Kaggle TOP1:神奇的时序Trick直接炸榜


本文字数:2971字
预计阅读时间:18分钟
作者介绍
王明杰,北京师范大学珠海校区研究助理。2021年搜狐校园文本匹配算法大赛第二名获得者,曾在Kaggle、天池等国际算法大赛获得优异成绩:
• Kaggle Jane Street Market Prediction TOP1
• Kaggle Mechanisms of Action (MoA) Prediction 银牌
• Kaggle SIIM-ISIC Melanoma Classification 银牌
本篇文章是明杰同学参加Kaggle Jane Street Market Predictio的竞赛总结,希望通过此次技术分享为各位同学提供些许算法思路,并在其他竞赛中取得更好成绩:)
#1
今天的贸易系统在很大程度上依赖于技术的运用。市场每天都在运作,为了在这种动态的市场中生存下去,我们需要使用所有有用的东西。机器学习模型就是一个十分出色的选择。因为它非常善于理解模式和预测,并且随着技术的发展,机器学习在市场价格预测中的应用越来越多。结合机器学习模型和人类知识可以做到十分出色的市场预测。
#2
在Kaggle Jane Street Market Prediction里,我们需要使用来自全球主要的证券交易所的市场数据构建量化交易模型,并且在真实的未来数据上测试我们的模型性能。
该数据集包含一组匿名特征feature_{0...129},对于数据与标签我们都不知道它们代表了什么含义。我们只知道,它们代表真实的股票市场数据。
数据集中的每一行代表一个交易,我们将为其预测一个action值:1 表示进行交易,0 表示不进行交易。每笔交易都有一个关联的weight和resp,它们组合在一起代表了交易的回报率。该date列是一个整数,代表交易日。
#3
比赛的metrics为Utility Score:
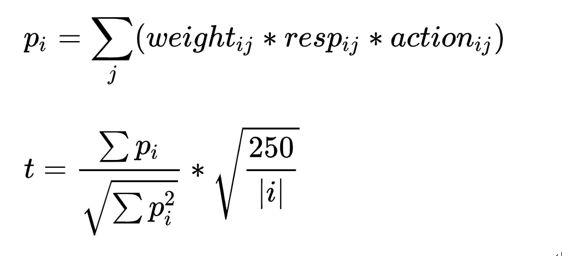
Pi代表了每一天的收入;
weight是购买stock的数量;
resp是 未来交易时的价格浮动;
action 则代表是否进行这次交易。
值得注意的是,比赛中存在很严重的过拟合公榜的现象,很多人发布了针对公榜调参的模型。最终在私榜上的抖动还是比较严重的,但是可以发现公榜和私榜存在线性相关。
简单数据格式如下:

这是我们队伍最终获得的成绩:

本文不着重于代码部分,如果想参考代码部分,请移步这里:
https://www.kaggle.com/xiaowangiiiii/current-1th-jane-street-ae-mlp-xgb
我们的最终模型:XGB+MLP的组合
MLP部分:
监督式自动编码器的方法最初是在这里https://www.kaggle.com/aimind/bottleneck-encoder-mlp-keras-tuner-8601c5提出的,其中一个监督式自动编码器在交叉验证 (CV) 拆分之前单独训练。但这种方法会引起一定程度的泄露,由于在最开始的时候编码器已经看到了全部的数据。所以需要在每个CV中单独训练一个自动编码器来减少泄漏。
交叉验证 (CV) 策略和特征工程:
5 折 purged group time-series 进行交叉验证
删除前 85 天进行培训(极度抖动且CV与LB都会下降)
前向填充缺失值(防止泄露)
将所有 resp 目标(resp、resp_1、resp_2、resp_3、resp_4)转移到用于多标签分类的action
在推理过程中,我们使用了resp_3与平均值作为最终概率。详情见下节。
MLP模型:
使用自动编码器创建新功能,将原始功能添加到 MLP
在每个 CV split 中一起训练自动编码器和MLP以减少泄漏
将Target添加到自动编码器(监督学习)以强制其生成更多相关特征。
在编码器之前添加高斯噪声层以进行数据增强并防止过度拟合
使用 Swish 激活函数代替 ReLU 来防止“死神经元”并平滑梯度
Batch Normalisation和 Dropout 用于 MLP
用3个不同的随机种子训练模型并取平均值以减少预测方差
仅使用在最近两次 CV 拆分中训练的模型(具有不同种子),因为它们已经看到了更多数据
仅监控 MLP 的 BCE 损失,而不是提前停止的整体损失。
使用 Hyperopt 寻找最优超参数集
对于XGB模型,这里不再赘述。
之所以我们最终能取得一些非常高的分数,是因为我们针对于最终的Target发现了一些特殊的地方。简单来说:
官方在数据中提供了5组收益指标,分别是 resp_1, resp_2, resp_3, resp_4 和 resp. 我们的最终受益是按照resp的值计算的。
根据 resp_1,resp_2 交易所取得的收益更加稳定,t值高
根据 resp_3 交易所取得的收益有较高的t值,p值也往往高
根据 resp, resp_4 交易可能取得很高的p值,但是t值往往很低
从以上结论我们发现了,利用resp_3,我们可以得到既稳定,又有高收益的模型,也就是说如果我们在预测和训练的时候直接使用resp_3,很可能得到比用resp预测更高的收益!
原因是因为比赛的指标Utility Score:
与收入不同,utility score 还考察了模型收益的稳定性,即模型的最大回撤不能过大,不然的话就不是好模型,最终的 utility score 也会相对较低。可以看出:如果有某一天的收入为负的话,t 计算公式里的分母会变小,分子会变大,utility score 也会被惩罚得非常低。
另一个可以看出的要点是,在 t 值大于6的时候,总收入决定了u值的大小。
其他的一些实验结论
缺失值
如果训练时使用了多目标,取均值和众数取得的收益其实是差不多的,但是对于某些特殊情况,均值或者众数往往有奇效。鉴于这里的严重不确定性,我们没有在这里做过多的研究。
最佳的交易阈值
线下经过实验得到的结论是 0.51~0.52 之间的阈值可以带来更高的收益,最后的提交的模型中有一个是用0.51作为阈值。
最终模型
比赛的数据是匿名特征(130列),特征工程不是完全无用,但是往往会吃力不讨好。为了保持解决方案的简洁性,最后提交的模型没有加入特征工程。
实际上有一些特征工程可以在线下取得分数的提升,但是加入线上模型会降低分数,我们这里希望只保留线上线下都有提升的强结论。
读到这里的读者可能会发现,我们并没有用什么特别复杂的方法。实际上我们的大部分的精力都花在了观察数据和模型的表现上,复杂的模型或者方法也尝试过,但是往往效果不好,线上线下不一致,或者并没有显著性。我们一致认为最终获胜的模型可能并不是那么复杂。
我们最终模型是 AE+MLP + XGBOOST(100 round), 每种模型各针对三个种子进行了训练。截至2021-07-06。我们目前的成绩是TOP1。
参考资料
1.https://zhuanlan.zhihu.com/p/355606168
2.https://www.kaggle.com/c/jane-street-market-prediction/discussion/224348
3.https://www.kaggle.com/xiaowangiiiii/current-1th-jane-street-ae-mlp-xgb
4.https://www.kaggle.com/christoffer/rough-estimate-of-resp-i-timeframes
5.https://www.kaggle.com/aimind/bottleneck-encoder-mlp-keras-tuner-8601c5


也许你还想看
(▼点击文章标题或封面查看)
Swift的一次函数式之旅
2021-04-08

包教包会:设计一套完整日志系统
2021-05-20

正经分析iOS包大小优化
2021-05-27

从YYModel源码分析JSON解析原理
2021-06-03

【文末有惊喜!】iOS日历攻略:提醒调休并过滤法定节假日
2021-06-24
