面试之 Python 框架 Flask、Django、DRF
Django、flask、tornado 框架的比较 ★★★★★
-
Django:大而全的框架。它的内部组件比较多,如 ORM、Admin、中间件、Form、ModelForm、Session、缓存、信号、CSRF等,功能也都很完善。
-
flask:微型框架,内部组件就比较少了,但是有很多第三方组件来扩展它,比如 wtform(与django的modelform类似,表单验证)、flask-sqlalchemy(操作数据库的)、flask-session、flask-migrate、flask-script、blinker等,可扩展强,第三方组件丰富。所以对他本身来说有那种短小精悍的感觉。
-
tornado:异步非阻塞。是一个轻量级的Web框架,异步非阻塞+内置WebSocket功能。目标是通过一个线程处理N个并发请求(处理IO)。'内部组件:内部自己实现socket、路由系统、视图、模板、cookie、csrf。
Django 和 flask 对比:
-
他们都没有写socket,所以他们都是利用第三方模块wsgi,但是内部使用的wsgi也是有些不同的:Django 使用 wsgiref,而 flask 使用werkzeug wsgi。
-
他们的请求管理不太一样:django 是通过将请求封装成 request 对象,再通过参数传递,而 flask 是通过上下文管理机制。
WSGI、uwsgi 和 WSGI 的区别 ★★★
-
WSGI:全称 Web Server Gateway Interface(Web服务器网关接口),是一种通用的接口标准或者接口协议。定义了Web服务器如何与Python应用程序进行交互,使得用Python写的Web应用程序可以和Web服务器对接起来。
- 以下模块实现了 WSGI 协议:
wsgiref,werkzurg,uWSGI。 - 这几个模块本质:编写socket服务端,用于监听请求,当有请求到来,则将请求数据进行封装,然后交给web框架处理。
- 以下模块实现了 WSGI 协议:
-
uwsgi:同 WSGI 一样是一种通信协议,它是一个二进制协议,uwsgi 协议是一个uWSGI服务器自有的协议,它用于定义传输信息的类型。
-
uWSGI:uWSGI 是一种 web 服务器,是实现了 uwsgi 和 WSGI 两种协议的Web服务器,负责响应 Python 的 web 请求。
Django
简述 MVC 和 MTV ★★★★★
MVC:model(数据库)、view(模块)、controller(视图,控制)
MTV:model(数据库)、tempalte(视图)、view(控制)
django请求的生命周期 ★★★★★
用户请求进来先走到 wsgiref --> 然后将请求交给 Django 的中间件 --> 穿过 Django 中间件(方法是process_request)--> 路由匹配 --> 路由匹配成功之后就执行相应的视图函数 --> 在视图函数中可以调用orm做数据库操作 --> 再从模板路径将模板拿到 --> 然后在后台进行模板渲染 --> 模板渲染完成之后就变成一个字符串 --> 再把这个字符串经过所有中间件(方法:process_response) --> 最后通过 wsgi 封装返回给用户
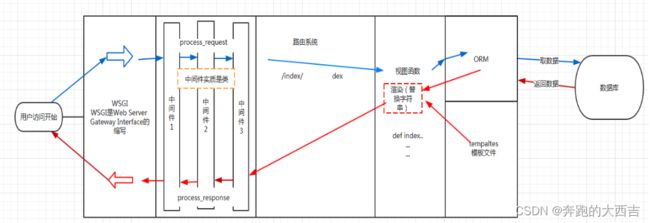
列举django的内置组件 ★★★
form 组件
- 对用户请求的数据进行校验
- 生成HTML标签
信号
django的信号其实就是django内部为开发者预留的一些自定制功能的钩子。
只要在某个信号中注册了函数,那么django内部执行的过程中就会自动触发注册在信号中的函数。如
pre_init:django的modal执行其构造方法前,自动触发。post_init:django的modal执行其构造方法后,自动触发。pre_save:django的modal对象保存前,自动触发。post_save:django的modal对象保存后,自动触发。
场景:在数据库某些表中添加数据时,可以进行日志记录。
CSRF
目标:防止用户直接向服务端发起 POST 请求。对所有的 POST请求做验证。
方案:发送GET请求时,服务器将 token 保存到:cookie、Form表单中(隐藏的input标签),以后浏览器再发送请求时只要携带过来即可。
ContentType
ContentType 是 Django 的一个组件(app),为我们找到 Django 程序中所有app中的所有表并添加到记录中。
可以使用他再加上表中的两个字段实现:一张表和N张表创建FK关系。 - 字段:表名称 - 字段:数据行ID。
中间件
对所有的请求进行批量处理,在视图函数执行前后进行自定义操作。
应用:用户登录校验。
问题:为甚么不使用装饰器?
答案:如果不使用中间件,就需要给每个视图函数添加装饰器,太繁琐。
session
cookie 与 session 区别:
cookie 是保存在浏览器端的键值对,而 session 是保存的服务器端的键值对,但是依赖cookie。(也可以不依赖cookie,可以放在url,或请求头但是cookie比较方便)
以登录为例,cookie为通过登录成功后,设置明文的键值对,并将键值对发送客户端存,明文信息可能存在泄漏,不安全;session则是生成随机字符串,发给用户,并写到浏览器的 cookie 中,同时服务器自己也会保存一份。
在登录验证时,cookie验证:根据浏览器发送请求时附带的cookie的键值对进行判断,如果存在,则验证通过;session验证:在请求用户的cookie中获取随机字符串,根据随机字符串在session中获取其对应的值进行验证。
cors跨域(场景:前后端分离时,本地测试开发时使用)
首先说域的概念,协议(http/https)+ 域名或IP地址 + 端口号 共同构成了域,三者有一个不同,则为不同的域。
如果网站之间存在跨域,浏览器因为同源策略的限制,而决绝解析返回的数据。
解决:在服务端的响应数据中加上对应的响应头(Django在中间件process_response)。
缓存
常用的数据放在缓存里面,就不用走视图函数,请求进来通过所有的 process_request 之后,会到缓存里面查数据,有就直接拿,没有就走视图函数,注意:
- 执行完所有的 process_request 才去缓存取数据。
- 执行完所有的 process_response 才将数据放到缓存。
关于缓存问题:
-
为什么放在最后一个 process_request 才去缓存。
因为需要验证完用户的请求,才能返回数据。 -
什么时候将数据放到缓存中。
第一次走中间件,缓存没有数据,会走视图函数,取数据库里面取数据,当走完process_response,才将数据放到缓存里,因为走 process_response 的时候可能给我们的响应加处理。 -
为什么使用缓存。
将常用且不太频繁修改的数据放入缓存。以后用户再来访问,先去缓存查看是否存在,如果有就返回,否则,去数据库中获取并返回给用户(再加入到缓存,以便下次访问)。
Django 中间件的5个方法以及应用场景 ★★★★★
process_request(self,request) request先执行注册的 process_request,通过执行注册的 process_view
process_view(self, request, callback, callback_args, callback_kwargs) 先执行注册的 process_view,再执行view
process_template_response(self,request,response) 当视图函数的返回值
process_exception(self, request, exception) 当视图函数的返回值对象中有render方法时,该方法才会被调用
process_response(self, request, response) 返回时执行注册的 process_response

简述什么是FBV和CBV
# FBV 的路由和视图是基于函数的,FBV 写法
# urls.py
url(r'^login/$',views.login, name="login"),
# views.py
def login(request):
if request.method == "POST":
print(request.POST)
return render(request,"login.html")
# HTML
登录页面
# CBV 的路由和视图是基于类的
# urls.py
url(r'^login/$',views.Login.as_view(), name="login"),
# views.py
from django.views import View
class Login(View): # 类首字母大写
def get(self,request):
return render(request,"login.html")
def post(self,request):
print(request.POST)
return HttpResponse("OK")
class IndexView(View):
# 如果是crsf相关,必须放在此处
def dispach(self,request):
# 通过反射执行post/get
@method_decoretor(装饰器函数)
def get(self,request):
pass
def post(self,request):
pass
# 路由:
IndexView.as_view()
FBV与CBV的区别:
没什么区别,因为他们的本质都是函数。CBV的 .as_view() 返回的view函数,view 函数中调用类的 dispatch方法,在dispatch方法中通过反射执行 get/post/delete/put 等方法。
非要说区别的话:CBV比较简洁,GET/POST等业务功能分别放在不同get/post函数中。FBV自己做判断进行区分。
Django 的 request 对象是在什么时候创建的 ★★★
当 request请求 到达 Django 服务器时, Django 会建立一个包含请求元数据的 HttpRequest 对象。当 Django 加载对应的视图时, HttpRequest 对象将作为视图函数的第一个参数传递给视图。当执行完视图的代码之后,每个视图会返回一个HttpResponse对象。
具体代码是:请求走到WSGIHandler类的时候,执行cell方法,将environ封装成了request。
class WSGIHandler(base.BaseHandler):
request = self.request_class(environ)
如何给CBV的程序添加装饰器
# 方式一:
from django.views import View
from django.utils.decorators import method_decorator # ---> 需要引入memethod_decorator
def auth(func):
def inner(*args,**kwargs):
return func(*args,**kwargs)
return inner
class UserView(View):
@method_decorator(auth)
def get(self,request,*args,**kwargs):
return HttpResponse('...')
# 方式二:csrf的装饰器要加到dispath前面
from django.views import View
from django.utils.decorators import method_decorator
from django.views.decorators.csrf import csrf_exempt,csrf_protect # ---> 需要引入 csrf_exempt
class UserView(View):
@method_decorator(csrf_exempt)
def dispatch(self, request, *args, **kwargs):
return HttpResponse('...')
# 或者:
from django.views import View
from django.utils.decorators import method_decorator
from django.views.decorators.csrf import csrf_exempt,csrf_protect
@method_decorator(csrf_exempt,name='dispatch') ---> 指定名字
class UserView(View):
def dispatch(self, request, *args, **kwargs):
return HttpResponse('...')
ORM
列举django ORM 中的方法(QuerySet对象的所有方法) ★★★★★
返回QuerySet对象的方法有:
all()
filter() # 满足filter条件的对象的集合,其结果的表现形式是列表,单独更具体的获取其中的对象时可以用下标来操作。类似[object1, object2,object3, object4,object5, object6...])表格就映射成一个类,里面的每一行记录就是一个对象,get方法就是获取其中的一个元素,获取的是满足条件的某一个个体。
exclude()
order_by()
reverse()
distinct()
特殊的QuerySet:
values() # 返回一个可迭代的字典序列
values_list() # 返回一个可迭代的元组序列
返回具体对象的:
get() # 返回的是一个对象。结果是字典形式,不存在则报错,存在多个也报错
first() # 如果为空时,使用first()时得到一个None对象
last() # 如果为空时,使用last()时得到一个None对象
返回布尔值的方法有:
exists()
返回数字的方法有:
count()
only 和 defer的区别?
- only:仅取某个表中的数据。
- defer:映射中排除某列数据。
def defer(self, *fields):
# 映射中排除某列数据
models.UserInfo.objects.defer('username','id')
# 或
models.UserInfo.objects.filter(...).defer('username','id')
def only(self, *fields):
# 仅取某个表中的数据
models.UserInfo.objects.only('username','id')
# 或
models.UserInfo.objects.filter(...).only('username','id')
select_related 和 prefetch_related 的区别
他俩都用于连表查询,减少SQL查询次数。
-
select_related 主要针一对一和多对一关系进行优化,通过多表join关联查询,一次性获得所有数据,存放在内存中,但如果关联的表太多,会严重影响数据库性能。
def index(request): obj = Book.objects.all().select_related("publisher") return render(request, "index.html", locals()) # 举例 def select_related(self, *fields) # 性能相关:表之间进行join连表操作,一次性获取关联的数据。 model.tb.objects.all().select_related() model.tb.objects.all().select_related('外键字段') model.tb.objects.all().select_related('外键字段__外键字段') -
prefetch_related 是通过分表,先获取各个表的数据,存放在内存中,然后通过 Python 处理他们之间的关联。
def index(request): obj = Book.objects.all().prefetch_related("publisher") return render(request, "index.html", locals()) def prefetch_related(self, *lookups) # 性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 # 获取所有用户表 # 获取用户类型表where id in (用户表中的查到的所有用户ID) models.UserInfo.objects.prefetch_related('外键字段') from django.db.models import Count, Case, When, IntegerField Article.objects.annotate(numviews=Count(Case(When(readership__what_time__lt=treshold, then=1), output_field=CharField(),))) students = Student.objects.all().annotate(num_excused_absences=models.Sum(models.Case(models.When(absence__type='Excused', then=1),default=0,output_field=models.IntegerField())))
# 1次SQL
# select * from userinfo
objs = UserInfo.obejcts.all()
for item in objs:
print(item.name)
# n+1次SQL
# select * from userinfo
objs = UserInfo.obejcts.all()
for item in objs:
# select * from usertype where id = item.id
print(item.name,item.ut.title)
# 1次SQL,使用select_related()
# select * from userinfo inner join usertype on userinfo.ut_id = usertype.id
objs = UserInfo.obejcts.all().select_related('ut') 连表查询
for item in objs:
print(item.name,item.ut.title)
# prefetch_related()
# select * from userinfo where id <= 8
# 计算:[1,2]
# select * from usertype where id in [1,2]
objs = UserInfo.obejcts.filter(id__lte=8).prefetch_related('ut')
for obj in objs:
print(obj.name,obj.ut.title)
filter 和 exclude 的区别?
def filter(self, *args, **kwargs)
# 条件查询(符合条件)
# 查出符合条件
# 条件可以是:参数,字典,Q
def exclude(self, *args, **kwargs)
# 条件查询(排除条件)
# 排除不想要的
# 条件可以是:参数,字典,Q
列举 Django orm 中三种能写sql语句的方法
# 原生SQL ---> connection
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..)
# 靠近原生SQL-->extra\raw
# extra
def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# 构造额外的查询条件或者映射,如:子查询
Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"},select_params=(1,))
Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
# raw
def raw(self, raw_query, params=None, translations=None, using=None):
# 执行原生SQL
models.UserInfo.objects.raw('select * from userinfo')
# 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名
models.UserInfo.objects.raw('select id as nid,name as title from 其他表')
# 为原生SQL设置参数
models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,])
# 将获取的到列名转换为指定列名
name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'}
Person.objects.raw('SELECT * FROM some_other_table', translations=name_map)
# 指定数据库
models.UserInfo.objects.raw('select * from userinfo', using="default")
Django orm 中如何设置读写分离?
# 方式一:手动使用queryset的using方法
from django.shortcuts import render,HttpResponse
from app01 import models
def index(request):
models.UserType.objects.using('db1').create(title='普通用户')
# 手动指定去某个数据库取数据
result = models.UserType.objects.all().using('db1')
print(result)
return HttpResponse('...')
# 方式二:写配置文件
class Router1:
# 指定到某个数据库取数据
def db_for_read(self, model, **hints):
"""
Attempts to read auth models go to auth_db.
"""
if model._meta.model_name == 'usertype':
return 'db1'
else:
return 'default'
# 指定到某个数据库存数据
def db_for_write(self, model, **hints):
"""
Attempts to write auth models go to auth_db.
"""
return 'default'
# 再写到配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
},
'db1': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
DATABASE_ROUTERS = ['db_router.Router1',]
F和Q的作用 ★★★
F:主要用来获取原数据进行计算。Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
F查询专门对对象中某列值的操作,不可使用__双下划线!
修改操作也可以使用F函数,比如将每件商品的价格都在原价格的基础上增加10。
from django.db.models import F
from app01.models import Goods
Goods.objects.update(price=F("price")+10) # 对于goods表中每件商品的价格都在原价格的基础上增加10元
Q:用来进行复杂查询,Q查询可以组合使用 “&”、“|” 操作符,当一个操作符是用于两个Q的对象,它产生一个新的Q对象,Q对象可以用 “~” 操作符放在前面表示否定,也可允许否定与不否定形式的组合。
Q对象可以与关键字参数查询一起使用,不过一定要把Q对象放在关键字参数查询的前面。
- Q(条件1) | Q(条件2): 或
- Q(条件1) & Q(条件2): 且
- Q(条件1) & ~Q(条件2): 非
values 和 values_list 的区别?
def values(self, *fields):
# 获取每行数据为字典格式
def values_list(self, *fields, **kwargs):
# 获取每行数据为元祖
如何使用 Django orm 批量创建数据?
def bulk_create(self, objs, batch_size=None):
# 批量插入
# batch_size 表示一次插入的个数
objs = [
models.DDD(name='r11'),
models.DDD(name='r22')
]
models.DDD.objects.bulk_create(objs, 10)
Django 的 Form 和 ModelForm 的作用?
-
作用:
- 对用户请求数据格式进行校验。
- 自动生成HTML标签。
-
区别:
- Form,字段需要自己手写。
class Form(Form): xx = fields.CharField(.) xx = fields.CharField(.) xx = fields.CharField(.) xx = fields.CharField(.) - ModelForm,可以通过Meta进行定义
class MForm(ModelForm): class Meta: fields = "__all__" model = UserInfo
- Form,字段需要自己手写。
-
应用:只要是客户端向服务端发送表单数据时,都可以进行使用,如:用户登录注册。
Django 的 Form 组件中,如果字段中包含choices参数,请使用两种方式实现数据源实时更新。
原因:choice的数据如果从数据库获取可能会造成数据无法实时更新。
# 方式一:重写构造方法,在构造方法中重新去数据库获取值
class UserForm(Form):
name = fields.CharField(label='用户名',max_length=32)
email = fields.EmailField(label='邮箱')
ut_id = fields.ChoiceField(
# choices=[(1,'普通用户'),(2,'IP用户')]
choices=[]
)
def __init__(self,*args,**kwargs):
super(UserForm,self).__init__(*args,**kwargs)
self.fields['ut_id'].choices = models.UserType.objects.all().values_list('id','title')
# 方式二: ModelChoiceField字段
from django.forms import Form
from django.forms import fields
from django.forms.models import ModelChoiceField
class UserForm(Form):
name = fields.CharField(label='用户名',max_length=32)
email = fields.EmailField(label='邮箱')
ut_id = ModelChoiceField(queryset=models.UserType.objects.all())
# 依赖:
class UserType(models.Model):
title = models.CharField(max_length=32)
def __str__(self):
return self.title
Django 的 Model 中的 ForeignKey 字段中的 on_delete 参数有什么作用
在 Django2.0 后,定义外键和一对一关系的时候需要加on_delete选项,此参数为了避免两个表里的数据不一致问题,不然会报错:
TypeError: __init__() missing 1 required positional argument: 'on_delete'
举例说明:
user=models.OneToOneField(User)
owner=models.ForeignKey(UserProfile)
# 需要改成:
user=models.OneToOneField(User,on_delete=models.CASCADE) # 在老版本这个参数(models.CASCADE)是默认值
owner=models.ForeignKey(UserProfile,on_delete=models.CASCADE) # 在老版本这个参数(models.CASCADE)是默认值
on_delete 有CASCADE、PROTECT、SET_NULL、SET_DEFAULT、SET()五个可选择的值:
- CASCADE:此值设置,是级联删除。一般情况下使用CASCADE就可以了。
- PROTECT:此值设置,是会报完整性错误。
- SET_NULL:此值设置,会把外键设置为null,前提是允许为null。
- SET_DEFAULT:此值设置,会把设置为外键的默认值。
- SET():此值设置,会调用外面的值,可以是一个函数。
解释 ORM 中 db first 和 code first的含义?
- db first: 先创建数据库,再更新表模型。
- code first:先写表模型,再更新数据库。
- https://www.cnblogs.com/jassin-du/p/8988897.html。
Django 中如何根据数据库表生成 model 中的类?
- 修改 seting 文件,在setting里面设置要连接的数据库类型和名称、地址。
- 运行
python manage.py inspectdb可以自动生成models模型文件。 - 创建一个app执行
python manage.py inspectdb > app/models.py命令。
使用 ORM 和原生 sql 的优缺点
SQL:
- 优点:执行速度快。
- 缺点:编写复杂,开发效率不高。
ORM:
- 优点:让用户不再写SQL语句,提高开发效率,可以很方便地引入数据缓存之类的附加功能。
- 缺点:在处理多表联查、where条件复杂查询时,ORM的语法会变得复杂,没有原生SQL速度快。
Django中如何实现 ORM 表中添加数据时创建一条日志记录
给信号注册函数,使用 Django 的信号机制,可以在添加、删除数据前后设置日志记录。
pre_init # Django中的model对象执行其构造方法前,自动触发
post_init # Django中的model对象执行其构造方法后,自动触发
pre_save # Django中的model对象保存前,自动触发
post_save # Django中的model对象保存后,自动触发
pre_delete # Django中的model对象删除前,自动触发
post_delete # Django中的model对象删除后,自动触发
Django 中 csrf 的实现机制 ★★★★★
目的:防止用户直接向服务端发起POST请求。
-
配置文件中开启CSRF中间件,然后在所有的 POST 表单模板中,加一个
{%csrf_token%}标签,它的功能其实是给form增加一个隐藏的input标签,如下,而这个csrf_token = cookie.csrftoken,在渲染模板时context中有context['csrf_token'] = request.COOKIES['csrftoken']。 -
在用户访问 Django 的站点时,Django会渲染该模板,并在页面中生成一个 csrftoken 口令,这个值是在服务器端随机生成的,每一次提交表单都会生成不同的值。
-
在通过表单发送POST到服务器时,表单中包含了上面隐藏了
crsrmiddlewaretoken这个input项,服务端收到后,django 会验证这个请求的 cookie 里的 csrftoken 字段的值和提交的表单里的 csrfmiddlewaretoken 字段的值是否一样。如果一样,则表明这是一个合法的请求,否则,这个请求可能是来自于别人的 csrf 攻击,返回 403 Forbidden。 -
在通过 ajax 发送POST请求到服务器时,要求增加一个
x-csrftokenheader,其值为 cookie 里的 csrftoken 的值,服务湍收到后,django会验证这个请求的cookie里的csrftoken字段与ajax post消息头中的x-csrftoken header是否相同,如果相同,则表明是一个合法的请求。
在中间件的process_view方法中进行校验
基于 Django 使用 ajax 发送post请求时,都可以使用哪种方法携带 csrf token?
# 方式一: 给每个ajax都加上上请求头
function Do1(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
data:{csrfmiddlewaretoken:'{{ csrf_token }}',name:'alex'}
success:function(data){
console.log(data);
}
});
}
# 方式二:需要先下载jQuery-cookie,才能去cookie中获取token
function Do1(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
headers:{
'X-CSRFToken':$.cookie('csrftoken') // 去cookie中获取
},
success:function(data){
console.log(data);
}
});
}
方式三:搞个函数ajaxSetup,当有多的ajax请求,即会执行这个函数
$.ajaxSetup({
beforeSend:function (xhr,settings) {
xhr.setRequestHeader("X-CSRFToken",$.cookie('csrftoken'))
}
});
# 函数版本
Django如何实现 websocket
Django 可以通过 channel 实现 websocket。
Django 缓存
Django 中提供了6种缓存方式:
- 开发调试(不加缓存)
- 内存
- 文件
- 数据库
- Memcache 缓存(python-memcached模块)
- Memcache 缓存(pylibmc模块)
- 安装第三方组件支持 Redis:django-redis组件
设置缓存
# 全站缓存(中间件)
MIDDLEWARE_CLASSES = (
'django.middleware.cache.UpdateCacheMiddleware', # 第一
'django.middleware.common.CommonMiddleware',
'django.middleware.cache.FetchFromCacheMiddleware', # 最后
)
# 视图缓存
from django.views.decorators.cache import cache_page
import time
@cache_page(15) #超时时间为15秒
def index(request):
t=time.time() #获取当前时间
return render(request,"index.html",locals())
# 模板缓存
{\% load cache \%}
不缓存:-----{{ t }}
{\% cache 2 'name' %} # 存的key
缓存:-----:{{ t }}
{\% endcache %}
Django 的缓存能使用 Redis 吗?如果可以的话,如何配置
# 安装
# pip install django-redis
# apt-get install redis-serv
# 在 setting 添加配置文件
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache", # 缓存类型
"LOCATION": "127.0.0.1:6379", # ip端口
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient", #
"CONNECTION_POOL_KWARGS": {"max_connections": 100} # 连接池最大连接数
# "PASSWORD": "密码",
}
}
}
# 使用
from django.shortcuts import render,HttpResponse
from django_redis import get_redis_connection
def index(request):
# 根据名字去连接池中获取连接
conn = get_redis_connection("default")
conn.hset('n1','k1','v1') # 存数据
return HttpResponse('...')
Django 路由系统中 name 的作用
路由系统中 name 的作用:反向解析路由字符串。
- 路由:
url(r'^home', views.home, name='home') - 在模板中使用:
{% url 'home' %} - 在视图中使用:
reverse("home")
Django 的模板中 filter 和 simple_tag 的区别
filter: 类似管道,只能接受两个参数,第一个参数是|前的数据。simple_tag: 类似函数。
- 模板继承:
{% extends 'layouts.html' %} - 自定义方法
filter:只能传递两个参数,可以在if、for语句中使用。
simple_tag:可以无线传参,不能在if for中使用。
inclusion_tags:可以使用模板和后端数据。 - 防 xss 攻击:
|safe、mark_safe
django-debug-toolbar的作用?
- 查看访问的速度、数据库的行为、cache命中等信息。
- 尤其在 Mysql 访问等的分析上大有用处(sql查询速度)。
Django 中如何实现单元测试
对于每一个测试方法都会将setUp()和tearDown()方法执行一遍。
会单独新建一个测试数据库来进行数据库的操作方面的测试,默认在测试完成后销毁。
在测试方法中对数据库进行增删操作,最后都会被清除。也就是说,在test_add中插入的数据,在test_add测试结束后插入的数据会被清除。
Django单元测试时为了模拟生产环境,会修改settings中的变量,例如, 把DEBUG变量修改为True, 把ALLOWED_HOSTS修改为[*]。
Django 的 contenttype 组件的作用
contenttype 是 Django 的一个组件(app),它可以将 Django下所有app下的表记录下来。
可以使用他再加上表中的两个字段,实现一张表和N张表动态创建FK关系。
- 字段:表名称
- 字段:数据行ID
- 应用:一个策略表,同时关联不同的告警事件表
RESTful
谈谈你对 RESTful 规范的认识
https://blog.csdn.net/fenglepeng/article/details/104698864
RESTful 其实就是一套编写接口的’协议’,规定如何编写以及如何设置返回值、状态码等信息。
用 RESTful: 给用户一个url,根据method不同在后端做不同的处理。比如:post创建数据、get获取数据、put和patch修改数据、delete删除数据。
不用 RESTful: 给调用者很多url,每个url代表一个功能,比如:add_user/delte_user/edit_user/
规范:
- 使用HTTPS协议。
- 域名体现是API。
- 体现版本。'版本’来控制让程序有多个版本共存的情况,版本可以放在 url、请求头(accept/自定义)、GET参数。
- 路径,网络上任何东西都是资源,均使用名词表示(可复数)面向资源编程,RESTful 也可以称为“面向资源编程”。
- 根据method不同,进行不同操作。
- GET :从服务器取出资源(一项或多项)
- POST :在服务器新建一个资源
- PUT :在服务器更新资源(客户端提供改变后的完整资源)
- PATCH :在服务器更新资源(客户端提供改变的属性)
- DELETE :从服务器删除资源
- 通过在url上传参的形式传递搜索条件
- 响应式设置状态码
200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务) 204 NO CONTENT - [DELETE]:用户删除数据成功。 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功 - 状态码是4xx时,应返回错误信息,error当做key。
- 针对不同操作,服务器向用户返回的结果应该符合以下规范
GET /collection:返回资源对象的列表(数组) GET /collection/resource:返回单个资源对象;获取单条数据 POST /collection:返回新生成的资源对象;返回新增的数据 PUT /collection/resource:返回完整的资源对象;更新 PATCH /collection/resource:返回完整的资源对象;局部更新 - Hypermedia API: RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么。
接口的幂等性是什么意思
一个接口通过1次相同的访问,再对该接口进行N次相同的访问时,对资源不造影响就认为接口具有幂等性。
- GET # 第一次获取结果、第二次也是获取结果对资源都不会造成影响,幂等。
- POST # 第一次新增数据,第二次不会再次新增,幂等。
- PUT # 第一次更新数据,第二次不会再次更新,幂等。
- PATCH # 第一次更新数据,第二次不会再次更新,幂等。
- DELTE # 第一次删除数据,第二次不在再删除,幂等。
DRF(django rest framework)
为什么要使用django rest framework框架
在编写接口时可以不使用 django rest framework 框架。
- 不使用:也可以做,可以用django的CBV来实现,开发者编写的代码会更多一些。
- 使用:内部帮助我们提供了很多方便的组件,我们通过配置就可以完成相应操作。
django rest framework 框架中都有那些组件
#- 路由,自动帮助开发者快速为一个视图创建4个url
www.oldboyedu.com/api/v1/student/$
www.oldboyedu.com/api/v1/student(?P\w+)$
www.oldboyedu.com/api/v1/student/(?P\d+)/$
www.oldboyedu.com/api/v1/student/(?P\d+)(?P\w+)$
#- 版本处理
- 问题:版本都可以放在那里?
- url
- GET
- 请求头
#- 认证
- 问题:认证流程?
#- 权限
- 权限是否可以放在中间件中?以及为什么?
#- 访问频率的控制
匿名用户可以真正的防止?无法做到真正的访问频率控制,只能把小白拒之门外。
如果要封IP,使用防火墙来做。
登录用户可以通过用户名作为唯一标示进行控制,如果有人注册很多账号,则无法防止。
#- 视图
#- 解析器 ,获取用户请求数据request.data,根据Content-Type请求头对请求体中的数据格式进行处理。
#- 分页
#- 序列化,可以做用户请求数据校验+queryset对象的序列化
- 序列化
- source
- 定义方法
- 请求数据格式校验
#- 渲染器
django rest framework 框架中的视图都可以继承哪些类
a. 继承APIView(最原始)但定制性比较强
这个类属于rest framework中的顶层类,内部帮助我们实现了只是基本功能:认证、权限、频率控制,但凡是数据库、分页等操作都需要手动去完成,比较原始。
class GenericAPIView(APIView)
def post(...):
pass
b. 继承GenericViewSet(ViewSetMixin,generics.GenericAPIView)
首先他的路由发生变化:如果继承它之后,路由中的as_view需要填写对应关系
在内部也帮助我们提供了一些方便的方法:
get_queryset
get_object
get_serializer
get_serializer_class
get_serializer_context
filter_queryset
注意:要设置queryset字段,否则会抛出断言的异常。
代码
只提供增加功能,只继承GenericViewSet
class TestView(GenericViewSet):
serialazer_class = xxx
def creat(self,*args,**kwargs):
pass # 获取数据并对数据
c. 继承 modelviewset --> 快速快发
-ModelViewSet(增删改查全有+数据库操作)
-mixins.CreateModelMixin(只有增),GenericViewSet
-mixins.CreateModelMixin,DestroyModelMixin,GenericViewSet
对数据库和分页等操作不用我们在编写,只需要继承相关类即可。
示例:只提供增加功能
class TestView(mixins.CreateModelMixin,GenericViewSet):
serializer_class = XXXXXXX
***
modelviewset --> 快速开发,复杂点的genericview、apiview
简述 django rest framework 框架的认证流程
源码流程:请求进来先走dispatch方法,然后封装的 request对象会执行 user方法,由user触发authenticators认证流程。
如何编写类并实现authenticators?
认证需要编写一个类,类里面有一个authenticators方法,我们可以自定义这个方法,可以定制3类返回值。
- (user,auth),认证成功
- None, 匿名用户
- 异常,认证失败
django rest framework如何实现的用户访问频率控制 ★★★
# 对匿名用户,根据用户IP或代理IP作为标识进行记录,为每个用户在redis中建一个列表
{
throttle_1.1.1.1:[1526868876.497521,152686885.497521...],
throttle_1.1.1.2:[1526868876.497521,152686885.497521...],
throttle_1.1.1.3:[1526868876.497521,152686885.497521...],
}
每个用户再来访问时,需先去记录中剔除过期记录,再根据列表的长度判断是否可以继续访问。
如何封IP:在防火墙中进行设置
Flask
Flask 框架的优势
Flask自由、灵活、可扩展性强、透明可控、第三方库的选择面广、开发时可以结合最流行最强大的 Python 库。
Flask blueprint(蓝图)的作用
Flask blueprint 把实现不同功能的 module 分开。也就是把一个大的App分割成各自实现不同功能的module。
在一个blueprint中可以调用另一个blueprint的视图函数, 但要加相应的blueprint名。
列举使用的Flask第三方组件
- Flask组件
- flask-session session放在redis
- flask-SQLAlchemy 同 Django 的ORM操作
- flask-migrate 数据库迁移
- flask-script 自定义命令
- blinker 信号-触发信号
- 第三方组件
- Wtforms 快速创建前端标签、文本校验,和 Django 的 ModelForm 作用类似。
- dbutile 创建数据库连接池
- gevnet-websocket 实现websocket
- 自定义Flask组件
- 自定义auth认证,参考flask-login组件
Flask 框架依赖组件
- 依赖 jinja2 模板引擎。
- 依赖 werkzurg。
在 Flask 中实现 WebSocket 需要什么组件?
gevent-websocket
简述 Flask 上下文管理流程 ★★★
简单来说,Falsk 上下文管理可以分为三个阶段:
- 请求进来时:将请求相关的数据放入上下文管理中。
- 在视图函数中:要去上下文管理中取值。
- 请求响应:要将上下文管理中的数据清除。
详细点来说:
- 请求刚进来:
将 request、session 封装在 RequestContext 类中,app、g封装在 AppContext 类中。
并通过 LocalStack 将 RequestContext 和 AppContext 放入 Local 类中。 - 视图函数中:
通过 localproxy —> 偏函数 —> localstack —> local取值。 - 请求响应时:
先执行 save.session(),再各自执行pop(),将local中的数据清除。
Flask 中上下文管理主要涉及到了那些相关的类?并描述类主要作用?
- RequestContext # 封装进来的请求(赋值给ctx)
- AppContext # 封装
app_ctx - LocalStack # 将local对象中的数据维护成一个栈(先进后出)
- Local # 保存请求上下文对象和app上下文对象
Flask 默认 session 处理机制
不熟的话:记不太清了,应该是……分两个阶段吧。
-
创建:
当请求刚进来的时候,会将request和session封装成一个RequestContext()对象。
接下来把这个对象通过LocalStack()放入内部的一个Local()对象中。
因为刚开始 Local 的 ctx 中session是空的,所以,接着执行open_session,将 cookie 里面的值拿过来,重新赋值到ctx中(Local实现对数据隔离,类似threading.local) -
销毁:
最后返回时执行save_session()将 ctx 中的session读出来进行序列化,写到cookie然后给用户,接着把 ctx pop 掉。
Flask中的g的作用
g 是贯穿于一次请求的全局变量,当请求进来将 g 和 current_app 封装为一个 APPContext 类,再通过 LocalStack 将 Appcontext 放入Local中。
取值时通过偏函数在 LocalStack、local 中取值;响应时将local中的g数据删除。
在 Flask,g对象是专门用来存储用户数据的,它是global的缩写,g是全局变量,在整个request生命周期内生效。
g 保存的是当前请求的全局变量,不同的请求会有不同的全局变量,通过不同的 thread id 区别,像数据库配置这样重要的信息挂载在app对象上,一些用户相关的数据,就可以挂载在g对象上,这样就不需要在函数里一层层传递。
为什么 Flask 把 Local 对象中的的值 stack 维护成一个列表
因为通过维护成列表,可以实现一个栈的数据结构,进栈出栈时只取一个数据,巧妙的简化了问题。
还有,在多app应用时,可以实现数据隔离;列表里不会加数据,而是会生成一个新的列表。
local 是一个字典,字典里key(stack)是唯一标识,value是一个列表。
Flask中多app应用是怎么完成
请求进来时,可以根据URL的不同,交给不同的APP处理。蓝图也可以实现。
#app1 = Flask('app01')
#app2 = Flask('app02')
#@app1.route('/index')
#@app2.route('/index2')
源码中在DispatcherMiddleware类里调用app2.__call__,原理其实就是URL分割,然后将请求分发给指定的app。之后app也按单app的流程走。就是从app.__call__走。
解释 Flask 框架中的Local对象和threading.local对象的区别
-
Local对象:Local对象是根据threading.local做的,为每个 request 开辟一块空间进行数据存储。
-
threading.local:为每个线程开辟一块空间进行数据存储(数据隔离)。
问题:自己通过字典创建一个类似于threading.local的东西。
storage = {
4740: {val: 0},
4732: {val: 1},
4731: {val: 3},
}
class Local(object):
def __init__(self):
object.__setattr__(self, 'storage', {})
def __setattr__(self, k, v):
ident = get_ident()
if ident in self.storage:
self.storage[ident][k] = v
else:
self.storage[ident] = {k: v}
def __getattr__(self, k):
ident = get_ident()
return self.storage[ident][k]
obj = Local()
def task(arg):
obj.val = arg
obj.xxx = arg
print(obj.val)
for i in range(10):
t = Thread(target=task, args=(i,))
t.start()
Flask 中 blinker 是什么?
Flask 中的 blinker 是信号的意思,信号主要是让开发者可是在flask请求过程中定制一些行为。
或者说 Flask 在列表里面预留了几个空列表,在里面存东西。简言之,信号允许某个’发送者’通知’接收者’有事情发生了。
@before_request有返回值,blinker没有返回值
# 10个信号
request_started = _signals.signal('request-started') # 请求到来前执行
request_finished = _signals.signal('request-finished') # 请求结束后执行
before_render_template = _signals.signal('before-render-template') # 模板渲染前执行
template_rendered = _signals.signal('template-rendered') # 模板渲染后执行
got_request_exception = _signals.signal('got-request-exception') # 请求执行出现异常时执行
request_tearing_down = _signals.signal('request-tearing-down') # 请求执行完毕后自动执行(无论成功与否)
appcontext_tearing_down = _signals.signal('appcontext-tearing-down')# 请求上下文执行完毕后自动执行(无论成功与否)
appcontext_pushed = _signals.signal('appcontext-pushed') # 请求app上下文push时执行
appcontext_popped = _signals.signal('appcontext-popped') # 请求上下文pop时执行
message_flashed = _signals.signal('message-flashed') # 调用flask在其中添加数据时,自动触发
SQLAlchemy中的 session 和 scoped_session 的区别?
-
Session:
由于无法提供线程共享功能,开发时要给每个线程都创建自己的 session,打印 sesion 可知他是sqlalchemy.orm.session.Session的对象。 -
scoped_session
为每个线程都创建一个 session,实现支持线程安全,在整个程序运行的过程当中,只存在唯一的一个session对象。
创建方式:通过本地线程Threading.Local()session=scoped_session(Session)创建唯一标识的方法(参考flask请求源码)。
SQLAlchemy如何执行原生SQL?
# 使用execute方法直接操作SQL语句(导入create_engin、sessionmaker)
engine=create_engine('mysql://root:*****@127.0.0.1/database?charset=utf8')
DB_Session = sessionmaker(bind=engine)
session = DB_Session()
session.execute('alter table mytablename drop column mycolumn ;')
ORM的实现原理?
ORM的实现基于一下三点:
- 映射类:描述数据库表结构。
- 映射文件:指定数据库表和映射类之间的关系。
- 数据库配置文件:指定与数据库连接时需要的连接信息(数据库、登录用户名、密码or连接字符串)。
以下SQLAlchemy的字段是否正确?如果不正确请更正:
from datetime import datetime
from sqlalchemy.ext.declarative
import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
Base = declarative_base()
class UserInfo(Base):
__tablename__ = 'userinfo'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(64), unique=True)
ctime = Column(DateTime, default=datetime.now())
# 不正确:Ctime字段中参数应为’default=datetime.now’,now 后面不应该加括号,加了的话,字段不会实时更新。
SQLAchemy 中如何为表设置引擎和字符编码?
-
设置引擎编码方式为utf8。
engine = create_engine("mysql+pymysql://root:[email protected]:3306/sqldb01?charset=utf8") -
设置数据库表编码方式为utf8
class UserType(Base): __tablename__ = 'usertype' id = Column(Integer, primary_key=True) caption = Column(String(50), default='管理员') # 添加配置设置编码 __table_args__ = { 'mysql_charset':'utf8' }这样生成的SQL语句就自动设置数据表编码为utf8了,
__table_args__还可设置存储引擎、外键约束等等信息。
SQLAchemy中如何设置联合唯一索引
通过 UniqueConstraint 字段来设置联合唯一索引,例如__table_args=(UniqueConstraint('h_id','username',name='_h_username_uc')) h_id和username组成联合唯一约束。
Tornado
简述Tornado框架的特点。
异步非阻塞+websocket
简述Tornado框架中Future对象的作用?
实现异步非阻塞。
视图函数 yield 一个futrue对象,futrue对象默认:
self._done = False ,请求未完成
self._result = None ,请求完成后返回值,用于传递给回调函数使用。
tornado就会一直去检测futrue对象的_done是否已经变成True。
如果IO请求执行完毕,自动会调用future的set_result方法:
self._result = result
self._done = True
参考:http://www.cnblogs.com/wupeiqi/p/6536518.html(自定义异步非阻塞web框架)
Tornado框架中如何编写WebSocket程序
Tornado在websocket模块中提供了一个WebSocketHandler类。这个类提供了和已连接的客户端通信的WebSocket事件和方法的钩子。
当一个新的WebSocket连接打开时,open方法被调用,而on_message和on_close方法,分别在连接、接收到新的消息和客户端关闭时被调用。
此外,WebSocketHandler类还提供了write_message方法用于向客户端发送消息,close方法用于关闭连接。
Tornado中静态文件是如何处理的?
如:
# settings.py
settings = {
"static_path": os.path.join(os.path.dirname(__file__), "static"),
# 指定了静态文件的位置在当前目录中的"static"目录下
"cookie_secret": "61oETzKXQAGaYdkL5gEmGeJJFuYh7EQnp2XdTP1o/Vo=",
"login_url": "/login",
"xsrf_cookies": True,
}
经上面配置后
static_url()自动去配置的路径下找'commons.css'文件
Tornado操作MySQL使用的模块
torndb: torndb是基于mysqldb的再封装,所以使用时要先安装myqldb
Tornado操作redis使用的模块
tornado-redis
简述Tornado框架的适用场景
web聊天室,在线投票