java ddd_DDD小结 - java随记 - BlogJava
充血与贫血模型
不去具体讲概念,感兴趣的可以网上自己去找找理解一下。
1.1还记得初学Java时那个动物对象的例子吗?
public classDog {
privateintage;
privateStringcolor;
publicintgetAge() {
return age;
}
//吃
publicvoideat(Objectfood) {
System.out.println("吃...");
}
//睡
publicvoidrest() {
System.out.println("睡...");
}
}
对象是行为和属性的封装。上面的类定义没毛病。简单点理解,所谓充血模型其实就是面象对象编程,这也是DDD所推崇的。没有新鲜事,老外爱搞概念,愣是整出个充血跟DDD来。
1.2贫血模型的例子
public classDog {
privateintage;
privateStringcolor;
privateStringstatus;
publicintgetAge() {
return age;
}
publicvoidsetAge(intage) {
this.age=age;
}
publicString getColor() {
return color;
}
publicvoidsetColor(Stringcolor) {
this.color=color;
}
publicString getStatus() {
return status;
}
publicvoidsetStatus(Stringstatus) {
this.status=status;
}
public classDogService {
//吃
publicvoideat(Dogdog, Objectfood) {
dog.setStatus("吃");
System.out.println(dog.toString() +food.toString());
}
//睡
publicvoidrest(Dogdog) {
dog.setStatus("睡觉");
System.out.println(dog.toString() +"睡觉觉...");
}
publicDog getDog(){
return newDog();
}
}
public classDogController {
publicvoideat() {
Objectfood=newObject();
DogServiceds=newDogService();
Dogdog=ds.getDog();
ds.eat(dog,food);
}
publicvoidrest() {
DogServiceds=newDogService();
Dogdog=ds.getDog();
ds.rest(dog);
}
}
看到了吗?Dog类只有针对属性的get,set操作,行为被搬到service类了.这种风格是贫血模型的代表。缺点:根据个人代码风格,有的controller类很重,有的service类很重。最重要的是如果不具备一定的领域分析的知识,往往建出来的类似Dog的领域类是错误的,甚至会根据经验先建数据库再建领域类。经验丰富并且经验是对的那还好,但如果经验是错的呢。。。
2Domain层实现
Domain层是具体的业务领域层,是发生业务变化最为频繁的地方,是业务系统最核心的一层,是DDD关注的焦点和难点。这一层包含了如下一些domain object:entity、value object、domain event、domain service、factory、repository等
2.1实体类Enity
领域实体是domain的核心成员。domain entity具有如下三个特征:
·唯一业务标识
·持有自己的业务属性和业务行为
·属性可变,有着自己的生命周期,故实体对象可能和它之前的状态不一样,但有同样的唯一标识,是同一个实体.
生成唯一标识的方法:
1,用户提供(但几乎没有人这样用)
2,应用程序提供
3,持久化机制提供 比如mysql主键自增 。通常不适合水平分库,各限界上下文会重复。

创建实体:
1)通过构造函数

2)通过工厂方法创建

实体类的校验:
Strusts2框架有一个不错的validator接口,用于校验规则,它在调用控制器方法之前调用。如果自己实现一个简单的检验框架呢?
1)定义一个抽象的校验类

2)定义具体的实现。

经验分享:校验规则分内凛规则和依赖规则。
内凛规则是指那些自身需要必不可少的条件。如名字属性的不为空及长度等,年龄不能小于0。
依赖规则:比如请假需要依赖外部日历实体对象等。
2.2值对象Value Object
对照起来value object有如下特征:
·可以有唯一业务标识【区别于domain entity】
·持有自己的业务属性和业务行为 【同domain entity】
·一旦定义,他是不可变的,它通常是短暂的,这和java中的值对象(基本类型和String类型)类似 【区别于domain entity】
·当度量改变时,可以用另一个对象替换。
·不会对协作对象造成副作用。
·值对象相等性比较。(实体对象比较没有意义,每个实体对象有唯一值)
1,可替换性
如果一个值对象可以正常描述当前状态,引用关系可以一值存在。否则可以用一个新的值对象替换.
理解:比如Customer有一个收货地址Address,这个address可以建模值对象。换地址后这个值对象可替换。
2,值对象相等性
值对象全部属性值相等时,可以互换。
3,无副作用行为
一个对象方法可以设计为一个无副作用函数。它不修改对象本身的状态。


widthMiddleInitial方法并没有修改原来对象的firstname lastName属性
不建议值对象方法参数里有实体对象,防止修改。
3聚合
1, 啥是聚合?
理解一下聚合,其实是对象的依赖关系。
2,设计聚合时要考虑一致性.意味着一个客户请求只在一个聚合实例上执行一个命令方法.
3,聚合设计原则:设计小聚合。大的聚合即便能保证事务的一致性,也依然可能限制系统的性能可伸缩性。

一个庞大的聚合根还可能带来性能损耗。可能需要加载许多关联对象。
4.通过唯一标识引用其它聚合。
聚合之间有依赖关系时不要直接写依赖对象,通过唯一标识来引用。通过标识引用可以将不同限界上下文的分布式领域模型关联起来。
5,在边界之外使用最终一致性。当一个聚合执行命令方法时,还需要在其它聚合上执行任务,使用最终一致性。一种实用的方法可以支持最终一致性,即一个聚合的命令方法发布的领域事件及时地发布给异步的订阅方。
6,不要在聚合中注入资源库和领域服务。
设计小的聚合要注意是否过度的小。重新设计的聚合根如下图:
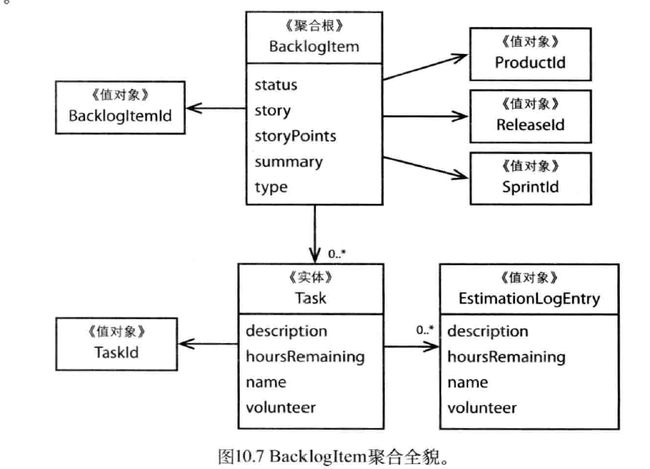
另一种设计 -> Task也作为聚合根

不在同一事务中修改BacklogItem和Task.
实现最终一致性

实现:
1,创建唯一标识的根实体。
2,优先使用值对象。
4领域事件
1,啥是领域事件?
领域专家所关心的发生在领域中的一些事件。
将领域中所发生的活动建模成一系列的离散事件。每个事件都用领域对象来表示...领域事件是领域模型的组成部分,表示领域中所发生的事情
首先是解决领域的聚合性问题。DDD中的聚合有一个原则是,在单个事务中,只允许对一个聚合对象进行修改,由此产生的其他改变必须在单独的事务中完成。如果一个业务跨多个聚合对象,领域事件会是一个不错的工具来解决这个问题。通过领域事件的方式可以达到各个组件之间的数据一致性,通过最终一致性取代事务一致性。
其次领域事件也是一种领域分析的工具,有时从领域专家的话中,我们看不出领域事件的迹象,但是业务需求依然有可能需要领域事件。动态流的事件模型加上结合DDD的聚合实体状态和BC,可以有效进行领域建模。
2,领域事件的技术实现
领域事件的技术实现实质上观察者模式的实现。技术的实现都好讲,关键是理解观察者模式在领域建模中的应用场景。
3,领域事件需要关注的类容。
一,消息设施最终一致性。
二,事件存储:
1),将事件存储作为一个消息队列使用。
2),检查由模型命令方法的所产生的所有结果的记录
3),使用事件存储中的数据进行业务预测和分析。、
4),通过事件存储重一个聚合。
5),撤销对聚合的操作
4,转发存储的架构风格。
5领域服务
1、领域服务表示一个无状态的操作,强调一个无状态的操作,状态应该在实体中维护,领域服务处理是无状态的逻辑过程;
2、实现某个领域的任务,即做的也是领域内的事情,是通用语言的表达。而不是应用服务,应用服务是领域服务的客户方,比如api聚合服务,不应该做领域内的事情。也不是基础设施服务,比如DB或消息基础组件。特别是不能跟现在常用的mvc+s架构中的s(service)层混淆,这种情形下的s,很多时候是持久层接口组装,更像是DDD中的资源库的概念。
3、先考虑聚合或值对像的建模,不适合,然后才使用领域服务。聚合(实体)和值对像才是最重要的DDD建模对象,如果反而首先使用领域服务,容易导致“贫血领域模型”。既然不适合直接在实体或值对像上建模,也基本说明很多时候涉及到多个实体或值对像。
那什么时候该使用领域服务呢?
1.执行一个显著的业务操作过程
2.对领域对象进行转换
3.以多个领域对象作为输入进行计算,结果产生一个值对像基本就是跟上面对领域服务概念的理解是一致的。
领域服务实现是否需要独立接口?
优点:使用接口表达领域概念,而技术实现可以比较随意,比如放在基础实施层,或者在依赖倒置原则中,放在应用层实现也可以;独立接口有利于解耦,通过依赖注入或工厂可以完全解耦客户端与具体实现;
缺点:得写两个对象代码,特别对于java,还得分两个文件,阅读代码也增加点难度,而很多时候一个接口也只有一个实现;另外一个命名问题,在DDD中领域对象名称(对应语言实现的类)和操作名称(对应函数名)是很重要的,是需要表达通用语言的概念的。但如果定义独立接口,也就是会XXXservice的名字来定义接口,但服务实现用什么命名呢?如果用XXXserviceImpl,那其实也说明可以不需要定义独立接口了。测试领域服务其实测试方面,我觉得没有很多需要关注的,或者说我比较少测试方面的需要。但在测试领域服务一节有句话却比较有意思“我们希望对领域服务进行测试,并且希望从客户端的角度对领域服务进行建模,同时我们希望测试能够反映查领域服务的使用方式”,即通过测试代码,告诉客户端怎么使用领域服务。这其实是测试代码的一个重要的作用,但也经常被我们忽略的。
注意:领域服务不能过多,那变成贫血模型了。
6应用服务层
应用层通过应用服务接口来暴露系统的全部功能。在应用服务的实现中,它负责编排和转发,它将要实现的功能委托给一个或多个领域对象来实现,它本身只负责处理业务用例的执行顺序以及结果的拼装。通过这样一种方式,它隐藏了领域层的复杂性及其内部实现机制。
应用层相对来说是较“薄”的一层,除了定义应用服务之外,在该层我们可以进行安全认证,权限校验,持久化事务控制,或者向其他系统发生基于事件的消息通知,另外还可以用于创建邮件以发送给客户等。
7架构及架构风格
一, 架构部分:
1) 限界上下文、子域:
领域:通常是指整个系统的业务边界.也可以指子域如核心域等。
子域:业务系统的某个方面。
限界上下文:同样的是业务系统中某个方面,它比子域的粒度更小。通常一个子域可以只包含一个限界上下文。
光看这个,有点绕。但直白点理解,其实它们就是架构中的关于系统/模块的划分。系统可以划分为多个子系统,子系统当然还可以划分为更小的子系统。或者业务模块的划分。
如果还不够直白,那么如果有微服务经验,可以想想、对照服务的划分。
2)上下文映射图:

DDD中的图示。个人理解:其实它就是各子系统/模块的依赖关系。比如现在典型电商系统子系统划分 会员系统、商品管理系统、资金系统。。。
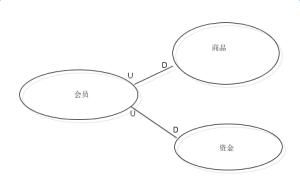
商品、资金均依赖于会员系统。基本上资金限界上下文同时也是一个子域。同时它们也各自被划分为了一个微服务系统。
二,架构风格:
《实现领域驱动设计》关于架构一章,章节名虽然叫架构,但应该理解成架构风格。就象传统的三层架一样,是一种架构风格。
1)六边形架构

它并不是真的有六条边.它也叫端口+适配器.端口可以理解成http,socket自定义传输协议、或者某个RPC调用协议等。六边形的内部代表了application和domain层。外部代表应用的驱动逻辑、基础设施或其他应用。内部通过端口和外部系统通信,端口代表了一种协议,以API呈现。
一个例子:

2) Rest
RESTful风格的架构将‘资源’放在第一位,每个‘资源’都有一个URI与之对应,可以将‘资源’看着是ddd中的实体;RESTful采用具有自描述功能的消息实现无状态通信,提高系统的可用性;至于‘资源’的哪些属性可以公开出去,针对‘资源’的操作,RESTful使用HTTP协议的已有方法来实现:GET、PUT、POST和DELETE。
3) CQRS
CQRS就是平常大家在讲的读写分离,通常读写分离的目的是为了提高查询性能,同时达到读/写的解耦。
CQRS适用于极少数复杂的业务领域,如果不是很适合反而会增加复杂度;另一个适用场景为获取高性能的服务
4)事件驱动架构
事件可能有不同类型,这里主要只关心领域事件。

象不象微服务架构中引入消息中间件来解耦和最终事务一致?
5)管道和过滤器风格.
管道过滤器来源于linux命令类似 ps -ef | grep tomcat . | 即管道。ps 处理的结果经过管道符| 作为下一个命令的输入。
《实现领域驱动设计》中举了个基于事件的发布、订阅的例子来实现管道和过滤器架构风格。事件的发布订阅中心作为管道。事件的发布、订阅方作为过滤器。
推而广之,考虑基于消息中间件的管道过滤器。
8最后
1) 采用三层结构的架构风格就没有领域相关的类容了吗?
答案当然是有的,但是不象DDD这样有明确的区分。往往因为程序员没有相关概念或多多思考就容易引发问题。举个栗:
public class SearchController {
private SearchService service;
@RequestMapping(value="search")
public List search(String searchStr) {
service.search(searchStr);
}
}
public class SearchService{
public List search(String str){
if(系统变量=="solor"){
solorService.search(str)
}else {
dbService.search(str);
}
}
}
功能很强大,支持数据检索和solor检索。但是再看,solor检索和数据检索明显不是一个玩意,不应该同时出现在SearchService里。从DDD观点来看,也明显属于不同的领域实现模型。即使在同一个子域里,划分微服务那它也应该是两个微服务实现。显明扩展性不好。
2)DDD也有麻烦问题
比如要考虑根实体、值对象、实体。都不象时考虑使用领域服务类。领域服务类干脆就是贫血模血。
3)最后的最后
作为六边型架构风格的实现,看看一个开发包的结构图

controller则是适配器。
posted on 2019-07-08 16:49 傻 瓜 阅读(2729) 评论(0) 编辑 收藏