数据结构与算法之美(十三)字符串匹配算法
目录
- 字符串匹配算法介绍
- 字符串匹配算法分类
- BF算法
- RK算法
-
- 思考题
- BM算法
-
- 坏字符规则
- 好后缀规则
- KMP算法
-
- 好前缀规则
- Trie树
- AC自动机
字符串匹配算法介绍
字符串匹配算法就是将从一个字符串(主串,长度为n)中匹配出指定的字符串(模式串,长度为m)。字符串查找函数比如Python中的find()函数、word里的查找替换等,底层依赖的就是字符串匹配算法。
字符串匹配算法分类
- 单模式串匹配:在一个字符串中查找一个字符串
- 简单、低效:BF算法、RK算法
- 难理解、高效:BM算法、KMP算法
- 多模式串匹配:
- Trie树:在多个字符串中同时查找一个(同前缀的)字符串,适用于搜索关键词提示、自动插入补全
- AC自动机:在一个字符串中同时查找多个字符串,适用于敏感词过滤
BF算法
BF算法全称Brute Force算法,又叫作暴力匹配算法、朴素匹配算法。
BF算法就是在主串中,检查起始位置分别是0、1、2 … n-m且长度为m的n-m+1个子串,看有没有跟模式串匹配的。
最坏时间复杂度: O ( n ∗ m ) O(n*m) O(n∗m)
适用范围:模式串和主串长度都不太长的实际软件开发中。
RK算法
RK算法全称Rabin-Karp算法,是BF算法的升级版,比较的是子串和模式串的哈希值,而不需要逐个字符比对。具体的,通过哈希算法,对主串中的n-m+1个子串分别求哈希值,然后逐个与模式串的哈希值比较,如果某个子串的哈希值与模式串相等,就说明匹配上了。
不过通过哈希算法计算子串的哈希值时,需要遍历子串中的每个字符,尽管模式串与子串比较的效率提高了,但是算法的整体效率并没有提高,有什么办法可以提高哈希算法计算子串哈希值的效率呢?
假设要主串的字符集只包含K个字符,就可以用K进制数来表示一个子串,把这个K进制数转化成十进制数,作为子串的哈希值,例如:

这样有个好处,相邻的两个子串s[i-1]和s[i]有重叠的部分,s[i]的哈希值可以通过s[i-1]的哈希值很快计算出来:
另外, 2 6 0 26^0 260、 2 6 1 26^1 261、 2 6 2 26^2 262、… 、 2 6 ( m − 1 ) 26^(m-1) 26(m−1)可以预先计算后存到一个长度为m的数组里,下标分别为0、1、2、…、m-1,用的时候可以查表。
如果主串和模式串比较长,上面的哈希算法会得到很大的哈希值,超出整型的表示范围,这时可以牺牲一下允许哈希冲突。在存在哈希冲突的情况下,如果子串和模式串的哈希值相等,还需要再比对一下子串和模式串自身。
时间复杂度: O ( n ) O(n) O(n) = 哈希值计算 O ( n ) O(n) O(n) + 比较 O ( n ) O(n) O(n)
最坏时间复杂度:如果存在大量哈希冲突,就会退化成 O ( m ∗ n ) O(m*n) O(m∗n)
思考题
如何在一个二维字符串矩阵中,查找另一个二维字符串矩阵呢?
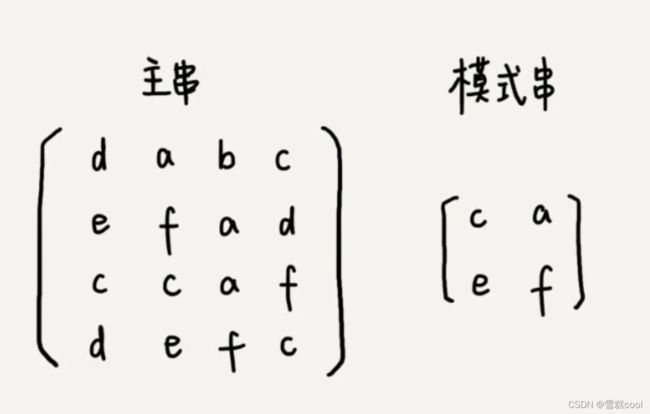
计算主串中2*2子串的哈希值,与模式串的哈希值比对。
BM算法
BM算法全称是Boyer-Moore算法,是一种非常高效的字符串匹配算法,性能是KMP算法的3到4倍,是最高效、最常用的字符串匹配算法。BM算法的思路是,当模式串与主串某个字符不匹配时,能够跳过一些肯定不会匹配的情况,将模式串往后多滑动几位。
BM算法包含两部分:坏字符规则(bad character rule)、好后缀规则(good suffix shift),取两个数中最大的,作为模式串往后滑动的位数。这样可以避免仅用坏字符规则结果为负的情况。但这样不会漏吗?不会,因为两个都已经是各自满足条件的最小距离了,如果取较小那一个,另一个一定不满足条件。
BM算法最好情况时间复杂度是 O ( n / m ) O(n/m) O(n/m),最坏情况时间复杂度是 O ( n ) O(n) O(n)。
坏字符规则
- 从模式串的末尾往前倒着匹配,当发现某个字符没法匹配的时候,把这个主串中没有匹配的字符叫做坏字符。
- 拿坏字符在模式串中查找:
- 如果发现模式串中并不存在这个字符,就将模式串直接向右滑动m位(也即记xi=-1),因为这个坏字符跟模式串中任何字符都不可能匹配;
- 如果发现模式串中存在这个字符(取最靠后的那个,这样不会滑动过多,导致漏匹配),就将模式串往后滑动si-xi位来对齐主串和模式串中的这个字符,si是坏字符对应位置的模式串中的下标,xi是坏字符在模式串中的下标。
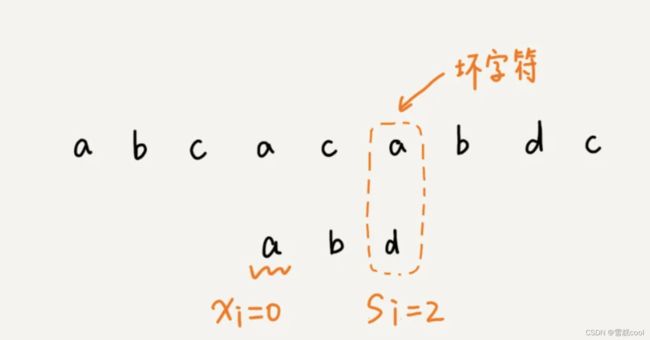
单纯用坏字符规则会产生badcase,例如对于主串aaaaaaaa,模式串baaa,不但不会往后滑动,还可能倒退,所以还需要用到好后缀规则。
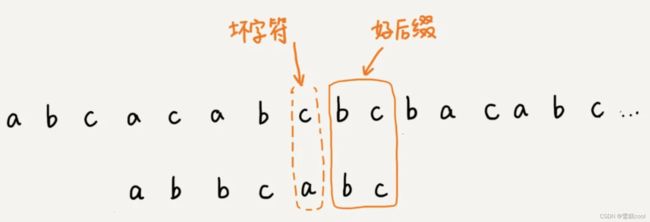
好后缀规则
- 坏字符后面已经匹配的主串里的字符叫作好后缀;
- 拿好后缀在模式串中查找,
- 如果找到了其他相匹配的子串,就将模式串滑动到匹配子串对齐的位置;
- 如果在模式串中找不到其他相匹配的子串,直接滑动到好后缀后面的话可能会导致漏过,要考虑好后缀的后缀子串是否跟模式串的前缀子串相匹配:
- 如果有一个或多个子串相匹配,就滑动到与最长的好后缀的后缀子串相匹配的位置;
- 如果没有,就直接滑动到好后缀后面。

KMP算法
KMP算法全称Knuth Morris Pratt算法,是字符串匹配算法中最知名的一种,但不太可能自己亲手实现一个KMP算法,主要思路跟BM算法非常接近,也是找到可以将模式串往后多滑动几位的规律。
KMP算法包含两部分:坏字符规则(bad character rule)、好前缀规则(good prefix shift)。
KMP算法的时间复杂度是 O ( m + n ) O(m+n) O(m+n)。
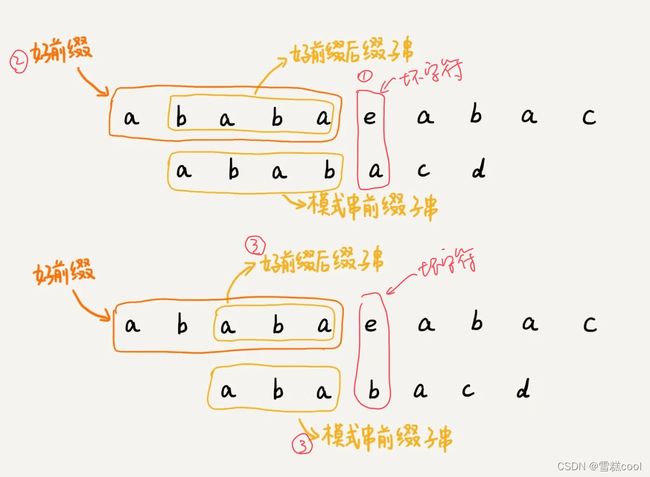
好前缀规则
- 坏字符前面已经匹配的主串里的字符叫作好前缀;
- 用(主串)好前缀的后缀子串(叫作最长可匹配后缀子串),查找模式串中好前缀的能匹配上的最长的前缀子串(叫作最长可匹配前缀子串)。
Trie树
Trie树又叫字典树,是一个树形结构,适合在多个字符串中查找与模式串前缀匹配的字符串,常见应用是搜索关键词提示、自动输入补全等功能。
思路:用各主串的字符串的公共前缀构建字符树,以减少重复查找。
结构:Trie树是一个多叉树。根节点不包含任何信息,每个节点表示一个字符,从根节点到红色节点(不一定是叶子节点)的一条路径表示一个字符串。

构造过程:字符串的插入。时间复杂度是 O ( n ) O(n) O(n),n表示多有字符串的长度和。

查找过程:从根节点开始,沿着某条路径来匹配,如果路径的最后一个节点是红色的就可以匹配,如果最后一个节点不是红色的则不能匹配。时间复杂度是 O ( k ) O(k) O(k),k是要查询的字符串的长度。
存储:多叉树的指针可以用vector
如果是在多个字符串中查找与模式串精确匹配的字符串,而不是前缀匹配的字符串,则更适合看作一个数据查找问题,用散列表、红黑树、跳表来实现,原因是,对于Trie树:
- 要求字符集不能太大,不然存储空间可能会浪费很多
- 要求字符串得前缀重合的比较多,不然空间消耗会很大
- 工程上需要从零实现,没有现成的类库
- 用到了指针、数据块是不连续的,对缓存不友好
AC自动机
AC自动机算法,全称是Aho-Corasick算法,用于在单个主串里查找多个模式串的场景,可应用在敏感词过滤上。AC自动机实际上就是在Trie树之上,加了类似KMP的next数组,让匹配失败时,尽可能将模式串往后多滑动几位。
AC自动机的构建:
- 将多个模式串(例如过个敏感词)构建成Trie树;
- 在Trie树上构建失败指针(相当于KMP中的失效函数next数组)。