蓝桥杯倒计时 | 倒计时18天
作者️♂️:让机器理解语言か
专栏:蓝桥杯倒计时冲刺
描述:蓝桥杯冲刺阶段,一定要沉住气,一步一个脚印,胜利就在前方!
寄语:没有白走的路,每一步都算数!
题目一:暑假作业
2016年第七届省赛,lanqiao0J题号1388
【题目描述】加减乘除四种运算:
每个方块代表1~13中的某一个数字,但不能重复。
比如:
6 + 7 = 13 9 - 8 = 1 3 * 4 = 12 10 / 2 = 5以及:
7 + 6 = 13 9 - 8 = 1 3 * 4 = 12 10 / 2 = 5就算两种解法。(加法,乘法交换律后算不同的方案)
一共有多少种方案?
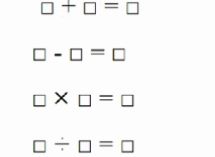
解法一:简单做法(超时)
用第二期排列组合的permutations( )函数,从13个数中挑12个数出来,生成所有的排列(缺点:不能提前终止,导致时间太长),检查是否合法。
运行时间极长: 13个数的排列: 13!= 6,227,020,800,可能需要半小时。
解法二: DFS自写全排列
排列问题可以用DFS来写,不需要生成一个完整排列。
例如:一个排列的前3个数,如果不满足“□+□=□”,那么后面的9个数不管怎么排列都不对。
这种提前终止搜索的技术叫“剪枝”。
排列的前三个数做加法,4~6个数做减法,7~9个数做乘法,10~12个数做除法
def dfs(num):
global ans
if num==13: # 四个式子都排列好了
# 下面除法改写成乘法,因为除法包括精度问题(小数部分)
if b[10]== b[11]*b[12]:ans+=1 # 最后一个要求也满足,ans+=1,结束
return
# 剪枝操作:提前终止
if num==4 and b[1]+b[2] != b[3]: return #剪枝
if num==7 and b[4]-b[5] != b[6]: return #剪枝
if num==10 and b[7]*b[8] != b[9]: return #剪枝
# 输出1到13全排列(套模板)
for i in range(1,14):
if not vis[i]:
b[num]=i # # 存排列(这里不用a[i],因为是1到n的数)
vis[i]=1
dfs(num+1)
vis[i]=0
ans=0
b =[0]*15 # 记录生成的一个全排列
vis=[0]*15
dfs(1)
print(ans) # 64题目二:拼数

【简单粗暴法】:先得到这n个整数的所有排列,然后找其中最大的。但是这个方法的复杂度是O(n!),当n=20时,有20!= 2X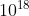 种排列,超时。。。
种排列,超时。。。
from itertools import *
N = int(input()) # 其实没用到
ans = ''
nums =list( map(str,input().split())) # 按字符的形式读入
for element in permutations(nums): # 每次输出一个全排列
a="".join(element) # 把这个全排列的所有元素拼起来,得到一个串
if ans < a: # 在所有串中找最大的
ans = a # 如果有比ans更大的,将这个数赋值给ans
print(ans)注意:"".join(element)只能将element中的字符串拼接起来,不能对int型数字进行拼接
【推荐做法】:暴力排列不行,可以用排序吗?本题不能直接对数字排序然后首尾相接,例如“7,13”,应该输出“713”而不是“137”。注意到这其实是按两个数字组合的字典序(先比较第一位数,再逐一比较后面的数)排序,也就是把数字看成字符串来排序。在比较第一位时,如果后面的数num[j]大于前面的num[i],则进行交换,确保num是按从大到小(大的数在前面,拼出来的数最大)的顺序。本题的n很小,用较差的排序算法也行,例如交换排序。第3-6行用交换排序对所有的数(按字符串处理) 进行排序,复杂度O(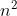 )。
)。
n = int(input())
nums = input().split() # 按字符读入
# 交换排序(j在i后面)
for i in range(0,n-1):
for j in range(i+1,n):
if nums[j]+nums[i]>nums[i]+nums[j]: #字符串合并然后比较
nums[j],nums[i] = nums[i],nums[j] #交换两个数(其实是字符串)的位置
print("".join(nums))注意:字符串‘数字’比较大小比较的是字典序大小!
题目三:奖学金


法一:简洁写法
n = int(input())
scores = []
for i in range(n):
score = list(map(int,input().split())) # 读语、数、外
scores.append([i+1,sum(score)]+score) # 学号、总分、语、数、外
index = reversed((1,2)) # reversed:反转。按总分、语文、学号排序.
# 学号默认从1开始,满足题目要求的从小到大的排序,所以只需要排序总分和语文即可
# 先排语文,再排序总分,因为总分优先级最高
for i in index: # 排序
scores.sort(key=lambda x:x[i],reverse=True) # 按x[i]降序
# scores = sorted(scores,key=lambda x:x[i],reverse=True)
for i in range(5):
print(scores[i][0],scores[i][1])
法二:自写比较函数cmp( )
import functools
def cmp(n1,n2): # 1表示降序,-1表示升序
if n1[1]!=n2[1]: # 总分不一样的,高分在前
return -1 if n1[1]>n2[1] else 1
elif n1[2] != n2[2]: # 总分一样,语文不一样的,语文高在前
return -1 if n1[2]>n2[2] else 1
else: # 成绩,语文都一样的,学号小的在前
return 1 if n1[0]>n2[0] else -1
n = int(input())
scores = []
for i in range(n):
score = list(map(int,input().split()))
scores.append([i+1,sum(score)]+score)
# scores.sort(key=functools.cmp_to_key(cmp)) # 用sort
scores = sorted(scores,key=functools.cmp_to_key(cmp)) # 用sorted
for i in range(5):
print(scores[i][0],scores[i][1])functools.cmp_to_key的功能就是定义排序时的规则,使数组按照自己定义的规则进行排序。