Java泛型中通配符的使用详解
目录
一、为什么要用通配符和边界?--泛型不是协变的
泛型不是协变的
类型擦除
为什么选择这种实现机制?不擦除不行么?
泛型擦除理解
JVM如何保留泛型信息
实例分析
通配符
类型系统
二、上界
三、下界
四、上下界通配符的副作用
五、PECS原则
六、一句话总结
和 是Java泛型中的 通配符 和 边界 的概念。
- :上界通配符
- :下界通配符
一、为什么要用通配符和边界?--泛型不是协变的
开发人员在使用泛型的时候,很容易根据自己的直觉而犯一些错误。比如一个方法如果接收 List
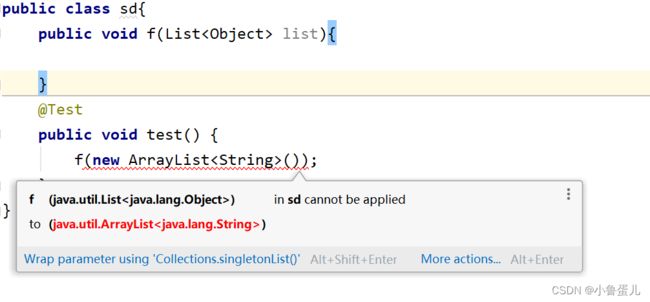
虽然从直觉上来说,Object 是 String 的父类,这种类型转换应该是合理的。但是实际上这会产生隐含的类型转换问题,因此编译器直接就禁止这样的行为。
如我们有Fruit类,和它的派生类Apple
class Fruit {}
class Apple extends Fruit {}然后有一个最简单的容器:Plate类,盘子里可以放一个泛型的”东西”
我们可以对这个东西做最简单的“放”和“取”的动作:set( )和get( )方法。
class Plate{
private T item;
public Plate(T t){item=t;}
public void set(T t){item=t;}
public T get(){return item;}
} 现定义一个“水果盘”,逻辑上水果盘当然可以装苹果。
Plate p=new Plate(new Apple()); 但实际上Java编译器不允许这个操作。会报错,“装苹果的盘子”无法转换成“装水果的盘子”。
error: incompatible types: Plate
cannot be converted to Plate
实际上,编译器认定的逻辑是这样的:
- 苹果 IS-A 水果
- 装苹果的盘子 NOT-IS-A 装水果的盘子
所以,就算容器里装的东西之间有继承关系,但容器之间是没有继承关系。
所以我们不可以把Plate
泛型不是协变的
在 Java 语言中,数组是协变的,也就是说,如果 Integer 扩展了 Number,那么不仅 Integer 是 Number,而且 Integer[] 也是 Number[],在要求 Number[] 的地方完全可以传递或者赋予 Integer[]。(更正式地说,如果 Number是 Integer 的超类型,那么 Number[] 也是 Integer[]的超类型)。
您也许认为这一原理同样适用于泛型类型 —— List< Number> 是 List< Integer> 的超类型,那么可以在需要 List< Number> 的地方传递 List< Integer>。不幸的是,情况并非如此。为啥呢?这么做将破坏要提供的类型安全泛型。
类型擦除
为什么选择这种实现机制?不擦除不行么?
在Java诞生10年后,才想实现类似于C++模板的概念,即泛型。Java的类库是Java生态中非常宝贵的财富,必须保证向后兼容(即现有的代码和类文件依旧合法)和迁移兼容(泛化的代码和非泛化的代码可互相调用)基于上面这两个背景和考虑,Java设计者采取了“类型擦除”这种折中的实现方式。
同时正有这个这么“坑”的机制,令我们无法在运行期间随心所欲的获取到泛型参数的具体类型。
泛型擦除理解
正确理解泛型概念的首要前提是理解类型擦除(type erasure)。 Java 中的泛型基本上都是在编译器这个层次来实现的。在生成的 Java 字节代码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会被编译器在编译的时候去掉。这个过程就称为类型擦除。
如在代码中定义的 List
代码测试
@Test
public void test(){
ArrayList list1 = new ArrayList<>();
ArrayList list2 = new ArrayList<>();
System.out.println(list1.getClass());
System.out.println(list2.getClass());
} 
很多泛型的奇怪特性都与这个类型擦除的存在有关,包括:
- 泛型类并没有自己独有的 Class 类对象。比如并不存在 List
.class 或是 List .class,而只有 List.class,因此在运行时无法获得泛型的真实类型信息。 - 静态变量是被泛型类的所有实例所共享的。对于声明为 MyClass
的类,访问其中的静态变量的方法仍然是 MyClass.myStaticVar。不管是通过 new MyClass 还是 new MyClass 创建的对象,都是共享一个静态变量。 - 泛型的类型参数不能用在 Java 异常处理的 catch 语句中。因为异常处理是由 JVM 在运行时刻来进行的。由于类型信息被擦除,JVM 是无法区分两个异常类型 MyException
和 MyException 的。对于 JVM 来说,它们都是 MyException 类型的。也就无法执行与异常对应的 catch 语句。
类型擦除的基本过程也比较简单,首先是找到用来替换类型参数的具体类。这个具体类一般是 Object。如果指定了类型参数的上界的话,则使用这个上界。把代码中的类型参数都替换成具体的类。同时去掉出现的类型声明,即去掉 <> 的内容。比如 T get() 方法声明就变成了 Object get();List
接下来就可能需要生成一些桥接方法。这是由于擦除了类型之后的类可能缺少某些必须的方法。比如考虑下面的代码:
class MyString implements Comparable {
public int compareTo(String str) {
return 0;
}
} 当类型信息被擦除之后,上述类的声明变成了 class MyString implements Comparable。但是这样的话,类 MyString 就会有编译错误,因为没有实现接口 Comparable 声明的 int compareTo(Object) 方法。这个时候就由编译器来动态生成这个方法。
JVM如何保留泛型信息
这个想法是这样子的,既然像ArrayList
我这个子类需要继承的父类的泛型都是已经确定了的呀,果然,JVM是有保存这部分信息的,它是保存在子类的Class信息中。
那么我们怎么获取这部分信息呢?还好,Java有提供API出来
public class TestMethod {
@Test
public void test1(){
Student student = new Student();
/**
* getGenericSuperclass()获得带有泛型的父类
* Type是 Java 编程语言中所有类型的公共高级接口。它们包括原始类型、参数化类型、数组类型、类型变量和基本类型。
*/
Type mySuperClass = student.getClass().getGenericSuperclass();
Type type = ((ParameterizedType) mySuperClass).getActualTypeArguments()[0];
System.out.println(type);
}
}
class Student extends ArrayList>{
} 概括来说就是对于带有泛型的class,返回一个ParameterizedType对象,对于Object、接口和原始类型返回null,对于数组class则是返回Object.class。
ParameterizedType是表示带有泛型参数的类型的Java类型,JDK1.5引入了泛型之 后,Java中所有的Class都实现了Type接口,ParameterizedType则是继承了Type接口,所有包含泛型的Class类都会实现 这个接口。
实例分析
了解了类型擦除机制之后,就会明白编译器承担了全部的类型检查工作。编译器禁止某些泛型的使用方式,正是为了确保类型的安全性。以上面提到的 List
public void inspect(List这段代码中,inspect 方法接受 List
假设这样的做法是允许的,那么在 inspect 方法就可以通过 list.add(1) 来向集合中添加一个数字。这样在 test 方法看来,其声明为 List
编译器会尽可能的检查可能存在的类型安全问题。对于确定是违反相关原则的地方,会给出编译错误。当编译器无法判断类型的使用是否正确的时候,会给出警告信息。
为了让泛型用起来更舒服,Sun的大师们就想出了和的办法,来让”水果盘子“和”苹果盘子“之间发生正当关系。
通配符
在使用泛型类的时候,既可以指定一个具体的类型,如 List
通配符所代表的其实是一组类型,但具体的类型是未知的。
List 所声明的就是所有类型都是可以的。但是 List 并不等同于 List
List如果它包含了 String 的话,往里面添加 Integer 类型的元素就是错误的。
正因为类型未知,就不能通过 new ArrayList() 的方法来创建一个新的 ArrayList 对象。因为编译器无法知道具体的类型是什么。但是对于 List 中的元素确总是可以用 Object 来引用的,因为虽然类型未知,但肯定是 Object 及其子类。
考虑下面的代码:
public void wildcard(List list) {
list.add(1);// 编译错误
} 如上所示,试图对一个带通配符的泛型类进行操作的时候,总是会出现编译错误。其原因在于通配符所表示的类型是未知的。
?”不能添加元素,只能作为消费者
因为对于 List 中的元素只能用 Object 来引用,在有些情况下不是很方便。在这些情况下,可以使用上下界来限制未知类型的范围。 如 List 说明 List 中可能包含的元素类型是 Number 及其子类。而 List 则说明 List 中包含的是 Number 及其父类。当引入了上界之后,在使用类型的时候就可以使用上界类中定义的方法。比如访问 List 的时候,就可以使用 Number 类的 intValue 等方法。
类型系统
在 Java 中,大家比较熟悉的是通过继承机制而产生的类型体系结构。比如 String 继承自 Object,当需要 Object 类的引用的时候,如果传入一个 String 对象是没有任何问题的。但是反过来的话,即用父类的引用替换子类引用的时候,就需要进行强制类型转换。编译器并不能保证运行时刻这种转换一定是合法的。这种自动的子类替换父类的类型转换机制,对于数组也是适用的(数组是协变的)。 String[] 可以替换 Object[]。但是泛型的引入,对于这个类型系统产生了一定的影响。正如前面提到的 List
引入泛型之后的类型系统增加了两个维度:一个是类型参数自身的继承体系结构,另外一个是泛型类或接口自身的继承体系结构。第一个指的是对于 List
- 相同类型参数的泛型类的关系取决于泛型类自身的继承体系结构。即 List
是 Collection 的子类型,List 可以替换 Collection 。这种情况也适用于带有上下界的类型声明。 - 当泛型类的类型声明中使用了通配符的时候, 其子类型可以在两个维度上分别展开。如对 Collection 来说,其子类型可以在 Collection 这个维度上展开,即 List 和 Set 等;也可以在 Number 这个层次上展开,即 Collection
和 Collection 等。如此循环下去,ArrayList 和 HashSet 等也都算是 Collection 的子类型。 - 如果泛型类中包含多个类型参数,则对于每个类型参数分别应用上面的规则。
理解了上面的规则之后,就可以很容易的修正实例分析中给出的代码了。只需要把 List
二、上界
下面就是上界通配符
Plate<? extends Fruit>一个能放水果以及一切是水果派生类的盘子
Plate<? extends Fruit>和Plate
直接的好处就是,我们可以用“苹果盘”给“水果盘”赋值了。
Plate p=new Plate(new Apple()); 再扩展一下,食物分成水果和肉类,水果有苹果和香蕉,肉类有猪肉和牛肉,苹果还有两种青苹果和红苹果。
//Lev 1
class Food{}
//Lev 2
class Fruit extends Food{}
class Meat extends Food{}
//Lev 3
class Apple extends Fruit{}
class Banana extends Fruit{}
class Pork extends Meat{}
class Beef extends Meat{}
//Lev 4
class RedApple extends Apple{}
class GreenApple extends Apple{}在这个体系中,上界通配符Plate<? extends Fruit>覆盖下图中蓝色的区域。

三、下界
相对应的下界通配符
Plate表达的就是相反的概念:一个能放水果以及一切是水果基类的盘子。
Plate<? super Fruit>是Plate
对应刚才那个例子,Plate<? super Fruit>覆盖下图中红色的区域。

四、上下界通配符的副作用
边界让Java不同泛型之间的转换更容易了。但不要忘记,这样的转换也有一定的副作用。那就是容器的部分功能可能失效。
还是以刚才的Plate为例。我们可以对盘子做两件事,往盘子里set( )新东西,以及从盘子里get( )东西。
class Plate{
private T item;
public Plate(T t){item=t;}
public void set(T t){item=t;}
public T get(){return item;}
} 1、上界不能往里存,只能往外取
- 会使往盘子里放东西的set( )方法失效,但取东西get( )方法还有效
- 取出来的东西只能存放在Fruit或它的基类里面,向上造型。
比如下面例子里两个set()方法,插入Apple和Fruit都报错。
Plate p=new Plate(new Apple());
//不能存入任何元素
p.set(new Fruit()); //Error
p.set(new Apple()); //Error
//读取出来的东西只能存放在Fruit或它的基类里。
Fruit newFruit1=p.get();
Object newFruit2=p.get();
Apple newFruit3=p.get(); //Error 编译器只知道容器内是Fruit或者它的派生类,但具体是什么类型不知道,因此取出来的时候要向上造型为基类。
通俗理解:
我们给这两个盘子贴标签,上面写着(本盘子为装食物的盘子:Plate),编号为plate1、plate2:
Plate plate1 = new Plate();
Plate plate2 = new Plate(); 此时,有人使用这两个盘子,他根据标签只知道这两个都是食物的盘子,他有下面的行为:
- 他想要从盘子中拿出Food(get),他随便拿两个盘子中的任意一个,都获得了Food。
- 他想存放一个Apple(put),他走到box2前面,但是box2是装肉的盘子,所有他放Apple进去失败了。
2、下界不影响往里存,但往外取只能放在Object对象里
- 使用下界会使从盘子里取东西的get( )方法部分失效,只能存放到Object对象里。
- 因为规定的下界,对于上界并不清楚,所以只能放到最根本的基类Object中
Plate p=new Plate(new Fruit());
//存入元素正常
p.set(new Fruit());
p.set(new Apple());
//读取出来的东西只能存放在Object类里。
Apple newFruit3=p.get(); //Error
Fruit newFruit1=p.get(); //Error
Object newFruit2=p.get(); 因为下界规定了元素的最小粒度的下限,实际上是放松了容器元素的类型控制。既然元素是Fruit的基类,那往里存粒度比Fruit小的都可以。
但往外读取元素就费劲了,只有所有类的基类Object对象才能装下。但这样的话,元素的类型信息就全部丢失。
通俗理解:
假如我们还有可以装水果的盘子,上面的标签是(本盘子为装RedApple或者苹果父类的盘子:Plate ),编号plate3:
Plate plate3 = new Plate(); 此时,有人想用这个盘子,他根据标签只知道这个盘子是装RedApple或者RedApple父类的盘子,他有以下行为:
- 他想从箱子里面拿东西(Get),但拿出来了一个Meat,但他之前没见过Meat,很迷惑,这个世界上竟然有Meat,能吃吗。
- 他想放一个RedApple到这个箱子,于是放进去了。他想放一个GreenApple,也放进去了。
五、PECS原则
PECS原则的全拼是"Producer Extends Consumer Super"。
当需要频繁取值,而不需要写值则使用 " ? extends T " 作为数据结构泛型。即extends 可用于返回类型限定,不能用于参数类型限定。
相反,当需要频繁写值,而不需要取值则使用 " ? super T " 作为数据结构泛型。 super 可用于参数类型限定,不能用于返回类型限定。
六、一句话总结
确定了上界为T,那么获取值时类型一定是T或T的父类,但赋值时由于不能确定具体是T或者T的某个子类而赋值失败。
确定了下界为T,那么在获取值时不确定类型是T或T的哪个父类,只能用Object接收,使得类型信息丢失,但赋值时只要为T或T的子类都可以。
参考文章:Java泛型解惑之 extends T>和 super T>上下界限_yaoshengting的博客-CSDN博客_泛型extends
Java 泛型 <? super T> <? extend T> 的通俗理解_水心可乐的博客-CSDN博客