MySQL MHA高可用架构官方文档全文翻译
目录
- MHA项目官方github地址
- 关于MHA
-
- 概述
-
- 主故障切换的难点
- 现有的解决方案和问题
- MHA的架构
- MHA的优势
- 使用案例
- 其他高可用解决方案和问题
-
- 纯手动解决
- 单主单从
- 一个主节点、一个备选主节点、众多从节点
- 起搏器和DRBD
- Mysql集群
- 半同步复制
- 全局事件ID(GTID ,Global Transaction ID)
- MHA架构
-
- MHA组件
- MHA的优势
-
- 主节点故障转移和从节点升级可以非常快速地完成
- 主节点崩溃不会导致数据不一致
- 无需修改当前MySQL配置
- 无需添加额外服务器
- 没有性能损失
- 适用于任何存储引擎
- 使用案例
-
- 在哪能部署manager
- 多副本配置
- 三层副本,多主节点
- 管理主节点IP地址
- 使用半同步复制
- 准备开始
-
- 指南
-
- 简单的故障转移
- 安装
-
- 下载MHA Node和MHA Manager
- 安装MHA node节点
- 安装MHA Manager
- 配置
-
- 编写一个应用配置文件
- 编写一个全局配置文件
- Binlog 服务器
- 依赖和限制
-
- SSH公钥认证
- 操作系统
- 单个可写主设备和多个从设备或只读主设备
- 管理3层或多层副本环境
- MySQL 5.0或更高版本
- 为MySQL 5.1+使用mysqlbinlog 5.1+
- 备选主节点上必须激活log-bin
- 所有服务器上的二进制日志和中继日志筛选规则必须相同
- 备选主机上必须存在副本用户
- 保存中继日志并定期清除
- 定时运行purge_relay_logs脚本
- 不要将LOAD DATA INFILE与基于二进制日志记录的语句一起使用
- 基于GTID的故障转移
MHA项目官方github地址
项目代码地址:
https://github.com/yoshinorim/mha4mysql-manager
https://github.com/yoshinorim/mha4mysql-node
官方文档地址:
https://github.com/yoshinorim/mha4mysql-manager/wiki
官方文档最后一次编辑于2016年1月27日。是个老项目了,接下来开始翻译。
bmildren edited this page on 27 Jan 2016 · 4 revisions
关于MHA
概述
MHA以最短的停机时间(通常在10-30秒内)自动执行主设备故障转移和从设备升级。MHA防止了复制一致性问题,并节省了必须购买额外服务器的费用。所有这些都不会降低性能,没有复杂性(易于安装),并且不需要对现有部署进行任何更改。MHA还提供计划的在线主机切换,在停机时间(仅阻止写入)的几秒钟(0.5-2秒)内,安全地将当前运行的主机更改为新的主机。MHA提供以下功能,在许多需要高可用性、数据完整性和几乎不间断的主维护的部署中非常有用。
- 自动化的主监控和故障转移
MHA可以监控现有复制环境中的MySQL主服务器,在检测到主服务器故障时执行自动主服务器故障转移。MHA通过识别来自最新从设备的差分中继日志事件并将其应用于所有其他从设备(包括仍未接收到最新中继日志事件的那些从设备)来保证所有从设备的一致性。MHA通常可以在几秒钟内执行故障转移:9-12秒检测主机故障,可选地7-10秒关闭主机以避免裂脑,几秒钟将差分中继日志应用于新主机。总停机时间通常为10-30秒。在配置文件中,可以将特定的从机指定为候选主机(设置优先级)。由于MHA在从服务器之间保持一致性,因此任何从服务器都可以升级为新的主服务器。通常会导致突然复制失败的一致性问题将不会发生。 - 交互式(手动启动)主故障转移。
可以将MHA配置为手动启动(非自动)交互式故障转移,而无需监控主设备。 - 非交互式主故障转移。
还支持无需监控主服务器的非交互式自动主服务器故障转移。当MySQL主软件监控已在使用中时,此功能尤其有用。例如,您可以使用Pacemaker(Heartbeat)来检测主设备故障和虚拟IP地址接管,同时使用MHA来检测主设备故障转移和从设备升级。 - 联机将主服务器切换到其他主机。
通常需要将现有的主服务器迁移到另一台计算机上,例如当前的主服务器存在硬件RAID控制器或RAM问题,或者您想用速度更快的计算机替换它,等等。这不是主崩溃,但需要进行定期的主维护。计划的主机维护应尽快完成,因为它需要部分停机时间(禁用主机写入)。另一方面,您应该非常小心地阻止/终止当前正在运行的会话,因为可能会出现不同主机之间的一致性问题(即“更新主机1,更新主机2,提交主机1,提交主机2时出错”将导致数据不一致)。快速主切换和平滑阻塞写入都是必需的。MHA在写入器阻塞的0.5-2秒内提供优雅的主切换。0.5-2秒的写入器停机时间通常是可以接受的,因此您甚至可以在不分配计划维护窗口的情况下切换主机。升级到更高版本、更快机器等操作。变得容易多了。
主故障切换的难点
主故障转移并不像看起来那么简单。以最典型的MySQL部署案例为例,即一个主服务器有多个从服务器。如果主服务器崩溃,您需要选择一个最新的从服务器,将其提升到新的主服务器,并让其他从服务器从新的主服务器开始复制。这其实不是小事。即使可以识别最新的从属服务器,其他从属服务器也可能尚未接收到其所有二进制日志事件。如果在复制开始时连接到新的主服务器,则这些从服务器将丢失事务。这将导致一致性问题。为了避免这些一致性问题,丢失的binlog事件(尚未到达所有从服务器)需要被识别并依次应用于每个从服务器,然后才能在新的(升级的)主服务器上启动复制。此操作可能非常复杂,并且很难手动执行。我在MySQL会议和Expo 2011上的演讲幻灯片中说明了这一点(特别是在下面的第10页)。

如上图,是什么让主故障转移变得困难?
目前,大多数MySQL复制用户别无选择,只能在主服务器崩溃时手动执行故障转移。一个或多个小时的停机时间对于完成故障转移并不罕见。很可能不是所有的从属服务器都接收到相同的中继日志事件,从而导致稍后必须纠正的一致性问题。尽管主崩溃很少发生,但发生时可能会非常痛苦。MHA的目标是在没有任何被动(备用)机器的情况下,尽可能快地完全自动化主故障转移和恢复过程。恢复包括确定新的主设备、识别从设备之间的差分中继日志事件、将必要的事件应用于新的主设备、同步其他从设备并使它们从新的主设备开始复制。根据复制延迟,MHA通常可以在10-30秒的停机时间内进行故障转移(10秒用于检测主机故障,可选地7-10秒用于关闭主机以避免裂脑,几秒或更长时间用于恢复)。MHA提供自动和手动故障转移命令。自动故障转移命令“masterha_manager(MHA Manager)”由主监控和主故障转移组成。MASTERHA_MANAGER永久监视主服务器的可用性。如果MHA Manager无法访问主服务器,它将自动启动非交互式故障转移过程。手动故障转移命令“MASTERHA_MASTER_SWITCH”最初会检查主服务器是否确实处于死机状态。如果主服务器确实是死的,则masterha_master_switch选择其中一个从服务器作为新的主服务器(您可以选择首选的主服务器),并启动恢复和故障转移。在内部,它可以执行更多操作,但您只需执行一个命令,而不必自己执行复杂的主恢复和故障转移操作。
现有的解决方案和问题
有关详细信息,请参阅Other_HA_Solutions页面。
MHA的架构
架构相关的详细信息,请参见体系结构页面。
MHA的优势
有关详细信息,请参阅优势页面。
使用案例
有关详细信息,请参见用例页面。
其他高可用解决方案和问题
纯手动解决
MySQL复制是异步或半同步的。当主服务器崩溃时,可能某些从服务器没有收到最新的中继日志事件,这意味着每个从服务器可能处于彼此不同的状态。手动修复一致性问题并非易事。但如果不修复一致性问题,复制可能无法启动(即重复键错误)。手动重新启动复制需要一个多小时的情况并不少见。
单主单从
如果你只有一个master主节点,并只有一个slave从节点,“一些从节点在最新的从节点后面”的情况永远不会发生。当主服务器崩溃时,只需让应用程序将所有流量发送到新的主服务器。所以故障转移很容易。

但有很多非常严重的问题。首先,您不能向外扩展读取流量。在许多情况下,您可能希望在其中一个从属服务器上运行昂贵的操作,如备份、分析查询、批处理作业。这可能会导致从属服务器出现性能问题。如果您只有一个从属服务器,并且从属服务器崩溃,则主服务器必须处理所有此类流量。第二个问题是可用性。如果主服务器崩溃,则只剩下一台服务器(新的主服务器),因此它将成为单点故障。要创建新的从属服务器,您需要进行在线备份,在新硬件上恢复它,然后立即启动从属服务器。但这些操作通常总共需要数小时(甚至超过一天才能完全赶上复制)。在某些关键应用程序上,您可能无法接受数据库在如此长的时间内成为单点故障。在主服务器上进行在线备份会显著增加I/O负载,因此在高峰时段进行备份是很危险的。第三个问题是缺乏可扩展性。例如,当您想在远程数据中心创建一个只读数据库时,您至少需要两个slave,一个是本地数据中心的slave,另一个是远程数据中心的slave。如果您只有一个从属服务器,则无法构建此体系结构。在许多情况下,单个slave实际上是不够的。
一个主节点、一个备选主节点、众多从节点
使用“一个主设备、一个候选主设备和多个从设备”的体系结构也很常见。如果当前主服务器崩溃,则候选主服务器是新主服务器的主要目标。在某些情况下,它被配置为只读主机:多主机配置。

但这并不总是作为主故障转移解决方案。一旦当前主服务器崩溃时,其余从服务器可能没有接收到所有中继日志事件,因此与其他解决方案一样,仍然需要修复从服务器之间的一致性问题。如果您无法接受一致性问题,但希望立即启动服务,该怎么办?只需将候选主机作为新主机启动,并删除所有其他从属服务器。之后,您可以通过从新的主服务器获取联机备份来创建新的从属服务器。但是这种方法与上面的“单主单从”方法具有相同的问题。所有的从机不能用于读取缩放或冗余目的。这种体系结构应用相当广泛,但没有多少人完全理解上述潜在问题。一旦当前主服务器崩溃时,从服务器变得不一致,或者如果您只是让从服务器从新的主服务器开始复制,您甚至无法开始复制。如果你需要保证一致性,剩下的slave从节点就不能用了。这两种方法都有严重的缺点。顺便说一下,“使用两个主服务器(一个是只读的)并且每个主服务器至少有一个从服务器(如下所示)”也是可能的。

一旦当前的主服务器崩溃时,至少有一个从服务器可以继续复制,但实际上采用这种架构的用户并不多。最大的缺点是复杂性。此体系结构中使用了三层复制(M->M2->S2)。但是管理三层复制并不容易。例如,如果中间服务器(M2:候选主服务器)崩溃,则第三层从服务器(S2)无法继续复制。在许多情况下,您必须再次设置M2和S2。同样重要的是,在此体系结构中至少需要四台服务器。
起搏器和DRBD
使用起搏器(Heartbeat)+DRBD+MySQL是一种非常常见的HA解决方案。但这个解决方案也有一些严重的问题。
一个问题是成本,特别是如果您想运行大量的MySQL复制环境。起搏器+DRBD是活动/备用解决方案,因此您需要一个不处理任何应用程序流量的被动主服务器。被动服务器不能用于读取缩放。通常,您需要至少四个MySQL服务器,一个主动主服务器,一个被动主服务器,两个从服务器(其中一个用于报告等)。
第二个问题是停机时间。由于起搏器+DRBD是活动/备用集群,因此如果活动服务器崩溃,则在被动服务器上进行崩溃恢复。这可能需要很长时间,特别是如果您没有使用InnoDB引擎。即使您使用InnoDB引擎,花费几分钟或更长时间来开始接受备用服务器上的连接也并不罕见。除了崩溃恢复时间外,故障转移后的预热(将数据填充到缓冲池中)也需要很长时间,因为被动服务器上的数据库/文件系统缓存是空的。实际上,您需要一个或多个额外的从服务器来处理足够的读取流量。同样重要的是,在预热期间,由于缓存为空,写入性能也会显著下降。
第三个问题是写入性能下降或一致性问题。要使主动/被动HA集群真正发挥作用,您必须在每次提交时将事务日志(二进制日志和InnoDB日志)刷新到磁盘。也就是说,您必须设置innodb-flush-log-at-TRX-commit=1和sync-binlog=1。但目前sync-binlog=1会降低写入性能,因为fsync()在当前MySQL中被序列化(如果sync-binlog为1,则会中断组提交)。在大多数情况下,人们不会设置sync-binlog=1。但是,如果未设置sync-binlog=1,则当主动主服务器崩溃时,新的主服务器(之前的被动服务器)可能会丢失一些已经发送到从服务器的二进制日志事件。假设主服务器崩溃,从服务器A接收到mysqld-bin.000123位置1500。如果binlog数据仅刷新到位置1000的磁盘,则新的主服务器仅具有位置1000的mysqld-bin.000123,并在启动时创建新的二进制日志mysqld-bin.000124。如果发生这种情况,从服务器A无法继续复制,因为新的主服务器没有MYSQLD-BIN.000123位置1500。
第四个问题是复杂性。对于许多用户来说,安装/配置起搏器和DRBD(尤其是DRBD)并不是一件小事。在许多部署中,配置DRBD通常需要重新创建操作系统分区,这在许多情况下并不容易。您还需要对DRBD和Linux内核层有足够的专业知识。如果执行错误的命令(即在被动节点上执行drbdadm—overwrite-data-of-peer primary),则很容易破坏实时数据。同样重要的是,一旦在使用DRBD时发生磁盘I/O层问题,对于大多数DBA来说,修复该问题非常困难。
Mysql集群
MySQL集群是真正的高可用性解决方案,但您必须使用NDB存储引擎。当你使用InnoDB时(在大多数情况下),你不能利用MySQL集群的优势。
半同步复制
半同步复制极大地降低了“binlog事件仅存在于崩溃的主服务器上”的风险。这对于避免数据丢失非常有帮助。但半同步复制并不能解决所有的一致性问题。半同步复制保证至少有一个(不是全部)从站在提交时从主站接收binlog事件。仍有可能某些Slave尚未收到所有binlog事件。如果不将差动继电器日志事件从最近的从设备应用到非最近的从设备,则从设备不能彼此一致。MHA解决了这些一致性问题,因此通过同时使用半同步复制和MHA,可以同时实现“几乎没有数据丢失”和“从一致性”。
全局事件ID(GTID ,Global Transaction ID)
全局事务ID的目的与MHA试图实现的目的基本相同,但它涵盖了更多内容。MHA仅适用于两层复制,但全局事务ID涵盖任何层复制环境,因此即使第二层从属服务器发生故障,您也可以恢复第三层从属服务器。有关详细信息,请查看Google的全球交易ID项目。
从MySQL 5.6开始,支持GTID。Oracle的官方工具MySQLFailover支持使用GTID进行主故障转移。从MHA版本0.56开始,MHA还支持基于GTID的故障转移。MHA自动检测mysqld是否与GTID一起运行,如果启用了GTID,MHA将与GTID一起执行故障转移。如果没有,MHA将使用中继日志执行传统的故障转移。
MHA架构
当主节点崩溃了,MHA就会像下图这样,恢复剩下的从节点。

上图是故障恢复步骤
在2011年MySQL会议和博览会上展示的幻灯片中描述了基本算法,特别是从第13页到第34页。
在从节点上的中继日志文件中,主节点的二进制日志位置写在“end_log_pos”部分(示例)。通过比较从节点之间最新的END_LOG_POS,我们可以确定哪些中继日志事件没有发送到每个从节点。MHA通过使用此机制在内部恢复从属服务器(修复一致性问题)。除了MySQL Conf 2011幻灯片中介绍的基本算法外,MHA还进行了一些优化和增强,例如快速生成差分中继日志(独立于中继日志文件大小),使用基于行的格式进行恢复等。
MHA组件
MHA中组成manager和node的组件如下:
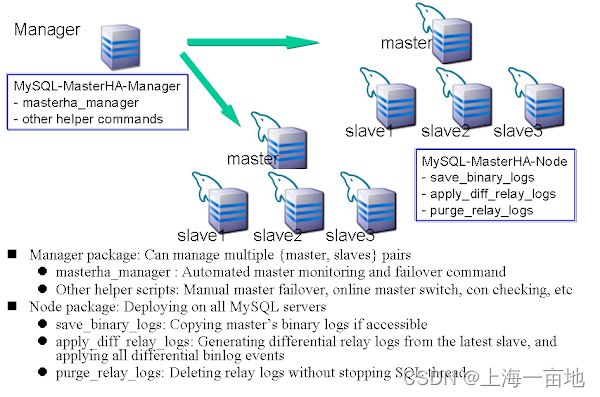
MHA管理器具有管理器程序,如监控MySQL主服务器、控制主服务器故障转移等。MHA节点具有故障转移辅助脚本,例如解析MySQL二进制/中继日志、识别中继日志位置(中继日志应从该位置应用于其他从属服务器)、将事件应用于目标从属服务器等。MHA节点在每个MySQL服务器上运行。当MHA管理器执行故障转移时,MHA管理器通过SSH连接MHA节点,并在需要时执行MHA节点命令。
MHA有几个扩展功能。例如,MHA可以调用任何自定义脚本来更新主机的IP地址(更新管理主机IP地址的全局编录数据库、更新虚拟IP等)。这是因为如何管理IP地址取决于用户的环境,而MHA不希望强制使用一种方法。目前的扩展点如下。MHA管理器软件包包括如下示例脚本。secondary_check_script:用于从多个网络路由检查主服务器的可用性。master_IP_failover_script:用于更新从应用程序使用的主服务器的IP地址。
shutdown_script:用于强制关闭主服务器。
report_script:用于发送报告。
INIT_CONF_LOAD_SCRIPT:用于加载初始配置参数。
master_IP_online_change_script:用于更新主IP地址。这不用于主故障转移,而是用于联机主交换机。
MHA的优势
主节点故障转移和从节点升级可以非常快速地完成
MHA通常可以在几秒钟内完成故障转移(9-12秒检测主机故障,可选地7-10秒关闭主机以避免裂脑,几秒钟将差分中继日志应用于新的主机,因此总停机时间通常为10-30秒),只要从机不严重延迟复制。在改造新主人之后,MHA同时恢复其余的奴隶。即使你有几十个奴隶,也不会影响主人的恢复时间,而且你可以很快恢复奴隶。DeNA在150+{主,从}环境中使用MHA。当其中一个主服务器崩溃时,MHA在4秒内完成了故障转移。使用传统的主动/被动群集解决方案,在4秒内完成故障转移是绝对不可能的。
主节点崩溃不会导致数据不一致
一旦当前主设备崩溃时,MHA自动识别从设备之间的差分中继日志事件,并应用于每个从设备。最后,只要所有从服务器都处于活动状态,所有从服务器都可以同步。通过与半同步复制一起使用,还可以保证(几乎)没有数据丢失。
无需修改当前MySQL配置
(MHA适用于常规MySQL(5.0或更高版本))
MHA最重要的设计原则之一是尽可能长时间地使MHA易于使用。MHA适用于现有的传统MySQL 5.0+主从复制环境。尽管许多其他HA解决方案需要更改MySQL部署设置,但MHA并不强制DBA执行此类任务。MHA适用于最常见的两层单主设备和多从设备环境。MHA可用于异步和半同步MySQL复制。可以在不更改(包括启动/停止)MySQL复制的情况下启动/停止/升级/降级/安装/卸载MHA。当您需要将MHA升级到较新的版本时,您不需要停止MySQL。只需更换为较新的MHA版本并重新启动MHA管理器即可。MHA适用于从MySQL 5.0开始的普通MySQL版本。一些HA解决方案需要特殊的MySQL版本(即MySQL集群、具有全局事务ID的MySQL等),但您可能不喜欢只为主HA迁移应用程序。在许多情况下,人们已经部署了许多遗留的MySQL应用程序,他们不想花费太多时间迁移到不同的存储引擎或更新的前沿发行版,只是为了主HA。MHA适用于普通的MySQL版本,包括5.0/5.1/5.5,因此您不需要迁移。
无需添加额外服务器
MHA由MHA管理器和MHA节点组成。当发生故障转移/恢复时,MHA节点在MySQL服务器上运行,因此它不需要额外的服务器。MHA Manager通常在专用服务器上运行,因此您需要添加一台(或两台用于HA)服务器,但MHA Manager可以从一台服务器监控大量(甚至100多台)主机,因此服务器总数不会增加太多。请注意,甚至可以在其中一个从服务器上运行MHA管理器。在这种情况下,服务器的总数根本没有增加。
没有性能损失
MHA works with regular asynchronous or semi-synchronous MySQL replication. When monitoring master server, MHA just sends ping packets to master every N seconds (default 3) and it does not send heavy queries. You can expect as fast performance as regular MySQL replication.
适用于任何存储引擎
只要MySQL的复制功能正常运作,MHA就可以与任何存储引擎一起工作,而不限于InnoDB(崩溃安全,事务存储引擎)。即使您使用不容易迁移的传统MyISAM环境,您也可以使用MHA。
使用案例
在哪能部署manager
- 专用Manager服务器和多个MySQL(主、从)服务器:
由于MHA管理器使用非常少的CPU/内存资源,您可以从单个MHA管理器管理大量(主,从)对。甚至可以从单个Manager服务器管理100多个对。 - 在其中一个MySQL从属服务器上运行MHA管理器:
如果您只有一个(主,从)对,您可能不喜欢为MHA管理器分配专用硬件,因为这会增加相对较高的成本。在这种情况下,在其中一个从属服务器上运行MHA管理器是有意义的。请注意,当前版本的MHA Manager通过SSH连接到MySQL从服务器,即使MySQL服务器与MHA Manager位于同一主机上,因此您需要从同一主机启用SSH公钥身份验证。
多副本配置
- 单主节点,多从节点

这是最常见的复本设置。MHA在这样工作得很好。 - 单主节点,多从节点(某些从节点在远程数据中心)

在许多情况下,您希望在远程数据中心上至少部署一个从属服务器。当主服务器崩溃时,您可能不希望将远程从属服务器提升为新的主服务器,而是让本地数据中心上运行的其他从属服务器之一成为新的主服务器。MHA支持这些要求。在配置文件中设置NO_MASTER=1,使从机永远不会成为新的主机。 - 单主节点,多从节点(有一个备选主节点)

在某些情况下,如果当前主服务器崩溃,您可能希望将特定服务器提升为新的主服务器。在这种情况下,在配置文件中设置CANDIDATE_MASTER=1将有所帮助。 - 多个主节点和从节点

在某些情况下,您可能希望使用多主机配置,并且如果当前主机崩溃,您可能希望将只读主机设置为新的主机。只要所有非主主机(本图中的M2)都是只读的,MHA管理器就支持多主机配置。 - 三层副本,单主节点

在某些情况下,您可能需要像这样使用三层复制。MHA仍可用于主故障转移。在配置文件中,管理主设备和所有第二层从设备(在此图中,在MHA配置文件中添加M、S1、S2和SR,但不添加SR2)。如果当前主设备(M)发生故障,MHA会自动将其中一个二级从设备(S1、S2、SR,您也可以设置优先级)升级到新的主设备,并恢复其余的二级从设备。第三层从服务器(SR2)不受MHA管理,但只要SR(SR2的主服务器)处于活动状态,SR2就可以继续复制,而无需更改任何内容。如果SR崩溃,则SR2无法继续复制,因为SR2的主服务器是SR。MHA无法用于恢复SR2。这就是需要支持全局事务ID的地方。希望这次不会像主碰撞那么严重。
三层副本,多主节点

这种结构也得到支持。在这种情况下,Host5是第三层从属主机,因此MHA不管理Host5(当主要主机Host1发生故障时,MHA不在Host5上执行Change Master)。当当前主主机Host1关闭时,Host2将成为新的主主机,因此Host5可以在不执行任何操作的情况下保留来自Host2的复制。以下是配置文件示例。
[server default]
multi_tier_slave=1
[server1]
hostname=host1
candidate_master=1
[server2]
hostname=host2
candidate_master=1
[server3]
hostname=host3
[server4]
hostname=host4
[server5]
hostname=host5
管理主节点IP地址
在常见的高可用性环境中,很多情况下人们会在主服务器上分配一个虚拟IP地址。如果主服务器崩溃,HA软件(如Pacemaker)会接管备用服务器的虚拟IP地址。另一种常用方法是创建一个全局编录数据库,其中包含应用程序名称和编写器/读取器IP地址之间的所有映射(即{app1_writer,192.168.0.1},{app2_writer,192.168.0.2},…)而不是使用虚拟IP地址。在这种情况下,您需要在当前主服务器死亡时更新目录数据库。这两种方法各有利弊。MHA并不强制使用一种方法,而是让用户可以使用任何IP地址故障转移解决方案。通过在管理器的配置文件中设置MASTER_IP_FAILOVER_SCRIPT参数,MHA可以选择调用外部脚本来停用/激活编写器IP地址。您可以更新目录数据库、接管虚拟IP地址或在脚本中执行任何操作。您还可以使用现有的HA软件(如Pacemaker)来执行IP故障转移。在这种情况下,MHA本身不执行IP故障转移。
使用半同步复制
尽管MHA试图从崩溃的主服务器中保存二进制日志,但这并不总是可能的。例如,如果崩溃的主服务器因硬件故障而死亡或无法通过SSH访问,则MHA无法保存二进制日志,并且必须在不应用仅存在于崩溃的主服务器上的二进制日志事件的情况下进行故障转移。这将导致丢失最新数据。使用半同步复制可大大降低此类数据丢失的风险。MHA使用半同步复制,因为它基于MySQL复制机制。值得注意的是,如果只有一个从属服务器接收到最新的二进制日志事件,MHA可以将这些事件应用于所有其他从属服务器,以便它们可以彼此保持一致。
准备开始
指南
简单的故障转移
- 构建普通的副本环境。
MHA不会自己构建副本环境,因此您需要自己设置复制。换句话说,您可以在现有环境中使用MHA。例如,假设有四个主机:host1、host2、host3、host4。主服务器当前在Host1上运行,两个从服务器在Host2和Host3上运行。所以MySQL服务器运行在Host1、Host2和Host3上。让我们在host4(manager_host)上运行MHA管理器。 - 在主机1-主机4上安装MHA节点:
请参阅安装MHA节点 - 在主机4(manager_host)上安装MHA管理器:
请参阅安装MHA管理器。MHA管理依赖于MHA节点包,因此您需要在Manager服务器上安装两者。 - 创建一个配置文件:
下一步是在MHA管理器上创建配置文件。参数包括每个MySQL服务器的主机名、MySQL用户名和密码、MySQL复制用户名和密码、工作目录名称等。在参数页面中描述了所有参数。
vim /etc/app1.cnf
--------------------------------
[server default]
# mysql user and password
user=root
password=mysqlpass
ssh_user=root
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=host1
[server2]
hostname=host2
[server3]
hostname=host3
请注意,您没有指定host1是当前主节点。MHA在内部自动检测当前主机。
- 检查SSH连接。
MHA管理器通过SSH在内部调用MHA节点包中包含的程序。MHA节点程序还通过SSH(SCP)将差分中继日志文件发送到其他非最新的从属服务器。要使这些过程成为非交互式过程,必须设置SSH公钥身份验证。MHA Manager提供了一个简单的检查程序“masterha_check_SSH”,用于验证彼此之间是否可以建立非交互式SSH连接。
# masterha_check_ssh --conf=/etc/app1.cnf
Sat May 14 14:42:19 2011 - [warn] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sat May 14 14:42:19 2011 - [info] Reading application default configurations from /etc/app1.cnf..
Sat May 14 14:42:19 2011 - [info] Reading server configurations from /etc/app1.cnf..
Sat May 14 14:42:19 2011 - [info] Starting SSH connection tests..
Sat May 14 14:42:19 2011 - [debug] Connecting via SSH from root@host1(192.168.0.1) to root@host2(192.168.0.2)..
Sat May 14 14:42:20 2011 - [debug] ok.
Sat May 14 14:42:20 2011 - [debug] Connecting via SSH from root@host1(192.168.0.1) to root@host3(192.168.0.3)..
Sat May 14 14:42:20 2011 - [debug] ok.
Sat May 14 14:42:21 2011 - [debug] Connecting via SSH from root@host2(192.168.0.2) to root@host1(192.168.0.1)..
Sat May 14 14:42:21 2011 - [debug] ok.
Sat May 14 14:42:21 2011 - [debug] Connecting via SSH from root@host2(192.168.0.2) to root@host3(192.168.0.3)..
Sat May 14 14:42:21 2011 - [debug] ok.
Sat May 14 14:42:22 2011 - [debug] Connecting via SSH from root@host3(192.168.0.3) to root@host1(192.168.0.1)..
Sat May 14 14:42:22 2011 - [debug] ok.
Sat May 14 14:42:22 2011 - [debug] Connecting via SSH from root@host3(192.168.0.3) to root@host2(192.168.0.2)..
Sat May 14 14:42:22 2011 - [debug] ok.
Sat May 14 14:42:22 2011 - [info] All SSH connection tests passed successfully.
如果masterha_check_SSH因错误或身份验证请求而停止,则SSH配置对MHA工作无效。你需要修复它,然后再试一次。最可能的原因是未正确设置SSH公钥身份验证。
- 检查副本配置
要使MHA正常工作,配置文件中定义的所有MySQL主服务器和从服务器都必须正常工作。MHA Manager提供了一个命令masterha_check_repl来快速检查复制运行状况。
manager_host$ masterha_check_repl --conf=/etc/app1.cnf
...
MySQL Replication Health is OK.
如果您在此处遇到任何错误,请检查日志并修复问题。当前主服务器不能是从服务器,所有其他从服务器必须从主服务器复制。“典型错误”页可能有助于修复安装错误。
- 启动manager管理器
您配置了MySQL文件中副本,安装了MHA节点和MHA管理器,并配置了SSH公钥身份验证。下一步是启动MHA管理器。可通过masterha_manager命令启动MHA管理器。
manager_host$ masterha_manager --conf=/etc/app1.cnf
....
Sat May 14 15:58:29 2011 - [info] Connecting to the master host1(192.168.0.1:3306) and sleeping until it doesn't respond..
如果所有配置都有效,则masterha_manager将检查MySQL主服务器的可用性,直到主服务器失效。如果masterha_manager在监视master之前因错误而停止,请检查错误日志并修复配置。默认情况下,所有日志都打印到标准错误(stderr),但这可以在“manager_log”配置参数中进行更改。典型的错误是MySQL复制配置无效,SSH_user没有足够的权限(最低要求是对中继日志的读取权限和对remote_workdir的写入权限)。默认情况下,masterha_manager在前台运行。如果您向MasterHA_Manager发送SIGINT(发送Ctrl+C),MasterHA_Manager将停止监视并退出。
- 检查manager管理器状态
在MHA Manager监视MySQL Master之后,它不会打印任何内容,直到Master变得无法访问或终止Manager本身。您可能需要检查MHA管理器是否确实工作正常。MASTERHA_CHECK_STATUS命令可用于检查当前的MHA管理器状态。下面是一个例子。
manager_host$ masterha_check_status --conf=/etc/app1.cnf
app1 (pid:5057) is running(0:PING_OK), master:host1
“App1”是MHA内部处理的应用程序名称,它是配置文件的前缀名称。
如果管理器停止或配置文件无效,将返回以下错误。
manager_host$ masterha_check_status --conf=/etc/app1.cnf
app1 is stopped(1:NOT_RUNNING).
- 停止管理器
你可以通过 masterha_stop 命令来停止MHA管理器。
manager_host$ masterha_stop --conf=/etc/app1.cnf
Stopped app1 successfully.
如果它没有停止(即挂起),请添加“–abort”参数。了解如何停止MasterHA_Manager后,让我们再次启动它。
- 测试主节点崩溃
现在,MHA Manager监控MySQL主服务器的可用性。接下来,让我们测试主故障转移是否正常工作。为了模拟这一点,您可以简单地在主服务器上杀死mysqld。
host1$ killall -9 mysqld mysqld_safe
在某些发行版(如Ubuntu)上,天使进程会自动重启mysqld。如果mysqld重新启动非常快(几秒钟),在MHA启动故障转移之前,来自MHA的ping将再次成功。在这种情况下,故障切换不会启动。如果重新启动mysqld需要很长时间(即InnoDB崩溃恢复需要2分钟),则将启动故障转移。如果您在测试杀死mysqld时遇到困难,或者如果您想测试Linux内核端的问题,调用内核恐慌是很容易的。
host1# echo c > /proc/sysrq-trigger
检查MHA Manager上的日志,并验证Host2是否成为新的主节点,以及Host3是否从Host2复制。当故障转移完成(或以错误结束)时,MHA管理器进程停止。这是预期的行为。如果要永久运行MHA管理器,请阅读“在后台运行MHA管理器”部分。
- 下一步
现在,我们已经介绍了主设备故障转移的基本测试。在实践中,你可能想做很多事情,如下所示。
通过两个或多个网络路由检查MySQL主服务器的可用性。有关详细信息,请参阅secondary_network_script参数。编写主服务器IP故障转移脚本在上面的教程中,新的主服务器的IP地址(主机2的IP)已从失效的主服务器的IP地址(主机1的IP)更改。因此应用程序必须更改主服务器的IP地址。这可不好玩。要解决此问题,请使用master_IP_failover_script参数。你可以编写任何程序来更新主人的IP地址。例如,接管虚拟IP地址、更新全局编录数据库等。示例脚本包含在MHA管理器包中(请参阅(MHA管理器目录)/samples/scripts/master_IP_failover)。示例脚本包含在MHA管理器tarball和GitHub分支中。在后台运行MHA管理器。有关详细信息,请参阅Runnning_Background页面。关闭MySQL主服务器,以便永远不会发生裂脑。请参阅MHA管理器包中包含的shutdown_script参数和示例脚本(MHA管理器目录)/samples/scripts/power_manager。故障转移完成时发送电子邮件。请参阅MHA管理器包中的report_script参数和示例脚本(MHA管理器目录)/samples/scripts/send_report。故障转移错误和手动故障转移测试您可能需要测试失败场景。请参见下面的示例。
terminal1# masterha_manager --conf=/etc/app1.cnf
terminal2# mysql -hhost2 db1 -e "insert into t1 values (100, 100, 100)"
terminal2# mysql -hhost1 db1 -e "insert into t1 values (100, 100, 100)"
Check replication stops with error
kill master
Check master failover does not work.
mysql_host2> set global slave_sql_skip_counter=1;
mysql_host2> start slave;
Check replication starts again.
Test manual failover
# remove error file
# rm -f /var/log/masterha/mha_test50/mha_test50.failover.error
# masterha_master_switch --master_state=dead --conf=/path/to/conf --dead_master_host=host1
安装
MHA由MHA管理器和MHA节点包组成。MHA管理器在管理器服务器上运行,而MHA节点在每个MySQL服务器上运行。MHA节点程序并不总是运行,而是在需要时(在配置检查、故障转移等时)从MHA管理器程序调用。MHA管理器和MHA节点都是用Perl编写的。
下载MHA Node和MHA Manager
MHA节点和MHA管理器可从“下载”部分下载。这些是稳定的软件包。如果您想尝试开发源码树,请查看GitHub源码树。点击这里下载托管MHA管理器,点击这里下载托管MHA节点。
安装MHA node节点
MHA node具有执行以下操作的脚本和相关Perl模块。
SAVE_BINARY_LOGS:保存和复制死主的二进制日志。
APPLY_DIFF_RELAY_LOGS:识别差分中继日志事件并应用所有必要的日志事件。PURGE_RELAY_LOGS:清除中继日志文件您需要将MHA节点安装到所有MySQL服务器(主服务器和从服务器)。
您还需要在管理服务器上安装MHA node,因为MHA manager模块在内部依赖于MHA node模块。MHA manager在内部通过SSH连接到托管的MySQL服务器,并执行MHA node脚本。除了DBD:MySQL之外,MHA node不依赖于任何外部Perl模块,因此您应该能够轻松安装。
在RHEL/CentOS发行版上,您可以按如下所示安装MHA node的RPM包:
## If you have not installed DBD::mysql, install it like below, or install from source.
# yum install perl-DBD-MySQL
## Get MHA Node rpm package from "Downloads" section.
# rpm -ivh mha4mysql-node-X.Y-0.noarch.rpm
在Ubuntu/Debian发行版上,您可以按如下所示安装MHA node的RPM包:
## If you have not installed DBD::mysql, install it like below, or install from source.
# apt-get install libdbd-mysql-perl
## Get MHA Node deb package from "Downloads" section.
# dpkg -i mha4mysql-node_X.Y_all.deb
你也可以源码安装
## Install DBD::mysql if not installed
$ tar -zxf mha4mysql-node-X.Y.tar.gz
$ perl Makefile.PL
$ make
$ sudo make install
安装MHA Manager
MHA管理器具有管理命令行程序,如MasterHA_Manager、MasterHA_Master_Switch等,以及相关的Perl模块。MHA管理器依赖于以下Perl模块。您需要在安装MHA管理器之前安装它们。不要忘记安装MHA节点。
MHA Node package
DBD::mysql
Config::Tiny
Log::Dispatch
Parallel::ForkManager
Time::HiRes (included from Perl v5.7.3)
在RHEL/CentOS发行版上,您可以安装MHA Manager RPM包,如下所示。
## Install dependent Perl modules
# yum install perl-DBD-MySQL
# yum install perl-Config-Tiny
# yum install perl-Log-Dispatch
# yum install perl-Parallel-ForkManager
## Install MHA Node, since MHA Manager uses some modules provided by MHA Node.
# rpm -ivh mha4mysql-node-X.Y-0.noarch.rpm
## Finally you can install MHA Manager
# rpm -ivh mha4mysql-manager-X.Y-0.noarch.rpm
在Ubuntu/Debian发行版上,您可以安装MHA Manager RPM包,如下所示。
## Install dependent Perl modules
# apt-get install libdbd-mysql-perl
# apt-get install libconfig-tiny-perl
# apt-get install liblog-dispatch-perl
# apt-get install libparallel-forkmanager-perl
## Install MHA Node, since MHA Manager uses some modules provided by MHA Node.
# dpkg -i mha4mysql-node_X.Y_all.deb
## Finally you can install MHA Manager
# dpkg -i mha4mysql-manager_X.Y_all.deb
你也可以源码安装MHA Manager
## Install dependent Perl modules
# MHA Node (See above)
# Config::Tiny
## perl -MCPAN -e "install Config::Tiny"
# Log::Dispatch
## perl -MCPAN -e "install Log::Dispatch"
# Parallel::ForkManager
## perl -MCPAN -e "install Parallel::ForkManager"
## Installing MHA Manager
$ tar -zxf mha4mysql-manager-X.Y.tar.gz
$ perl Makefile.PL
$ make
$ sudo make install
配置
编写一个应用配置文件
要使MHA工作,您必须创建一个配置文件并设置参数。参数包括每个MySQL服务器的主机名、MySQL用户名和密码、工作目录名称等。在参数页面中描述了所有参数。下面是一个示例配置文件。
vim /etc/app1.cnf
---------------------------
[server default]
# mysql user and password
user=root
password=mysqlpass
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# manager log file
manager_log=/var/log/masterha/app1/app1.log
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=host1
[server2]
hostname=host2
[server3]
hostname=host3
所有的配置参数都必须按照"param=value" 的格式,比如下面的参数设置就是不正确的:
[server1]
hostname=host1
# incorrect: must be "no_master=1"
no_master
应用程序范围参数应写入[Server Default]块中。在[Servern]块中,应设置本地范围参数。主机名是必需的本地范围参数,因此必须写在这里。块名称应从“服务器”开始。在内部,服务器配置按块名称排序,当MHA决定新的主服务器时,排序顺序很重要(有关详细信息,请参阅常见问题解答)。
编写一个全局配置文件
如果您计划从单个Manager服务器管理两个或多个MySQL应用程序((主,从)对),则创建全局配置文件会更易于配置。在全局配置文件中写入参数后,不需要为每个应用程序设置参数。如果在/etc/masterha_default.CNF中创建文件,MHA管理器脚本会自动将该文件作为全局配置文件读取。您可以在全局配置文件中设置应用程序范围参数。例如,如果所有MySQL服务器上的MySQL管理用户和密码都相同,则可以在此处设置“用户”和“密码”。
全局配置案例:
全局配置文件 (/etc/masterha_default.cnf)
[server default]
user=root
password=rootpass
ssh_user=root
master_binlog_dir= /var/lib/mysql
remote_workdir=/data/log/masterha
secondary_check_script= masterha_secondary_check -s remote_host1 -s remote_host2
ping_interval=3
master_ip_failover_script=/script/masterha/master_ip_failover
shutdown_script= /script/masterha/power_manager
report_script= /script/masterha/send_master_failover_mail
这些参数应用于主机上运行的MHA Manager监控的所有应用程序。应用程序配置文件应单独编写。下面的示例是配置App1(Host1-4)和App2(Host11-14)。
app1:
vim /etc/app1.cnf
----------------------------------
[server default]
manager_workdir=/var/log/masterha/app1
manager_log=/var/log/masterha/app1/app1.log
[server1]
hostname=host1
candidate_master=1
[server2]
hostname=host2
candidate_master=1
[server3]
hostname=host3
[server4]
hostname=host4
no_master=1
在上述情况下,MHA Manager在/var/log/masterha/app1下生成工作文件(包括状态文件),并在/var/log/masterha/app1/app1.log下生成日志文件。在监控其他应用时,需要设置唯一的目录/文件名。
app2:
vim /etc/app2.cnf
-------------------------
[server default]
manager_workdir=/var/log/masterha/app2
manager_log=/var/log/masterha/app2/app2.log
[server1]
hostname=host11
candidate_master=1
[server2]
hostname=host12
candidate_master=1
[server3]
hostname=host13
[server4]
hostname=host14
no_master=1
如果在全局配置文件和应用程序配置文件上设置相同的参数,则使用后者(应用程序配置)。
Binlog 服务器
从MHA版本0.56开始,MHA支持新的部分[binlogn]。在binlog部分,您可以定义mysqlbinlog流服务器。当MHA执行基于GTID的故障转移时,MHA会检查binlog服务器,如果binlog服务器领先于其他从服务器,则MHA会在恢复之前将差异binlog事件应用到新的主服务器。当MHA执行基于非GTID的(传统)故障转移时,MHA会忽略binlog服务器。下面是一个配置示例。
vim /etc/app1.cnf
---------------------
[server default]
# mysql user and password
user=root
password=mysqlpass
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# manager log file
manager_log=/var/log/masterha/app1/app1.log
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=host1
[server2]
hostname=host2
[server3]
hostname=host3
[binlog1]
hostname=binlog_host1
[binlog2]
hostname=binlog_host2
依赖和限制
要使MHA真正发挥作用,您需要验证以下设置。在启动masterha_manager或masterha_check_repl时,会自动检查大多数设置。
SSH公钥认证
MHA管理器在内部通过SSH连接到MySQL服务器。最新从服务器上的MHA节点还在内部通过SSH(SCP)向其他从服务器发送中继日志文件。要使这些过程自动化,通常建议启用不带密码短语的SSH公钥身份验证。您可以使用MHA管理器中包含的masterha_check_SSH命令来检查SSH连接是否正常工作。
# masterha_check_ssh --conf=/etc/app1.cnf
Sat May 14 14:42:19 2011 - [warn] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sat May 14 14:42:19 2011 - [info] Reading application default configurations from /etc/app1.cnf..
Sat May 14 14:42:19 2011 - [info] Reading server configurations from /etc/app1.cnf..
Sat May 14 14:42:19 2011 - [info] Starting SSH connection tests..
Sat May 14 14:42:19 2011 - [debug] Connecting via SSH from root@host1(192.168.0.1) to root@host2(192.168.0.2)..
Sat May 14 14:42:20 2011 - [debug] ok.
Sat May 14 14:42:20 2011 - [debug] Connecting via SSH from root@host1(192.168.0.1) to root@host3(192.168.0.3)..
Sat May 14 14:42:20 2011 - [debug] ok.
Sat May 14 14:42:21 2011 - [debug] Connecting via SSH from root@host2(192.168.0.2) to root@host1(192.168.0.1)..
Sat May 14 14:42:21 2011 - [debug] ok.
Sat May 14 14:42:21 2011 - [debug] Connecting via SSH from root@host2(192.168.0.2) to root@host3(192.168.0.3)..
Sat May 14 14:42:21 2011 - [debug] ok.
Sat May 14 14:42:22 2011 - [debug] Connecting via SSH from root@host3(192.168.0.3) to root@host1(192.168.0.1)..
Sat May 14 14:42:22 2011 - [debug] ok.
Sat May 14 14:42:22 2011 - [debug] Connecting via SSH from root@host3(192.168.0.3) to root@host2(192.168.0.2)..
Sat May 14 14:42:22 2011 - [debug] ok.
Sat May 14 14:42:22 2011 - [info] All SSH connection tests passed successfully.
使用masterha_secondary_check脚本检查其他网络连接时,还需要验证从MHA管理器到远程主机的SSH公钥访问是否可用。MHA管理器在内部并行执行恢复。在生成差分中继日志文件时,MHA通过SSH并行连接到最新的Slave,并生成和发送差分中继日志到非最新的Slave。如果您有数十个从属服务器,或者在单个操作系统中整合了数十个MySQL实例,sshd可能会拒绝SSH连接请求,这将导致从属服务器恢复错误。要避免此问题,请在/etc/SSH/sshd_config(默认值为10)中设置maxstartup参数,然后重新启动sshd。
操作系统
MHA只在Linux系统上测试通过
单个可写主设备和多个从设备或只读主设备
MHA修复了在Mater崩溃的情况下从设备之间的一致性问题。此外,MHA尝试从崩溃的主服务器保存未发送的二进制日志事件,并将事件应用于所有从服务器。如果您只有一个从属服务器,则不需要关心从属服务器之间的一致性问题。即使您只使用一个从服务器,只要崩溃的主服务器可以通过SSH访问,MHA对于保存来自崩溃的主服务器的事件仍然是有益的,但是使用半同步复制也可以解决这个问题。从MHA Manager版本0.52开始,支持多主机复制配置。以下是使MHA与多主机一起工作的一些注意事项。
只允许一个主要主机(可写)。必须在其他MySQL主服务器上设置 MySQL全局变量“Read-Only=1”。
默认情况下,所有托管服务器(在MHA配置文件中定义)都应位于两层复制通道中。详情见下文。
在MHA管理器版本0.52之前,MHA检查所有托管主机,并仅在所有从主机从同一主主机复制时才开始监控/故障转移。也就是说,MHA不支持多主机配置。通常,只要MHA管理自动故障转移,使用多主机配置的原因就是有限的,例如在线模式更改。如果您想暂时使用多主机配置(即仅用于模式更改),只需在操作期间停止MHA并配置多主机。操作完成后,再次进行单主多从配置,然后重启MHA。
管理3层或多层副本环境
默认情况下,MHA不支持三层或更多层复制结构(即Master1->Master2->Slave3)。MHA仅执行故障转移和恢复直接从当前主要主服务器复制的从属服务器。MHA可以管理Master1和Master2,并在Master1崩溃时提升Master2,但MHA无法监视和恢复Slave3,因为Slave3从不同的Master(Master2)复制。要使MHA与此类结构一起工作,请按以下方式配置。在这种情况下,只需在MHA配置文件中设置主主机和第二层主机(master1和master2)使用“multi_tier_slave=1”参数并在MHA配置文件中设置所有主机在这两种情况下,MHA只管理第一级主服务器和第二级从服务器。这仍然非常有帮助,因为在主要主服务器(Master1)崩溃的情况下,可以从Master1自动故障转移到Master2,并且第三层从服务器仍然可以工作。有关详细信息,请参见用例页面。
MySQL 5.0或更高版本
MHA支持MySQL 5.0或更高版本。MHA不支持MySQL 4.1或更早版本。这是因为二进制日志格式从MySQL 5.0更改(称为Binlog V4格式)。当MHA解析二进制日志以确定目标中继日志位置时,binlog格式必须为V4,因此MySQL 4.1在此处不起作用。MySQL 5.0或更高版本中的MySQLBinlog也要求binlog格式为V4。同样重要的是,早期版本的MySQL在MySQL复制处理方面存在一些严重问题,因此强烈建议使用更高版本。特别是如果您使用的是MySQL 5.0.60之前的版本,请考虑升级它。
为MySQL 5.1+使用mysqlbinlog 5.1+
MHA使用mysqlbinlog将binlog事件应用到目标slave。如果主服务器使用基于行的格式,则基于行的事件将写入二进制日志。MySQL 5.1或更高版本中的mysqlbinlog可以解析此类二进制日志,因为MySQL 5.0中的mysqlbinlog不支持基于行的格式。MySQLBinLog(和MySQL)版本可按如下方式检查。
[app@slave_host1]$ mysqlbinlog --version
mysqlbinlog Ver 3.3 for unknown-linux-gnu at x86_64
如果MySQLBinLog包含在MySQL 5.1中,则其版本应为3.3或更高版本。MHA在内部检查所有从属服务器上的MySQL和mysqlbinlog版本。如果mysqlbinlog版本为3.2或更低版本,并且MySQL版本为5.1或更高版本,则MHA在开始监控之前会因错误而停止。
备选主节点上必须激活log-bin
如果当前从服务器没有设置log-bin,显然它们不能成为新的主服务器。MHA管理器在内部检查日志箱设置,并且不将它们提升到新的主服务器。如果当前的从属服务器都没有设置log-bin,则MHA管理器不会进行故障转移。
所有服务器上的二进制日志和中继日志筛选规则必须相同
所有MySQL服务器上的复制过滤规则(binlog-do-db、replicate-ignore-db等)必须相同。MHA在启动时检查过滤规则,如果过滤规则彼此不同,则不会启动监控或故障转移。
备选主机上必须存在副本用户
主服务器故障转移完成后,所有其他从服务器执行CHANGE MASTER TO语句。要启动复制,新主服务器上必须存在副本用户(具有复制从属权限)。
保存中继日志并定期清除
默认情况下,如果SQL线程执行完从服务器上的中继日志,则会自动删除这些日志。但是这样的中继日志可能仍然需要用于恢复其他从设备。因此,您需要禁用自动中继日志清除,并定期清除旧的中继日志。但在手动清除中继日志时,您需要注意复制延迟问题。在ext3文件系统上,删除大文件需要花费大量时间,这将导致严重的复制延迟。为了避免复制延迟,试探性地创建中继日志的硬链接会有所帮助。有关详细信息,请参阅“双分片”。
Purge_relay_logs脚本:
MHA节点有一个命令行工具“PURGE_RELAY_LOGS”来执行此操作。PURGE_RELAY_LOGS执行上述幻灯片中描述的所有操作。也就是说,它创建硬链接,执行“set global relay_log_purge=1”,等待几秒钟,以便SQL线程可以切换到新的中继日志(只要它明显落后),并执行“set global relay_log_purge=0”。PURGE_RELAY_LOGS采用以下参数。PURGE_RELAY_LOGS在内部连接到MySQL从属服务器,因此需要MySQL身份验证参数。–用户MySQL用户名。默认情况下,它是root。–password MySQL–user的密码。默认情况下,它是空的。–host MySQL主机名。默认情况下,它是127.0.0.1。–host必须与运行purge_relay_logs的服务器相同。例如,如果在host1上传递–host=host2,则purge_relay_logs将中止。如果您在host1上有虚拟主机名vhost1,则在host1上传递–host=vhost1是有效的,并且purge_relay_logs不会中止。–port MySQL端口号。默认值为3306。–workdir创建和删除硬链接中继日志的暂定目录。成功执行脚本后,将删除硬链接的中继日志文件。默认情况下,它是/var/TMP。如果将中继日志文件放在与/var/TMP不同的操作系统分区上,则需要显式设置此参数。这是因为不支持在不同的操作系统分区之间创建硬链接(您将得到“Invalid Cross-Device Link”错误)。在这种情况下,将–workdir设置为与中继日志文件位于同一操作系统分区的目录。–disable_relay_log_purge默认情况下,如果在MySQL中relay_log_purge为on(1),则purge_relay_logs脚本将退出而不执行任何操作。因此,Relay_Log_Purge仍处于打开状态(1)。通过设置–disable_relay_log_purge,purge_relay_logs脚本不会退出并自动将relay_log_purge设置为0。因此,在执行脚本之后,relay_log_purge变为off(0)。
定时运行purge_relay_logs脚本
PURGE_RELAY_LOGS删除中继日志而不阻塞SQL线程。需要定期清除中继日志(即每天一次、每6小时一次等),因此应在每个从服务器上从作业调度器定期调用PURGE_RELAY_LOGS。例如,您可以从cron调用purge_relay_logs,如下所示。
[app@slave_host1]$ cat /etc/cron.d/purge_relay_logs
# purge relay logs at 5am
0 5 * * * app /usr/bin/purge_relay_logs --user=root --password=PASSWORD --disable_relay_log_purge >> /var/log/masterha/purge_relay_logs.log 2>&1
建议在从服务器之间的不同时间调用cron。如果所有从属服务器同时调用PURGE_RELAY_LOGS,则在崩溃时,所有从属服务器都可能没有必要的中继日志事件。
不要将LOAD DATA INFILE与基于二进制日志记录的语句一起使用
如果您使用非事务性存储引擎或太旧的MySQL版本(即5.0.45等),则当主服务器在使用基于语句的二进制日志记录完成加载数据文件后崩溃时,MHA可能无法生成差分中继日志事件。在SBR中使用LOAD DATA INFILE有一些已知的问题,它已从MySQL 5.1中删除。LOAD DATA INFILE还会导致显著的复制延迟,因此没有使用它的积极理由。如果要使用LOAD DATA, SET sql_log_bin=0,那么使用LOAD DATA … ; SET sql_log_bin=1;是更值得推荐的方法。
基于GTID的故障转移
从MHA 0.56开始,MHA支持基于GTID的故障转移和传统的基于中继日志的故障转移。MHA自动区分要选择的故障转移。要执行基于GTID的故障转移,需要具备以下所有条件。使用MySQL 5.6(或更高版本)所有MySQL实例都使用GTID_MODE=1至少一个实例启用了AUTO_POSITION。