【一】微服务技术栈导学
一、微服务技术栈导学
- 1 什么是微服务?
- 2 微服务技术栈
-
- 2.1 注册中心
- 2.2 配置中心
- 2.3 服务网关
- 2.4 分布式缓存
- 2.5 分布式搜索
- 2.6 消息队列
- 2.7 分布式日志服务&系统监控和链路追踪
- 2.8 自动化部署
- 3 微服务技术栈包含知识点
- 4 学习路线
知识内容来自于黑马程序员视频教学和百度百科。博主仅作笔记整理便于回顾学习。如有侵权请私信我。
1 什么是微服务?
微服务(或微服务架构):是一种云原生架构方法,其中单个应用程序由许多松散耦合且可独立部署的较小组件或服务组成。
这些服务通常
- 有自己的堆栈,包括数据库和数据模型;
- 通过REST API,事件流和消息代理的组合相互通信;
- 它们是按业务能力组织的,分隔服务的线通常称为有界上下文。
尽管有关微服务的许多讨论都围绕体系结构定义和特征展开,但它们的价值可以通过相当简单的业务和组织收益更普遍地理解:
- 可以更轻松地更新代码。
- 团队可以为不同的组件使用不同的堆栈。
- 组件可以彼此独立地进行缩放,从而减少了因必须缩放整个应用程序而产生的浪费和成本,因为单个功能可能面临过多的负载。
微服务也可以通过它们不是什么来理解。微服务架构最经常得出的两个比较是整体架构和面向服务的架构(SOA)。
微服务和整体架构之间的区别在于,微服务由许多较小的,松散耦合的服务组成一个应用程序,与大型,紧密耦合的应用程序的整体方法相反。
举例:
一个商城系统就得提供相当多的服务, 比如订单服务,用户功能,商品服务,支付服务等等,这些模块如果使用单体架构来实现,那么耦合度会相当高,开发难度也会很大。如果使用微服务开发,把每一个服务都当成一个单体应用来开发,那么订单服务,用户服务,商品服务,支付服务等模块,每一个就成为一个微服务。
由这些微服务构成整个的商城系统。这样明显是更加合理的。每个服务也可以根据业务的需要去进行集群部署。一方面降低了服务的耦合,一方面有利于服务的维护升级。
2 微服务技术栈

微服务要做的第一件事情就是拆分。因为传统的单体架构是所有的业务功能写在一起,随着业务越来越复杂,代码饱和的变得越来越多。将来想要升级维护就会变得很困难。所以像一些大型的互联网项目就必须去做拆分。

拆分的时候,会根据业务模块把一个单体的项目,拆分成许多独立的项目。每一个项目完成一部分业务功能,将来独立开发和部署。把这样一个独立的项目称为服务。

一个大型的互联网项目往往会包含数百甚至上千的服务,最后形成一个服务集群。而一个业务往往就需要由多个服务共同来完成。
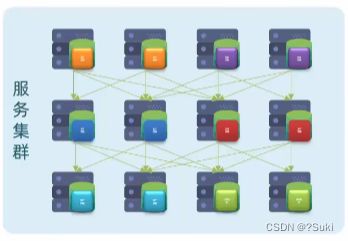
比如说一个请求来了,它可能先去调用了服务A,服务A又去调用服务B,服务B又去调用服务C,当业务越来越复杂时,这些服务之间的关系就会越来越复杂。
这么复杂的一个调用关系,想靠人去记录和维护是不可能的。
2.1 注册中心

所以在微服务里会有一个组件叫做注册中心。它可以去记录微服务中每一个服务的端口,IP,以及它能完成什么功能这些信息。
当一个服务需要调用另一个服务时,它不需要自己去记录对方的IP,只要去找注册中心就行了。从注册中心去拉取对应的注册信息。
2.2 配置中心
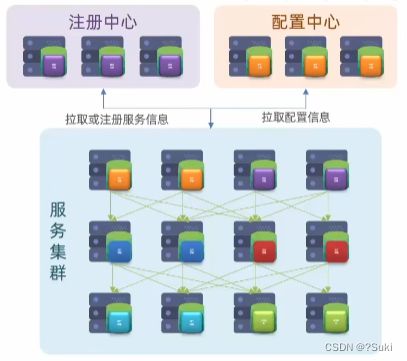
同时,随着服务越来越多,每个服务都有自己的配置文件,将来如果要更改配置,如果逐一去修改,那会十分麻烦。
所以在微服务里还会有一个配置中心。它可以统一去管理整个服务群体成千上百的这些配置。如果以后有些配置需要变更,只需要去找到配置中心便可。它可以去通知相关的微服务,实现配置的“热更新”。
2.3 服务网关
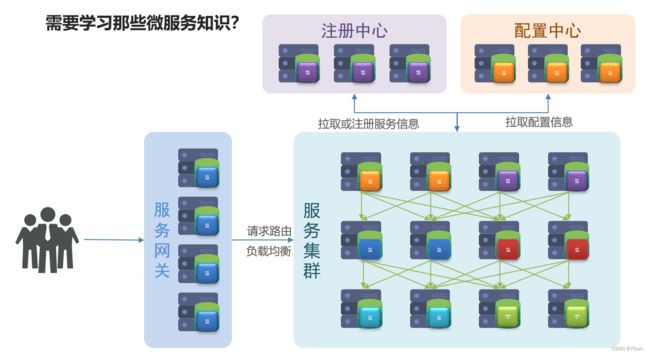
当我们的微服务运行起来以后,用户就可以来访问我们。这个时候还需要一个服务网关,因为这里有这么多的微服务,用户如何知道该访问哪一个呢?而且也不是随便什么人都能来访问我们的服务吧。
举例:就像一个小区,服务网关就相当于门卫大叔。服务集群中的每一个服务就相当于小区里的住户。当有用户来请求访问服务时,它还需要知道具体的服务“住在哪里”?
所以,服务网关:
- 一方面校验用户的身份;
- 另一方面,可以将用户的请求路由到我们具体的服务中。
路由过程中,也可以去做一些负载均衡。
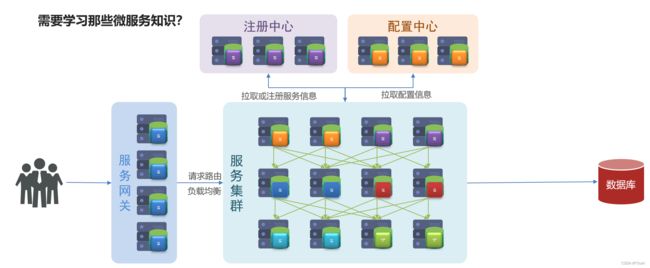
这个时候服务接收到请求去处理业务,该访问数据库的时候访问数据库,最后把查询到的数据放回给用户就ok了。
2.4 分布式缓存
这里虽然画的是一个数据库,但实际上会是一个数据库集群。不过集群在庞大,也不可能有用户多。所以将来数据库肯定无法扛住这样的高并发。
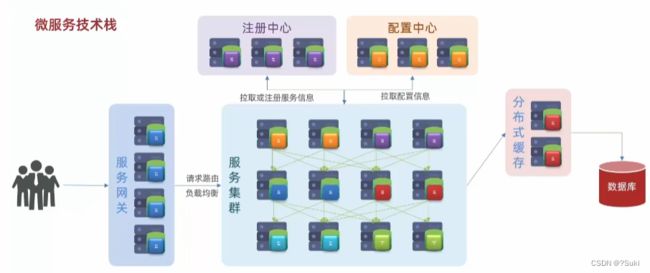
因此我们还会加入缓存。缓存就是把数据库数据放入到内存当中。内存的查询效率比数据库快很多。
而且这样的缓存还不能是单体缓存为了应对高并发,还要做成这样分布式缓存。也是一个集群。
用户的请求先到缓存,缓存未命中再去查询数据库。
2.5 分布式搜索
业务中还会有许多搜索功能,简单查询可以走缓存,一些海量的搜索,复杂的搜索途径分析,缓存也无法完成。
这个时候,还需要用到分布式搜索。数据库将来主要的职责就是做一种数据的写操作,还有一些事务类型,对安全性要求较高的数据存储。
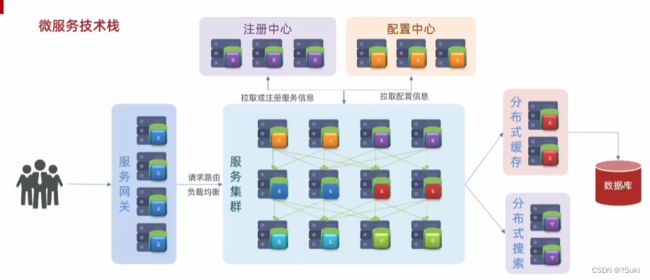
2.6 消息队列
最后,在微服务当中还需要一种异步通信的消息队列组件。
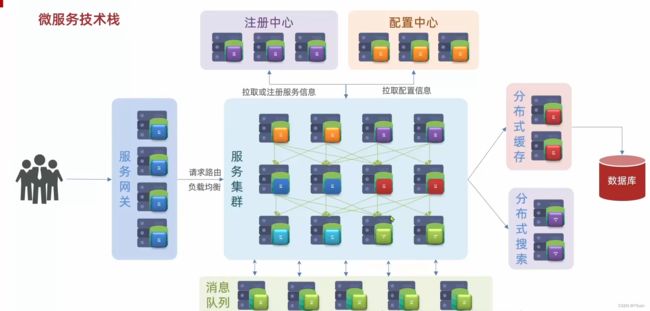
为什么呢?其实对于分布式服务或在微服务里面,业务往往会跨越多个服务。一个请求来了,它先调用服务A,A再调用B,B再调用C,整个业务的链路就会很长。响应时长就会等于每个服务的执行服务之和,所以性能会有一定的下降。
而异步通信 的意思就就是:当请求来了,调用了服务A,这个时候,服务A不是去调用服务B和C,而是发一条消息通知服务B和C:“你们两个,赶紧干活去。”这个时候服务B和C就去干活了,而服务A直接结束。所以业务链路就变短了,响应时间也缩短了,我们的吞吐能力也就变强了。
异步通信能大大提高我们服务的并发。
在一些秒杀这样的高并发场景下,就可以去利用了。
2.7 分布式日志服务&系统监控和链路追踪
在这样一个如此庞大和复杂的服务,在运行过程中,如果出现了什么问题,如何排查呢?
所以在微服务运行过程中,我们还会引入两个组件:来解决服务的异常定位。
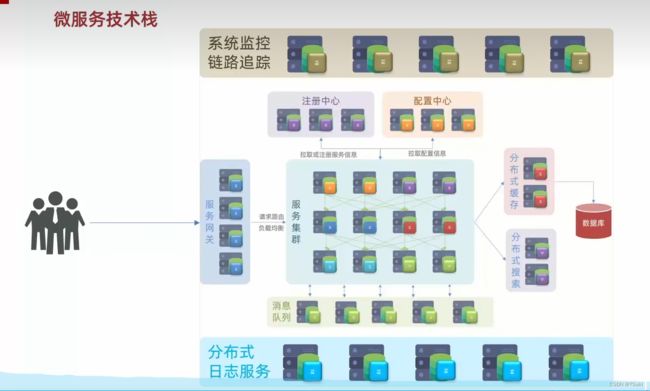
分布式日志服务: 统计整个集群成千上百的服务的运行日志,统一地去做一个存储,统计,分析。将来出现问题就会方便定位。
系统监控&链路追踪: 实时监控整个集群中每一个服务结点的运行状态,CPU负载,内存占用等等情况。一旦出现任何问题,直接可以定位到具体的某一个方法,栈信息。这便可以很快的定位到异常所在。
2.8 自动化部署
那么如此庞大复杂的微服务集群,将来很有可能达到成百上千甚至上万的服务。这个时候我们部署该怎么办呢?如果是靠人工去部署,显然不现实。所以将来这些微服务集群,还需要去做一种自动化的部署。

Jenkins:可以帮助对这些微服务项目进行自动化的编译。基于docker去做一些打包,形成镜像。再基于kubernetes或者rancher这样的技术,去实现自动化的部署。
这一套就称为持续集成(Continuous Integration)。
结合微服务的技术,再加上持续集成,这才是完整的微服务技术栈。
3 微服务技术栈包含知识点
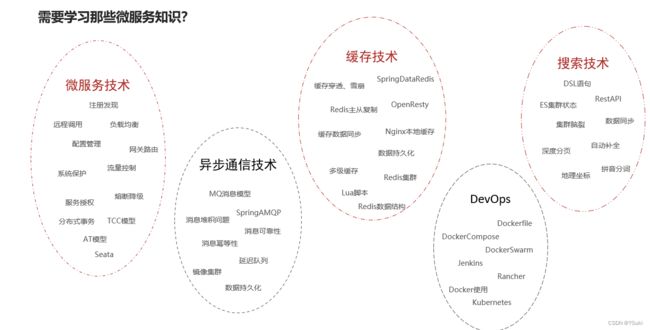
微服务治理: 这一部分就是SpringCloud这个框架它所包含的一些技术。
4 学习路线

By–Suki 2022/12/29