Worker会把新的数据存储在本地存储,并响应未来的Client读请求,Client未命中本地资源时也可能从底层持久化存储系统中读数据并缓存至Worker本地。
Worker代替Client在持久化存储上操作数据有两个好处:1.底层读取的数据可直接存储在Worker中,可立即供其他Client使用 2.Alluxio Worker的存在让Client不依赖底层存储的连接器,更加轻量化。
Alluxio采取可配置的缓存策略,Worker空间满了的时候添加新数据块需要替换已有数据块,缓存策略来决定保留哪些数据块。
Alluxio的worker用于管理用户为Alluxio定义的本地资源(内存、SSD、HDD)。Alluxio的worker将数据存储为块,并通过在其本地资源上读或者创建新的数据块来响应client请求。Workers只用于管理数据块;文件到数据块的映射存储在master中。Workers在其底层存储上进行数据操作。这带来两个重要的优势:
1.从底层存储系统读取的数据能被存储在worker中,这样别的client可以立即使用。
2.client可以是轻量级的,不依赖于底层存储的连接器。
因为RAM的容量有限,所以当空间满了的时候block会被清理。Workers使用清理策略决定什么数据留在Alluxio中。
1.1.3 Client
Client: 允许分析和AI/ML应用程序与Alluxio连接和交互,它发起与Master的通信,执行元数据操作,并从Worker读取和写入存储在Alluxio中的数据。它提供了Java的本机文件系统API,支持多种客户端语言包括REST,Go,Python等,而且还兼容HDFS和Amazon S3的API。
可以把Client理解为一个库,它实现了文件系统的接口,根据用户请求调用Alluxio服务,客户端被编译为alluxio-2.0.1-client.jar文件,它应当位于JVM类路径上,才能正常运行。
当Client和Worker在同一节点时,客户端对本地缓存数据的读写请求可以绕过RPC接口,使本地文件系统可以直接访问Worker所管理的数据,这种情况被称为短路写,速度比较快,如果该节点没有Worker在运行,则Client的读写需要通过网络访问其他节点上的Worker,速度受网络宽带的限制。
2 Alluxio场景与数据流
Alluxio的应用场景
Alluxio 的落地非常依赖场景,否则优化效果并不明显(无法发挥内存读取的优势)
- 计算应用需要反复访问远程云端或机房的数据(存储计算分离)
- 混合云,计算与存储分离,异构的数据存储带来的系统耦合(Alluxio提供统一命名空间,统一访问接口)
- 多个独立的大数据应用(比如不同的Spark Job)需要高速有效的共享数据(数据并发访问)
- 计算框架所在机器内存占用较高,GC频繁,或者任务失败率较高,Alluxio通过数据的OffHeap来减少GC开销
- 有明显热表/热数据,相同数据被单应用多次访问
- 需要加速人工智能云上分析(如TensorFlow本地训练,可通过FUSE挂载Alluxio FS到本地)
提示:如果HDFS本身已经和Spark和Hive共置了,那么这个场景并不算Alluxio的目标场景。计算和存储分离的情况下才会有明显效果,否则通常是HDFS已经成为瓶颈时才会有帮助。“
还有,如果HDFS部署在计算框架本地,作业的输入数据可能会存在于系统的高速缓存区,则Alluxio对数据加速也并不明显。
以下:描述了Alluxio读或写的场景,基于以下的配置:Alluxio与计算集群部署在一起,持久化存储系统可以为远程存储系统或云存储。
2.1 读
在底层存储和计算集群间,Alluxio是作为一个缓存层存在的。这小节描述了不同的缓存场景以及其对性能的影响。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hvACuKUT-1647520294115)(C:\Users\anonymous\AppData\Roaming\Typora\typora-user-images\image-20220316162013845.png)]
2.1.1 本地缓存命中
本地缓存命中发生在请求数据位于本地Alluxio worker。举例说明,如果一个应用通过Alluxio client请求数据,client向Alluxio master请求数据所在的worker。如果数据在本地可用,Alluxio client使用“短路”读取来绕过Alluxio worker,并直接通过本地文件系统读取文件。短路读取避免通过TCP套接字传输数据,并提供数据的直接访问。---------------
【过程:
- 应用通过Allxuio Client与Alluxio Master通信,获得数据的位置信息(数据的元数据信息);
- 根据数据所在位置,如果数据已经被缓存到本地(内存、SSD、HDD等),可以直接访问本地缓存的数据
- 如果数据没有被缓存到本地,需要通过Alluxio worker来读取数据(数据不一定是在Alluxio的其他worker节点,还是在远程的云上-----其他worker节点,优于远程云端)!
问题:Client与Master的频繁通信,占据大量内存 】
还要注意,Alluxio除了内存之外还可以管理其他存储介质(例如SSD、HDD),因此本地数据访问速度可能会因本地存储介质的不同而有所不同。

2.1.2 远程缓存命中
当请求的数据存储在Alluxio中,而不是存储在client的本地worker上时,client将对具有数据的worker进行远程读取。client完成读取后,会要求本地的worker(如果存在)创建一个copy,这样以后读取的时候可以在本地读取相同的数据。远程缓存击中提供了网络级别速度的数据读取。Alluxio优先从远程worker读取数据,而不是从底层存储,因为Alluxio worker间的速度一般会快过Alluxio workers和底层存储的速度。

2.1.3 缓存Miss
如果数据在Alluxio中找不到,则会发生缓存丢失,应用将不得不从底层存储读取数据。Alluxio client会将数据读取请求委托给worker(本地worker优先)。这个worker会从底层存储读取数据并缓存。缓存丢失通常会导致最大的延迟,因为数据必须从底层存储获取。
当client只读取块的一部分或不按照顺序读取块时,client将指示worker异步缓存整个块。异步缓存不会阻塞client,但是如果Alluxio和底层存储系统之间的网络带宽是瓶颈,那么异步缓存仍然可能影响性能。
【异步缓存: worker从底层存储(远程云)中读取数据,返回给client;同时会将数据缓存到本地(内存、SSD、HDD等),等待下次的快速访问。

2.2 写
用户可以通过选择不同的写类型来配置应该如何写数据。写类型可以通过Alluxio API设置,也可以通过在客户机中配置属性Alluxio .user.file.writetype.default来设置。本节描述不同写类型的行为以及对应用程序的性能影响。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Pc8V5PSU-1647520294121)(C:\Users\anonymous\AppData\Roaming\Typora\typora-user-images\image-20220316162038360.png)]
2.2.1 只写入到Alluxio(MAST_CACHE)
当写类型设置为MUST_CACHE,Alluxio client将数据写入本地Alluxio worker,而不会写入到底层存储。如果“短路”写可用,Alluxio client直接写入到本地RAM的文件,绕过Alluxio worker,避免网络传输。由于数据没有持久存储在under storage中,因此如果机器崩溃或需要释放数据以进行更新的写操作,数据可能会丢失。当可以容忍数据丢失时,MUST_CACHE设置对于写临时数据非常有用。

2.2.2 写到UFS(CACHE_THROUGH)
使用CACHE_THROUGH写类型,数据被同步地写到一个Alluxio worker和下一个底层存储。Alluxio client将写操作委托给本地worker,而worker同时将对本地内存和底层存储进行写操作。由于底层存储的写入速度通常比本地存储慢,所以client的**写入速度将与底层存储的速度相匹配。**当需要数据持久化时,建议使用CACHE_THROUGH写类型。在本地还存了一份副本,以便可以直接从本地内存中读取数据。

2.2.3 写回UFS(ASYNC_THROUGH)
Alluxio提供了一个叫做ASYNC_THROUGH的写类型。数据被同步地写入到一个Alluxio worker,并异步地写入到底层存储。ASYNC_THROUGH可以在持久化数据的同时以内存速度提供数据写入。

3.Alluxio的重要配置参数
3.1 Alluxio的读写配置参数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8nlf7puJ-1647520294128)(C:\Users\anonymous\AppData\Roaming\Typora\typora-user-images\image-20220316162245501.png)]

3.2 多级存储策略
多层存储的配置-使用两层存储MEM和HDD
alluxio.worker.tieredstore.levels=2 # 最大存储级数 在Alluxio中配置了两级存储
alluxio.worker.tieredstore.level0.alias=MEM # alluxio.worker.tieredstore.level0.alias=MEM 配置了首层(顶层)是内存存储层
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk # 设置了ramdisk的配额是100GB
alluxio.worker.tieredstore.level0.dirs.quota=100GB
alluxio.worker.tieredstore.level0.watermark.high.ratio=0.9 # 回收策略的高水位
alluxio.worker.tieredstore.level0.watermark.low.ratio=0.7
alluxio.worker.tieredstore.level1.alias=HDD # 配置了第二层是硬盘层
alluxio.worker.tieredstore.level1.dirs.path=/mnt/hdd1,/mnt/hdd2,/mnt/hdd3 # 定义了第二层3个文件路径各自的配额
alluxio.worker.tieredstore.level1.dirs.quota=2TB,5TB,500GB
alluxio.worker.tieredstore.level1.watermark.high.ratio=0.9
alluxio.worker.tieredstore.level1.watermark.low.ratio=0.7
写数据默认写入顶层存储,也可以指定写数据的默认层级 alluxio.user.file.write.tier.default 默认0最顶层,1表示第二层,-1倒数第一层
Alluxio收到写请求,直接把数据写入有足够缓存的层,如果缓存全满,则置换掉底层的一个Block.
3.3 缓存回收策略
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rBsZ5w1f-1647520294129)(C:/Users/anonymous/AppData/Roaming/Typora/typora-user-images/image-20220316162719403.png)]
3.4 Alluxio的异步缓存策略
(base) [mca@clu08 bin]$ alluxio version
2.7.0-SNAPSHOT
# 当前集群使用的版本2.7.0

3.5 Alluxio元数据存储管理
存储系统元数据管理演变升级 - 知乎 (zhihu.com)
在Alluxio新的2.x版本中,对元数据存储做了优化,使其能应对数以亿级的元数据存储。
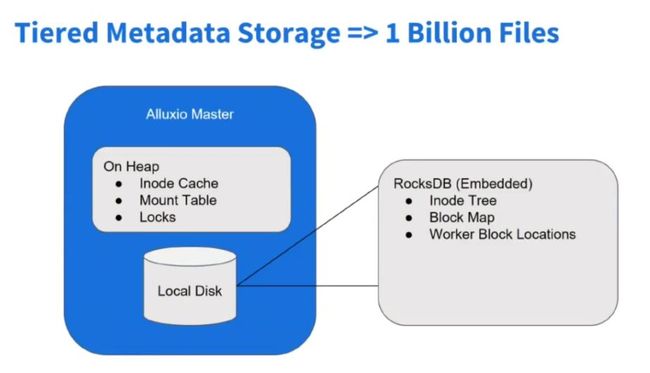
首先,文件系统是INode-Tree组成的,即文件目录树,Alluxio Master管理多个底层存储系统的元数据,每个文件目录都是INode-Tree的节点,在Java对象中,可能一个目录信息本身占用空间不大,但映射在JavaHeap内存中,算上附加信息,每个文件大概要有1KB左右的元数据,如果有十亿个文件和路径,则要有约1TB的堆内存来存储元数据,完全是不现实的。
所以,为了方便管理元数据,减小因为元数据过多对Master性能造成的影响,Alluxio的元数据通过RocksDB键值数据库来管理元数据,Master会Cache常用数据的元数据,而大部分元数据则存在RocksDB中,这样大大减小了Master Heap的压力,降低OOM可能性,使Alluxio可以同时管理多个存储系统的元数据。
通过RocksDB的行锁,也可以方便高并发的操作Alluxio元数据。
高可用过程中,INode-Tree是进程中的资源,不共享,如果ActiveMaster挂掉,StandByMaster节点可以从Journal持久日志(位于持久化存储中如HDFS)恢复状态。
这样会依赖持久存储(如HDFS)的健康状况,如果持久存储服务宕机,Journal日志也不能写,Alluxio高可用服务就会受到影响。
所以,Alluxio通过Raft算法保证元数据的完整性,即使宕机,也不会丢失已经提交的元数据。
详细演变可参考:
存储系统元数据管理演变升级 - 知乎 (zhihu.com)
3.6 元数据的一致性
-
Alluxio读取磁层存储系统的元数据,包括文件名,文件大小,创建者,组别,目录结构等
-
如果绕过Alluxio修改底层存储系统的目录结构,Alluxio会同步更新
alluxio.user.file.metadata.sync.interval=-1 Alluxio不主动同步底层存储元数据
alluxio.user.file.metadata.sync.interval=正整数 正整数指定了时间窗口,该时间窗口内不触发元数据同步
alluxio.user.file.metadata.sync.interval=0 时间窗口为0,每次读取都触发元数据同步
时间窗口越大,同步元数据频率越低,Alluxio Master性能受影响越小
-
Alluxio不加载具体数据,只加载元数据,若要加载文件数据,可以通过load命令或FileStream API
-
在Alluxio中创建文件或文件夹时可以指定是否持久化
alluxio fs -Dalluxio.user.file.writetype.default=CACHE_THROUGH mkdir /xxx
alluxio fs -Dalluxio.user.file.writetype.default=CACHE_THROUGH touch /xxx/xx
3.7 Alluxio的Metrics
度量指标信息可以让用户深入了解集群上运行的任务,是监控和调试的宝贵资源。
Alluxio的度量指标信息被分配到各种相关Alluxio组件的实例中。每个实例中,用户可以配置一组度量指标槽,来决定报告哪些度量指标信息。现支持Master进程,Worker进程和Client进程的度量指标 。
- 度量指标的sink
参数为alluxio.metrics.sink.xxx
ConsoleSink: 输出控制台的度量值。
CsvSink: 每隔一段时间将度量指标信息导出到CSV文件中。
JmxSink: 查看JMX控制台中注册的度量信息。
GraphiteSink: 给Graphite服务器发送度量信息。
MetricsServlet: 添加Web UI中的servlet,作为JSON数据来为度量指标数据服务。
- 可选度量的配置
-
Master的Metrics 配置方法 master.* 例如:master.CapacityTotal
常规信息CapacityTotal: 文件系统总容量(以字节为单位)。
CapacityUsed: 文件系统中已使用的容量(以字节为单位)。
CapacityFree: 文件系统中未使用的容量(以字节为单位)。
PathsTotal: 文件系统中文件和目录的数目。
UnderFsCapacityTotal: 底层文件系统总容量(以字节为单位)。
UnderFsCapacityUsed: 底层文件系统中已使用的容量(以字节为单位)。
UnderFsCapacityFree: 底层文件系统中未使用的容量(以字节为单位)。
Workers: Worker的数目。
逻辑操作
DirectoriesCreated: 创建的目录数目。
FileBlockInfosGot: 被检索的文件块数目。
FileInfosGot: 被检索的文件数目。
FilesCompleted: 完成的文件数目。
FilesCreated: 创建的文件数目。
FilesFreed: 释放掉的文件数目。
FilesPersisted: 持久化的文件数目。
FilesPinned: 被固定的文件数目。
NewBlocksGot: 获得的新数据块数目。
PathsDeleted: 删除的文件和目录数目。
PathsMounted: 挂载的路径数目。
PathsRenamed: 重命名的文件和目录数目。
PathsUnmounted: 未被挂载的路径数目。
RPC调用
CompleteFileOps: CompleteFile操作的数目。
CreateDirectoryOps: CreateDirectory操作的数目。
CreateFileOps: CreateFile操作的数目。
DeletePathOps: DeletePath操作的数目。
FreeFileOps: FreeFile操作的数目。
GetFileBlockInfoOps: GetFileBlockInfo操作的数目。
GetFileInfoOps: GetFileInfo操作的数目。
GetNewBlockOps: GetNewBlock操作的数目。
MountOps: Mount操作的数目。
RenamePathOps: RenamePath操作的数目。
SetStateOps: SetState操作的数目。
UnmountOps: Unmount操作的数目。 -
Worker的Metrics 配置方法 192_168_1_1.* 例如:192_168_1_1.CapacityTotal
常规信息
CapacityTotal: 该Worker的总容量(以字节为单位)。
CapacityUsed: 该Worker已使用的容量(以字节为单位)。
CapacityFree: 该Worker未使用的容量(以字节为单位)。
逻辑操作
BlocksAccessed: 访问的数据块数目。
BlocksCached: 被缓存的数据块数目。
BlocksCanceled: 被取消的数据块数目。
BlocksDeleted: 被删除的数据块数目。
BlocksEvicted: 被替换的数据块数目。
BlocksPromoted: 被提升到内存的数据块数目。
BytesReadAlluxio: 通过该worker从Alluxio存储读取的数据量,单位为byte。其中不包括UFS读。
BytesWrittenAlluxio: 通过该worker写到Alluxio存储的数据量,单位为byte。其中不包括UTF写。
BytesReadUfs-UFS: U F S : 通 过 该 w o r k e r 从 指 定 U F S 读 取 的 数 据 量 , 单 位 为 b y t e 。 B y t e s W r i t t e n U f s − U F S : {UFS}: 通过该worker从指定UFS读取的数据量,单位为byte。 BytesWrittenUfs-UFS: UFS:通过该worker从指定UFS读取的数据量,单位为byte。BytesWrittenUfs−UFS:{UFS}: 通过该worker写到指定UFS的数据量,单位为byte。 -
Client的Metrics 配置方法 client.* 例如:clien.BytesReadRemote
常规信息
NettyConnectionOpen: 当前Netty网络连接的数目。
逻辑操作
BytesReadRemote: 远程读取的字节数目。
BytesWrittenRemote: 远程写入的字节数目。
BytesReadUfs: 从ufs中读取的字节数目。
BytesWrittenUfs: 写入ufs的字节数目。
配置示例
vim metrics.properties
# List of available sinks and their properties.
alluxio.metrics.sink.ConsoleSink
alluxio.metrics.sink.CsvSink
alluxio.metrics.sink.JmxSink
alluxio.metrics.sink.MetricsServlet
alluxio.metrics.sink.PrometheusMetricsServlet
alluxio.metrics.sink.GraphiteSink
master.GetFileBlockInfoOps
master.GetNewBlockOps
master.FreeFileOps
192_168_1_101.BytesReadAlluxio
192_168_1_101.BytesWrittenAlluxio
192_168_1_101.BlocksAccessed
192_168_1_101.BlocksCached
192_168_1_101.BlocksCanceled
192_168_1_101.BlocksDeleted
192_168_1_101.BlocksEvicted
192_168_1_101.BlocksPromoted
192_168_1_102.BytesReadAlluxio
192_168_1_102.BytesWrittenAlluxio
192_168_1_102.BlocksAccessed
192_168_1_102.BlocksCached
192_168_1_102.BlocksCanceled
192_168_1_102.BlocksDeleted
192_168_1_102.BlocksEvicted
192_168_1_102.BlocksPromoted
192_168_1_103.BytesReadAlluxio
192_168_1_103.BytesWrittenAlluxio
192_168_1_103.BlocksAccessed
192_168_1_103.BlocksCached
192_168_1_103.BlocksCanceled
192_168_1_103.BlocksDeleted
192_168_1_103.BlocksEvicted
192_168_1_103.BlocksPromoted
然后访问 http://192.168.1.101:19999/metrics/json/ 可得到监控信息
3.8 Alluxio审计日志
Alluxio提供审计日志来方便管理员可以追踪用户对元数据的访问操作。
开启审计日志: 讲JVM参数alluxio.master.audit.logging.enabled设为true
审计日志包含如下条目:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nX6nBaku-1647520294131)(C:/Users/anonymous/AppData/Roaming/Typora/typora-user-images/image-20220316163810322.png)]
4.配置资源
Alluxio属性可以在多个资源中配置。在这种情况下,它的最终值由列表中最早的资源配置决定:
- JVM系统参数 (i.e.,
-Dproperty=key) - 环境变量
- 参数配置文件. 当Alluxio集群启动时, 每一个Alluxio服务端进程(包括master和worke) 在目录
${HOME}/.alluxio/,/etc/alluxio/and${ALLUXIO_HOME}/conf下顺序读取alluxio-site.properties, 当alluxio-site.properties文件被找到,将跳过剩余路径的查找. - 集群默认值. Alluxio客户端可以根据master节点提供的集群范围的默认配置初始化其配置。
如果没有为属性找到上面用户指定的配置,那么会回到它的默认参数值。
要检查特定配置属性的值及其值的来源,用户可以使用以下命令行:
$ ./bin/alluxio getConf alluxio.worker.rpc.port
29998
$ ./bin/alluxio getConf --source alluxio.worker.rpc.port
DEFAULT
列出所有配置属性的来源:
$ ./bin/alluxio getConf --source
alluxio.conf.dir=/Users/bob/alluxio/conf (SYSTEM_PROPERTY)
alluxio.debug=false (DEFAULT)
...
用户还可以指定--master选项来通过master节点列出所有的集群默认配置属性 。注意,使用--master选项 getConf将查询master,因此需要主节点运行;没有--master 选项,此命令只检查本地配置。
$ ./bin/alluxio getConf --master --source
alluxio.conf.dir=/Users/bob/alluxio/conf (SYSTEM_PROPERTY)
alluxio.debug=false (DEFAULT)
...