《代码大全2》第12章 基本数据类型
目录
前言
12.1 数值概论
12.2 整数
12.3 浮点数
12.4 字符和字符串
12.5 布尔变量
12.6 枚举类型
12.7 具名常量
12.8 数组
12.9 创建你自己的类型(类型别名)
《Code_Complete_2》持续更新中......_@来杯咖啡的博客-CSDN博客这本书有意设计成使你既可以从头到尾阅读,也可以按主题阅读。1. 如果你想从头到尾阅读,那么你可以直接从第2章“用隐喻来更充分地理解软件开发”开始钻研。2. 如果你想学习特定的编程技巧,那么你可以从第6章“可以工作的类”开始,然后根据交叉引用的提示去寻找你感兴趣的主题。3. 如果你不确定哪种阅读方式更适合你,那么你可以从第3章3.2节“辦明你所从事的软件的类型”开始。.....................https://blog.csdn.net/qq_43783527/article/details/126275083
前言
基本数据类型是构建其他所有数据类型的构造块 (building blocks )。本章包含了使用数(普遍意义上)、整数、浮点数、字符和字符串、布尔变量、枚举类型、具名常量以及数组的一些技巧。本章的最后一节将讲述如何创建自己的数据类型。
12.1 数值概论
1、避免使用“神秘数值(magic number)” 。神秘数值是在程序中出现的、没有经过解释的数值文字量 (lHitertal numbers),如100 或者 47 、523。
2、如果需要,可以使用硬编码的0和1 。数值0和1用于增量、减量。
3、预防除零(devide-by-zero)错误 。每次使用除法符号的时候(在多数语言里是“/”),都要考虑表达式的分母是否有可能为0。如果这种可能性存在,就应该写代码防止除零错误的发生。
4、使类型转换变得明显。 确认当不同数据类型之间的转换发生时,阅读你代码的人会注意到这点。在C++里你可以使用
Y = x + (float) i;
这种实践还能帮助确认有关转换正是你期望发生的——不同的编译器会执行不同的转换,因此,如果不这么做,你就只有碰运气了。
5、避免混合类型的比较 。如果×是浮点数,i是整数,那么下面的测试
if(i=x) then…不能保证可行。在编译器设法弄清了应该用什么类型去进行比较之后,它会把其中一种类型转化为另一种,执行一些四舍五入运算之后才得出结果。要是在这样的情况下你的程序还能跑起来,那就是你的运气了。请自己动手进行类型转换,这样编译器就能比较两个相同类型的数值了,你也会确切地知道它比较的是什么。
6、注意编译器的警告 。很多程序员都曾被请去帮助别人解决某个讨厌的错误,结果却发现编译器一直都在对这个错误发出警告。杰出的程序员会修改他们的代码来消除所有的编译器警告。通过编译器警告来发现问题要比你自己找容易得多。
12.2 整数
在用整数的时候,要记住下面的注意事项。
检查整数除法。当你使用整数的时候,7/10 不等于0.7。它总是等于0,或者等于负无穷大,或者等于最接近的整数,或者——你应该懂了吧:其结果会随语言的不同而不同。这一说法对中间结果也同样适用。
- 在现实世界中 10*(7/10)= (10*7)/10=7。但在整数运算的世界里却不同。10*(7/10)等于0,因为整数除法(7/10)等于0。对此问题最简单的补救办法是重新安排表达式的顺序,以最后执行除法:(10*7)/10。
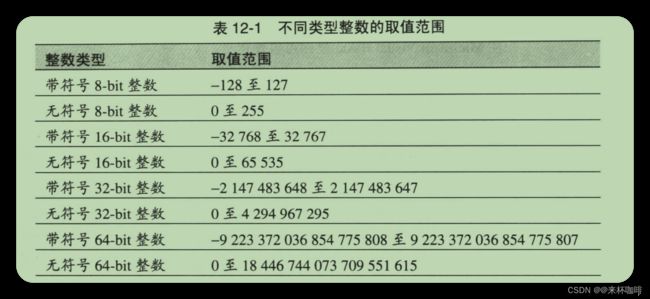
检查整数溢出。在做整数乘法或加法的时候,你要留心可能的最大整数。允许出现的最大无符号整数经常是(2的32次方)-1,有时候是(2的16次方)-1,即65535。当你把两个整数相乘,得出的数值大于整数的最大值时,就会出现问题。比如,如果你执行250*300,正确的答案是 75000。但如果最大的整数是 65 535,那么你得到的答案可能会是9464,因为发生了整数溢出(75 000 -65 536=9 464)。表12-1列出了常用整数类型的取值范围。
12.3 浮点数
使用浮点数字时主要考虑的是,很多十进制小数不能够精确地用数字计算机中的1和0来表示。
- 像 1/3 或者1/7 这样的无限循环小数通常只用 7位或者15位精度有效数字表示。
- 在我所用的 Microsoft Visual Basic 版本中,1/3的32 位浮点数表示形式为 0.33 333 330。它的精确度是小数点后7位。这对于大多数用途而言是足够精确的,但是有时它的不精确性也足以给你带来麻烦。
下面是一些在使用浮点数时应该遵循的指导原则。
1、避免数量级相差巨大的数之间的加减运算。
- 32 位浮点变量,1000 000.00 + 0.1可能会得到1000000.00,因为32 位不能给你足够的有效位数包容 1000 000 和0.1之间的数值区间。
- 与之类似,5000 000.02-5 000000.01 很可能会得到 0.0。
解决方案是什么?如果你必须要把一系列差异如此巨大的数相加,那么就先对这些数排序,然后从最小值开始把它们加起来。同样,如果你需要对无穷数列进行求和,那么就从最小的值开始——从本质上来说,是要做逆向的求和运算。这样做并不能消除舍入问题,但是能使这一问题的影响减少到最低限度。很多的算法书都建议采用这种处理方式。
2、避免等量判断。 很多应该相等的浮点数值并不一定相等。这里的根本问题是,用两种不同方法来求同一数值,结果不一定总得到同一个值。举例来说,10个0.1加起来很少会等于1.0。下面例子显示了应该相等但却不等的两个变量,nominal 和 sum。

正如你可能已经猜到的那样,这个程序的输出是:
Numbers are different.
按代码逐行运行,for 循环中的 sum 值是这样的:
0.1
0.2
0.30000000000000004
0.4
0.5
0.6
0.7
0.7999999999999999
0.8999999999999999
0.9999999999999999 因此,应该找一种代替对浮点数字执行等量判断的方案。一种有效的方法是先确定可接受的精确度范围,然后用布尔函数判断数值是否足够接近。通常应该写一个 Eguals() 函数,如果数值足够接近就返回 true,否则就返回 false。在Java 中,这样的函数类似下面这样:

如果修改了前面对浮点数做出错误比较的例子中的代码,改用上述函数来做比较,那么新的比较就会是:
if( Equals( Nominal, Sum ))..
使用了这样的比较方法后,程序的输出就会变成:
Numbers are the same.
3、处理舍入误差问题。 由于舍入误差而导致的错误与由于数字之间数量级相差太大而导致的错误并无二致。问题相同,解决的技术也相同。除此之外,下面列出一些专门用于解决舍入问题的常见方案。
- 换用一种精确度更高的变量类型。如果你正在用单精度浮点值,那么就换用双精度浮点值,同理类推。
- 换用二进制编码的十进制 (binary coded decimal, BCD)变量。BCD 模式的处理通常更慢一些,并且要占用更多的存储空间,但是它能防止很多舍入错误的发生。当你使用的变量代表的是美元、美分或者其他必须要精确结算的数量的时候,这种方法会特别有用。
- 把浮点变量变成整型变量。这是一种自力更生转到 BCD 变量的方法。你可能必须要用 64 位整数才能获得所需的精度。采用这种方法要求你自己来处理数字的小数部分。假设你原来是用浮点数处理美元,其中美分表示为美元的小数部分。这是一种常用的处理美元和美分的方式。当你转到用整数的时候,就必须要用整数来表示美分,用美分的 100 倍来表示美元。换句话说,你把美元乘以 100,并把美分保存到变量值中0到99 的范围内。这样做乍一看有点别扭,但是无论从速度还是精确度的角度来看,它都是一种有效的解决方案。你可以创建一个能够隐藏整数表示并且支持必要数字运算的DollarsAndcents 类,来简化这些操作。
4、检查语言和函数库对特定数据类型的支持。 有些语言,包括 Visual Basic 在内,包含了像 Currency 这样的数据类型,专用于处理对舍入误差敏感的数据。如果你的语言中内置了提供此类功能的数据类型,那么就用它!
12.4 字符和字符串
本节给出一些使用字符串的技巧。其中的第一条适用于所有的语言。
1、避免使用神秘字符和神秘字符串。 神秘字符(magic character)是指程序中随处可见的字面形式表示的字符 (literal character,例如‘A’);神秘字符串(magiestring)是指字面形式表示的字符串 (literal string,例如 “Gigamatic AccountingProgram”)。避免使用字面形式的字符串的众多原因如下:
- 对于程序的名字、命令名称、报表标题等常常出现的字符串,你有时可能需要修改它们的内容。例如,“Gigamatic Accounting Program” 可能会在一个新版本里改为 “New and Improved! Gigamatic Accouting Program”。
- 字符串的字面表示形式通常都会占用较多的存储空间。
- 字符和字符串的字面表示形式的含义是模糊的。注释或具名常量能够澄清你的意图。在下例中,0x1B的含义并不清楚。使用 ESCAPE 常量使得这一含义变得更加明显了。

2、避免 off-by-one 错误。 由于子字符串的下标索引方式几乎与数组相同,因此要避免因为读写操作超出了字符串末尾而导致的 off-by-one(偏差一)错误。
3、了解你的语言和开发环境是如何支持 Unicode 的 。在Java 等语言里,所有的字符串都是 Unicode 的。在C 和 C++等其他的语言里,处理 Unicode 就要用到与之相关的一组函数。为了标准函数库与第三方函数库之间的通信,常常需要在Unicode 和其他的字符集之间进行转换。如果有些字符串不需要表示成 Unicode(例如,在C或 C++中),就要尽早决定是否采用 Unicode 字符集。如果你决定要用Unicode 字符串,就要决定何处以及何时使用它。
4、在程序生命期中尽早决定国际化/本地化策略 。与国际化和本地化相关的事项都是很重要的问题。关键的考虑事项包括:决定是否把所有字符串保存在外部资源里,是否为每一种语言创建单独的版本,或者在运行时确定特定的界面语言。
如果你知道只需要支持一种文字的语言,请考虑使用 ISO 8859 字符集 对于只需要支持单一文字(例如英语)、无须支持多语言或者某种表意语言(例如汉语)的应用程序,可以使用 ISO 8859 扩展 ASCII 类型标准来很好地替代 Unicode。
5、如果你需要支持多种语言,请使用 Unicode 。与ISO 8859 或者其他标准相比,Unicode 对国际字符集提供了更为全面的支持。
6、采用某种一致的字符串类型转换策略。 如果你使用了多种字符串类型,有一种常用方法能维护各种字符串类型,那就是在程序中把所有字符串都保存为一种格式,同时在尽可能靠近输入和输出操作的位置把字符串转换为其他格式。
12.5 布尔变量
要把逻辑变量或者布尔变量用错是非常困难的,而更仔细地运用它会让你的程序变得更清晰。
用布尔变量对程序加以文档说明。 不同于仅仅判断一个布尔表达式,你可以把这种表达式的结果赋给一个变量,从而使得这一判断的含义变得明显。例如,在下面的代码片断中,if检查的对象到底是工作完成、错误条件还是其他什么,情况很不明确:
用布尔变量来简化复杂的判断。 常有这样的情况,在需要编写一段复杂的判断时,你要尝试好几次才能成功。在你事后想要修改这一判断的时候,首先弄清楚这段判断在做什么就已经很困难了。逻辑变量可以简化这种判断。在前述示例中,程序事实上需要判断两个条件:子程序是否已经结束,以及子程序是否在重复的记录上工作。通过创建 finished 和 repeatedEntry 两个布尔变量,迁的判断得到了简化:读起来很容易,更不容易出错,修改起来也更加方便了。
下面再举一个复杂判断的例子:

本例中的判断相当复杂,但是这种情况并不罕见。它给读者很重的思维负担。我猜你甚至不会去试着理解 if 判断的含义,而是看着它说,“要是需要的话,我会以后再去弄清楚。”请注意这种想法,因为这就是别人阅读你所写的含有类似判断语句代码时的真切反应。下面是重写的代码,增加了布尔变量以简化判断:

12.6 枚举类型
枚举类型是一种允许用英语来描述某一类对象中每一个成员的数据类型。下面给出一些如何使用枚举类型的指导原则:
1、用枚举类型来提高可读性。 与下面这个语句相比
if chosenColor = 1
你可以通过下面这样的语句来提高可读性
if chosenColor = Color_Red;
每当你看到字面形式数字的时候,就应该问问自己,把它换成枚举类型是不是更合理。
2、枚举类型特别适用于定义子程序参数。
3、用枚举类型来提高可靠性 。对于少数语言而言(尤其是 Ada),枚举类型会使编译器执行比整数和常量更为彻底的类型检查。
- 如果采用具名常量,编译器将无法知道仅有 Color_Red, Color_Green 和 Color_Blue 是合法的值。编译器不会反对像 color = Country_England 或者 country = Output_Printer 这样的语句。
- 但如果你用了枚举类型,把一个变量声明为 Color,编译器就会只允许把该变量赋值为 Color_Red, Color_Green 或 Color_Blue。
4、用枚举类型来简化修改。 枚举类型使得你的代码更容易修改。如果你在“1代表红色,2代表绿色,3代表蓝色”方案中发现了一处缺陷,你就必须从头到尾检查代码,并且修改所有的1、2、3等。如果用的是枚举类型,你就可以继续向列表增加元素,只要把它们加入类型定义后重新编译就可以了。
5、将枚举类型作为布尔变量的替换方案。 布尔变量往往无法充分表达它所需要表达的含义。
- 举例而言,假设你有一个子程序在成功地完成任务之后返回 true,否则返回 false。后来你可能发现事实上有两种 false。
- 第一种表示任务失败了,并且其影响只局部于子程序自身;
- 第二种表示任务失败了,而且产生了一个致命错误,需要把它传播到程序的其余部分。
在这种情况下,一个包含Status_Success、 Status_Warning 和 Status_FatalError 值的枚举类型,就比一个包含 true 和 false 的布尔类型更有用。如果成功和失败的具体类型有所增加,对其进行扩展以区分这些情况也是非常容易的。
6、检查非法数值。 在 if或者 case 语句中测试枚举类型时,务必记得检查非法值。在 case 语句中用 else 子句捕捉非法值:

7、定义出枚举的第一项和最后一项,以便用于循环边界。 把枚举的第一个和最后一个元素定义成 Color_First, Color_Last, Country_First, Country-Last等,以使你更方便地写出能遍历所有枚举元素的循环来。你可以用明确的数值来定义该枚举类型,如下所示:

8、把枚举类型的第一个元素留做非法值。 在你声明枚举类型的时候,把第一个值保留为非法值,很多编译器会把枚举类型中的第一个元素赋值为0。把映射到0的那个元素声明为无效会有助于捕捉那些没有合理初始化的变量,因为这些变量值更有可能为0,而不是其他的非法值。
下面就是采用了这种方法后的Country声明:

9、明确定义项目代码编写标准中第一个和最后一个元素的使用规则,并且在使用时保持一致。 在枚举中使用 Invaliarirst, Pirst 和 Last 元素,能使数组声明和循环更具有可读性。但是这样做也可能会造成混乱,究竟枚举中的合法项是从0开始还是从1 开始的?枚举中的第一个和最后一个元素合法吗?如果使用这种技术,项目的编码标准中就应该要求在所有的枚举中都统一使用Invalidrirst、 First、 Last,以减少出错。
10、警惕给枚举元素明确赋值而帶来的失误。 有些语言允许对枚举里面的各项元素明确地赋值,如下面这个 C++例子所示:

在这个例子中,如果你把一个循环的下标声明为 Color 类型,并且尝试去適历所有的 Color,那么你在遍历1,2,4,8这些合法地也会遍历3,5,6,7这些非法数值。
12.7 具名常量
具名常量很像变量,一旦赋值以后就不能再修改了。具名常量允许你用一个名字而不是数字——比如说 MAXIMUM_EMPLOYEES 而不是1000—来表示固定的量,比如员工人数的最大值。
使用具名常量是一种将程序“参数化”的方法--把程序中可能变化的一个方面写为一个参数,当需要对其修改时,只改动一处就可以了,而不必在程序中到处改动。
12.8 数组
确认所有的数组下标都没有超出数组的边界。在任何情况下,与数组有关的所有问题都源于一个事实:数组里的元素可以随机访问。最常见的问题就是程序试图用超出数组边界的下标去访问数组元素。在有些语言里,这种情况会产生一个错误;在其他语言里,这样做会产生一个奇怪的不可预料的结果。
考虑用容器来取代数组,或者将数组作为顺序化结构来处理 。计算机科学界的一些最聪明的人士建议永远不要随机地访问数组,只能顺序地访问 (Mills andLinger 1986)。他们建议使用集合、栈和队列等按顺序存取元素的数据结构来取代数组。
- 在一项小型试验里,Mills 和 Linger 发现按照这种方法所创建的设计中只需要更少的变量和变量引用。相对而言,这样做设计的工作效率较高,能产生高度可靠的软件。在你习惯性地选用数组之前,考虑能否用其他可以顺序访问数据的容器类作为替换方案--如集合、栈、队列等。
检查数组的边界点 。 正如考虑循环结构的边界是非常有用的一样,你可以通过检查数组的边界点来捕获很多错误。问问自己,代码有没有正确地访问数组的第一个元素?还是错误地去访问了第一个元素之前或者之后的那个元素?而后一个元素呢?代码会导致 off-by-one 的错误吗?最后,问问你自己代码有没有正确地访问数组中间的元素。
如果数组是多维的,确认下标的使用顺序是正确的。 很容易把 Array[i][j]写成 Arrayt[j][i],所以请花些时间检查下标的顺序是否正确。与其用i和j这类不明不白的东西,不如去考虑更有意义的名字。
12.9 创建你自己的类型(类型别名)
略。