Hadoop大数据技术原理与运用学习笔记
Hadoop学习过程中的一些笔记
参考书籍《Hadoop大数据技术原理与应用》清华大学出版社 黑马程序员/编著
1.什么是大数据?大数据的四个特征是什么?
答:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合
具有海量数据规模、快速数据流转、多样数据类型一级价值密度四大特征。
2.另外,在Hadoop架构里面,元数据的含义是什么?
答:文件的大小、位置、权限
3.本书里面使用的Hadoop是哪个发行版本?
答:apache版本,优点:版本更迭快; 缺点:更迭快带来的版本维护、兼容性、补丁不周到。
4.在1.x版本中,namenode和datanode作用?
答:namenode:集群中的主节点,管理元数据,主要用于管理集群中的各种数据;
datanode:集群当中的从节点,主要用于储存集群当中的各种数据。
配置集群时的一些命令:
ssh-keygen -t rsa //启用ssh
ssh-copy-id hadoop01
chkconfig iptables off //关防火墙
mac地址文件
# vi /etc/udev/rules.d/70-persistent-net.rules
第三章HDFS
Hadoop的核心是HDFS和MapReduce。其中,HDFS是解决海量大数据文件存储的问题,是目前应用最广泛的分布式文件系统。
HDFS 源于 Google 在2003年10月份发表的GFS(Google File System)论文。
解决传统文件储存瓶颈问题--》纵向扩容:加磁盘和内存。横向扩容:增加服务器数量。
基本概念:HDFS(Hadoop Distributed Filesystem)是一个易于扩展的分布式文件系统,运行在成百上千台低成本的机器上。它与现有的分布式文件系统有许多相似之处,都是用来存储数据的系统工具,而区别于HDFS具有高度容错能力,旨在部署在低成本机器上。HDFS主要用于对海量文件信息进行存储和管理,也就是解决大数据文件(如TB乃至PB级)的存储问题。
Namenode:NameNode是HDFS集群的主服务器。一旦NameNode关闭,就无法访问Hadoop集群。NameNode主要以元数据的形式进行管理和存储,用于维护文件系统名称并管理客户端对文件的访问;NameNode记录对文件系统名称空间或其属性的任何更改操作;HDFS负责整个数据集群的管理,并且在配置文件中可以设置备份数量,这些信息都由NameNode存储。
Datanode:DataNode是HDFS集群中的从服务器。文件系统存储文件的方式是将文件切分成多个数据块,这些数据块实际上是存储在DataNode节点中的,因此DataNode机器需要配置大量磁盘空间。它与NameNode保持不断的通信,DataNode在客户端或者NameNode的调度下,存储并检索数据块,对数据块进行创建、删除等操作,并且定期向NameNode发送所存储的数据块列表。
Block:每个磁盘都有默认的数据块大小,这是磁盘进行数据读/写的最小单位,HDFS同样也有块(block)的概念,它是抽象的块,而非整个文件作为存储单元,在Hadoop2.x版本下,默认大小是128M,且备份3份,每个块尽可能地存储于不同的DataNode中。按块存储的好处主要是屏蔽了文件的大小,提供数据的容错性和可用性。
Rack:是用来存放部署Hadoop集群服务器的机架,不同机架之间的节点通过交换机通信,HDFS通过机架感知策略,使NameNode能够确定每个DataNode所属的机架ID,使用副本存放策略,来改进数据的可靠性、可用性和网络带宽的利用率。
元数据:元数据从类型上分可分三种信息形式,一是维护HDFS文件系统中文件和目录的信息,二是记录文件内容存储相关信息,三是用来记录HDFS中所有DataNode的信息,用于DataNode管理。
HDFS优缺点
优点:高容错、流式数据访问、支持超大文件高数据、吞吐量
缺点:高延迟、不适合小文件存取、不适合并发写入
HDFS的架构和原理
HDFS存储架构
HDFS采用主从架构(Master/Slave架构)。HDFS集群是由一个NameNode和多个的 DataNode组成。
HDFS文件读写原理:Client(客户端)对HDFS中的数据进行读写操作,分别是Client从HDFS中查询数据,即Read(读)数据;Client从HDFS中存储数据,即为Write(写)数据。
HDFS写数据原理HD
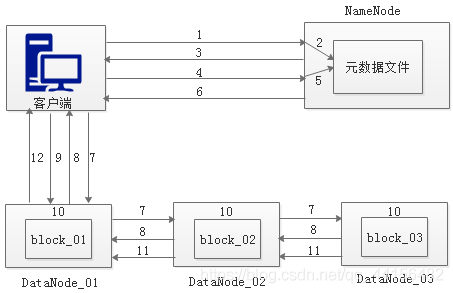
- 客户端发起上传文件请求,通过RPC (远程过程调用)与NameNode建立通讯。
- NameNode检查元数据文件的系统目录树。
- 若系统目录树的父目录不存在该文件相关信息,返回客户端可以上传文件。
- 客户端请求上传第一个Block数据块以及数据块副本的数量。
- NameNode检测元数据文件中DataNode信息池,找到可用的数据节点。
- NameNode检查元数据文件的系统目录树。
- 若系统目录树的父目录不存在该文件相关信息,返回客户端可以上传文件。
- DataNode之间建立Pipeline后,逐个返回建立完毕信息。
- 客户端与DataNode建立数据传输流,开始发送数据包。
- 客户端向DataNode_ 01.上传第一个Block数据块, 当DataNode_ _01收到一个Packet就会传给DataNode 02,DataNode_ 02传给DataNode_ 03,DataNode 01每传送一个Packet都会放入一个应答队列等待应答。
- 数据被分割成一个个Packet数据包在Pipeline. 上依次传输,而在Pipeline反方向上,将逐个发送Ack,最终由Pipeline中第- -个DataNode节点DataNode 01将Pipeline的Ack信息发送给客户端。
- DataNode返回给客户端,第一个Block块传输完成。客户端则会再次请求NameNode.上传第二-个Block块和第三块到服务器上,重复上面的步骤,直到3个Block都.上传完毕。
HDFS读数据原理

- 客户端向NameNode发起RPC请求,来获取请求文件Block数据块所在的位置。
- NameNode检测元数据文件,会视情况返回Block块信息或者全部Block块信息,对于每个Block块,NameNode都会返回含有该Block副本的DataNode地址。
- 客户端会选取排序靠前的DataNode来依次读取Block块,每一个Block都会进行CheckSum若文件不完整,则客户端会继续向NameNode获取下一-批的Block列表,直到验证读取出来文件是完整的,则Block读取完毕。
- 客户端会把最终读取出来所有的Block块合并成一个完整的最终文件(例如: 1.txt) 。
第四章MapReduce
1.MapReduce核心思想:“分而治之”
Map阶段:任务分解(小任务之间没有必然的依赖关系,可以单独执行)
Reduce阶段:合并任务,把Map阶段的结构进行全局汇总。
2.MapReduce编程模型
处理大规模数据集并行运算。借鉴函数式程序设计语言思想进行,分为
Map()和Reduce()两个函数
编程实列--词频统计

3.MapReduce工作原理
- 分片、格式化数据源
分片:将源文件划分为大小相等的小数据块(默认128M),Hadoop会为每个分片构建一个Map任务-->执行自定义map()函数,来处理切片每条记录;
格式化:
- 执行MapTask(四个阶段)
Map任务有一个内存缓冲区(100M),分片数据经过Map任务的中间数据会写入,达到阈值(80M)启动一个线程,写入磁盘,在溢写过程中,MapReduce会对Key进行排序,如果中间结果比较大会形成多个溢写文件----》最后合并为一个;
①Read阶段:MapTask通过RecordReder类,从输入的InputSplit中解析出一个个Key/value
②Map阶段:将解析出的键值对交给map()函数处理,产生一系列新的key/value
③Collect阶段:map()处理完后一般调用outputCollector.collect()输出结果,在函数内部,生成新的key/value分片(通过调用partitioner),并写入环形内存缓冲区
④Spill阶段:溢写,环形内存缓冲区满后,写入磁盘(这之前进行本地排序,必要是对数据合并、压缩的操作),生成临时文件,
⑤Combiner阶段:最终合并

- 执行Shuffle过程
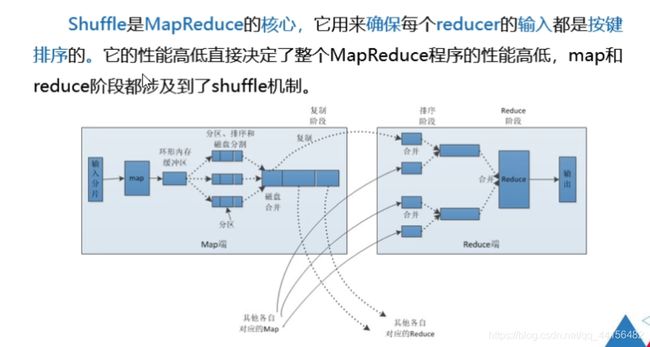
Shuffle工作原理
Map阶段
(1) MapTask处理的结果会暂且放人一个内存缓冲区中(该缓冲区默认大小是100MB) ,当缓冲区快要溢出时(默认达到缓冲区大小的80%),会在本地文件系统创建一个溢出文件,将该缓冲区的数据写入这个文件。
(2)写盘之前,线程会根据reduceTask的数量,将数据分区,一个Reduce任务对应一个分区的数据。这样做能避免有些reduce任务分配到大量数据,而有些reduce任务分到很少的数据,甚至没有分到数据的情况。
(3)分完数据后,排序每个分区的数据,如果设置了Combiner,将会对排序后的结果进行Combine操作,这样做能尽可能少地执行数据写盘的操作。
(4)当Map任务输出最后一个记录时,可能有很多溢出文件,这时需要将这些文件合并,合并的过程中会不断地进行排序和Combine操作,其目的有两个:一是尽量减少每次写盘的数据量;二是尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。
Reduce阶段
(1) Reduce 会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果Reduce阶段接收的数据量相当小,则直接存储在内存中,如果数据量超过了该缓冲区大小的一定比例,则对数据合并后溢写到磁盘中。
(2)随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。
(3)合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后- -次合并的结果并没有写人磁盘,而是直接输人到reduce函数。
- ReduceTask原理
①Copy阶段:Reduce从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
②Merge阶段:在远程复制数据的同时,ReduceTask会启动两个后台线程,分别对内存和磁盘上的文件进行合并,以防止内存使用过多或者磁盘文件过多。
③Sort阶段:用户编写reduce()方法输人数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
④Reduce阶段:对排序后的键值对调用reduce()方法,键相等的键值对调用一次reduce()方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写人到HDFS中。
⑤Write阶段:reduce()函数将计算结果写到HDFS上。
- 写入文件
传入OutputFormat

第五章 Zookeeper
Apache Zookeeper旨在减轻构建健壮的分布式系统的服务。Zookeeper是基于分布式计算的核心概念而设计的,主要目的是给开发人员提供一套容易理解和开发的接口,从而简化分布式系统构建的服务。
Zookeeper是一个分布式协调服务的开源框架,它是由Google的Chubby开源实现。Zookeeper主要用来解决分布式集群中应用系统的一致性问题和单点故障问题
Zookeeper特性
Zookeeper具有全局数据一致性、可靠性、顺序性、原子性以及实时性,可以说Zookeeper的其他特性都是为满足Zookeeper全局数据一致性这一特性。
Zookeeper集群角色
Zookeeper集群是一个主从集群,它一般是由一个Leader(领导者)和多个Follower(跟随者)组成。此外,针对访问量比较大的Zookeeper集群,还可新增Observer(观察者)。Zookeeper集群中的三种角色各司其职,共同完成分布式协调服务。

Leader:事务性请求(写操作)唯一调度者和处理者保证事务处理顺序性,负责进行投票的发起和决议,以及更新系统状态。
Follower:处理客服端非事务性(读操作)请求,接送事务性请求给leader处理,参与投票。
Observer:观察zookeeper集群最新状态变化,并将状态同步,可独自处理非事务性请求,事务性请求给leader处理
数据模型
Zookeeper是由节点组成的树,树中的每个节点被称为—Znode。每个节点都可以拥有子节点。每一个Znode默认能够存储1MB的数据(小数据),每个Znode都可以通过其路径唯一标识。
Zookeeper数据模型中每个Znode都是由三部分组成,分别是stat(信息)、data、children(子节点)。
Znode的类型在创建时被指定,一旦创建就无法改变。
Znode有两种类型
临时节点:该生命周期依赖于创建它们的会话,一旦会话结束,临时节点将会被自动删除,也可以手动删除。虽然每个临时的Znode都会绑定一个客户端,但它们对所有的客户端还是可见的。需要注意的是临时节点不允许拥有子节点。
永久节点:该生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,它们才能被删除。
Znode的属性
| 属性名称 |
相关说明 |
| czxid |
节点被创建的时间 |
| ctime |
节点最后一次的修改的Zxid值 |
| mzxid |
节点最后一次的修改时间 |
| mtime |
与该节点的子节点最后一次修改的Zxid值 |
| pZxid |
子节点被修改的版本号 |
| cversion |
节点被创建的时间 |
| 属性名称 |
相关说明 |
| dataVersion |
数据版本号 |
| aclVersion |
ACL版本号 |
| ephemeralOwner |
如果此节点为临时节点,那么该值代表这个节点拥有者的会话ID;否则值为0 |
| dataLength |
节点数据域长度 |
| numChildren |
节点拥有的子节点个数 |
Zookeeper的Watcher机制
在ZooKeeper中,引入了Watch机制来实现这种分布式的通知功能。ZooKeeper允许客户端向服务端注册一个Watch监听,当服务端的一些事件触发了这个Watch,那么就会向指定客户端发送一个事件通知,来实现分布式的通知功能。
Watch机制的特点
一次性触发、事件封装、异步发送、先注册再触发
Watch机制的通知状态和事件类型

Zookeeper的选举机制
Zookeeper为了保证各节点的协同工作,在工作时需要一个Leader角色,而Zookeeper默认采用FastLeaderElection算法,且投票数大于半数则胜出的机制。
服务器ID:设置集群myid参数时,参数分别为服务器1、服务器2、服务器3,编号越大FastLeaderElection算法中权重越大。
选举ID:选举过程中,Zookeeper服务器有四种状态,分别为竞选状态、随从状态、观察状态、领导者状态。
数据ID:是服务器中存放的最新数据版本号,该值越大则说明数据越新,在选举过程中数据越新权重越大。
逻辑时钟:逻辑时钟被称为投票次数
选举机制的类型
假设有5台编号分别是1 ~ 5的服务器,全新集群选举过程如下:
全新集群选举:
步骤1:服务器1启动,先给自己投票;其次,发投票信息,由于其它机器还没有启动所以它无法接收到投票的反馈信息,因此服务器的状态一直属于竞选状态。
步骤2:服务器2启动,先给自己投票;其次,在集群中启动Zookeeper服务的机器发起投票对比,它会与服务器1交换结果,由于服务器2编号大,服务器2胜出,服务器1会将票投给服务器2,此时服务器2的投票数并没有大于集群半数,两个服务器状态依旧是竞选状态。
步骤3:服务器3启动,先给自己投票;其次,与之前启动的服务器1、2交换信息,服务器3的编号最大,服务器3胜出,服务器1、2会将票投给服务器3,此时投票数正好大于半数,所以服务器3成为领导者状态,服务器1、2成为追随者状态。
步骤4:服务器4启动,先给自己投票;其次,与之前启动的服务器1、2、3交换信息,尽管服务器4的编号大,但是服务器3已经胜,所以服务器4只能成为追随者状态。
步骤5:服务器5启动,同服务器4-样,均成为追随者状态。
非全新集群选举:
步骤1:统计逻辑时钟是否相同,逻辑时钟小,则说明途中可能存在宕机问题,
因此数据不完整,那么该选举结果被忽略,重新投票选举。
步骤2:统一逻辑时钟后,对比数据ID值,数据ID反应数据的新旧程度,因此
数据ID大的胜出。
步骤3:如果逻辑时钟和数据ID都相同的情况下,那么比较服务器ID (编号) ,
值大则胜出。