Service mesh 原理与实践(十八)- 如何在 Istio 中实现微服务的可观测性
云世 公众号
今天要和你分享的内容是:在 Istio 中如何利用 Metrics、Trace、Log 等组件做到服务的可观测性。在前面的章节中,已经介绍过可观测性中的 Metrics 和 Trace 的相关原理,这一讲就不再重复了,下面我们分别学习如何在 Istio 中实现 Metrics、Trace 以及 Log。
我们先从 Metrics 开始学习。
Metrics 指标
在开始这部分内容之前,先通过命令确认你是否安装了 Prometheus 和 Grafana:
$ kubectl -n istio-system get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEgrafana ClusterIP 10.108.76.683000/TCP 92m istio-egressgateway ClusterIP 10.103.64.24680/TCP,443/TCP,15443/TCP 26h istio-ingressgateway LoadBalancer 10.108.98.172 127.0.0.1 15021:31530/TCP,80:31636/TCP,443:31905/TCP,31400:31942/TCP,15443:32337/TCP 26histiod ClusterIP 10.109.14.17115010/TCP,15012/TCP,443/TCP,15014/TCP,853/TCP 26h kiali ClusterIP 10.110.51.25120001/TCP,9090/TCP 92m prometheus ClusterIP 10.106.46.629090/TCP 92m tracing ClusterIP 10.100.200.12280/TCP 92m zipkin ClusterIP 10.100.85.639411/TCP
【了解更多DDD系列课程,搜索 云世 公众号获取】
如果你学习了前面的内容,应该发现 Prometheus 和 Grafana 是安装过的,如果没有安装,请参考第 14 讲的可观测性部署部分,重新安装。
Prometheus
我们先来启动 Prometheus 的图形界面:
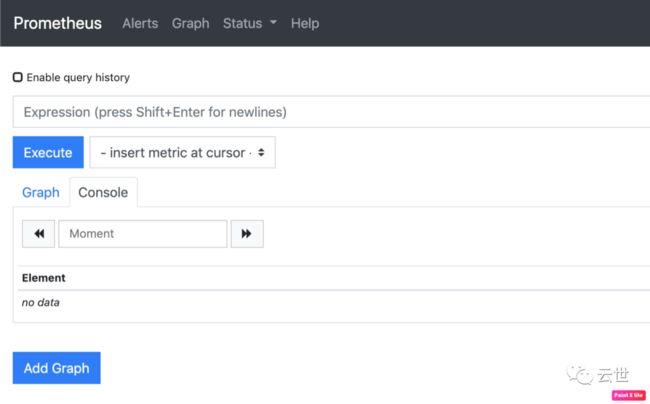
istioctl dashboard prometheus2,这个命令会帮我们打开 Prometheus 的 Web 界面,如下图:

3,让我们尝试输入一些 Envoy 突出的 Metrics,在 Prometheus 中查询:
istio_requests_total{connection_security_policy!="mutual_tls", destination_service=~"reviews.default.svc.cluster.local", reporter="source"}[5m]4,切换到 Console 界面,可以查看一些输出信息,说明信息被正确采集:

至此,Prometheus 的数据采集验证工作就完成了,你可以看到 Prometheus 自带的 Web UI 比较简陋,所以我们需要引入第三方的图形化展示工具,也就是上面提到的 Grafana,下面我们学习在 Istio 中如何使用 Grafana 更好地展示 Prometheus 采集的数据指标。
Grafana
1,Grafna 的启动方式也很简单,和 Prometheus 类似:
$ istioctl dashboard grafana2,Istio 也为我们自动地在本地打开了 Grafana 的界面,如下图:
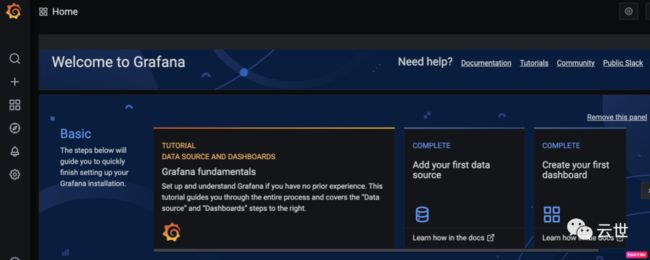
这里我们需要手动在浏览器输入http://localhost:3000/dashboard/db/Istio-mesh-dashboard 并访问,可以直接看到 Istio 管理的服务列表信息。

你可以看到很多信息指标为空。此时我们通过在浏览器中反复访问 http://127.0.0.1/productpage 页面,让指标丰富起来。然后继续观察 istio-mesh-dashboard 看板,可以发现 p50、p90、p99 等延时指标。

【了解更多DDD系列课程,搜索 云世 公众号获取】
可以点击到任意链接进入子页面,下面我们进入 Service 页面,查看某个 Service 的具体信http://localhost:3000/d/LJ_uJAvmk/istio-service-dashboard?orgId=1&refresh=10s),可以看到如下界面:

由于空间有限,这里的展示就不放出全部截图了,但是这些指标表明了整个服务的健康状态,非常关键,下面针对几个关键的参数和指标进行讲解。
Service Dashboard参数解释:
在页面的最上方,有几个选项,可以选择我们需要的参数。
-
Service:服务名,这里的服务名就是我们在 Kubernetes 中要访问的服务名,比如 details.default.svc.cluster.local。Bookinfo 这个项目所包含的几个微服务,都可以在这里选择。
-
Client Workload Namespace(Or Service Workload Namespace):这里指的是 Kubernetes 的 namespace 命名空间,也就是服务创建在了哪个命名空间。这里应用类型的服务都创建在了 default 的命名空间,只有 istio-ingressgateway 创建了 istio-system 的命名空间。
-
Client Workload:可以理解为当前 Service 的 upstream,也就是 Client 调用端。我们默认选中了 details.default.svc.cluster.local 这个服务,查看 Client Workload 的下拉框可以看到 productpage-v1 的选项,这说明 details.default.svc.cluster.local 这个服务的流量来源是 productpage 的 v1 版本。如果这里有多个选项,我们也可以选中其中一个进行查看,通过观察不同的流量来源,在出现问题的时候可以很好地区分到底是哪个流量来源的问题,便于排查问题的根因。
这也是 Istio 这样的 Service Mesh 解决方案,对比传统微服务解决方案一个很大的优势点。传统的微服务 SDK 在落地的过程中,很难将调用方的服务名注入进去,即便是通过规范约束调用方 Client 也必须注入客户端服务名。这个注入也非常容易出问题,比如写入错误的服务名或者其他服务的服务名,这种问题在 Trace 的落地实践中很常见。
Istio 这样的 Service Mesh 解决方案则没有这样的困扰,可以直接通过控制面下发当前服务的服务名,让 Sidecar 在 Metrics 中自动注入,不允许业务代码编写人员修改这个服务名,从而在根本上杜绝了调用方服务名出错的问题。
-
Service Workload:这里我们选中 reviews.default.svc.cluster.local,然后查看 Service Workload 的下拉框,可以看到三个选项 review-v1、reviews-v2、reviews-v3。这里其实就是 reviews 这个服务的三个不同版本,可以分别选择这三个版本中的任意一个或者多个查看相应的监控信息。
-
SERVICE: reviews.default.svc.cluster.local 的一些常见信息,比如客户端/服务端请求的 QPS、成功率、延时等。这里所有的指标都有两个维度,一个是服务端自身的,一个是Client 端的,相对来说 Client 端的统计更接近服务本身的耗时,因为服务自身的统计无法把网络消耗统计在内。很多时候我们经常过度关注服务自身的各种指标,反而忽略了网络层面的一些消耗。
-
Client Workloads,可以看到不同版本的调用端服务、请求的黄金指标,包括 QPS、延时、响应大小等。
-
Service Workloads,也就是当前服务的不同版本的统计信息,同样包含了 QPS、延时、响应大小,以及 TCP 连接等信息。
接下来,我们可以通过 Workload 的维度,查看服务的信息,这个维度的统计信息粒度更加细致,可以从不同的版本角度查看。通过下面的链接可以直接访问 http://localhost:3000/dashboard/db/istio-workload-dashboard,也可以点击 istio-mesh-dashboard 上的链接访问。
相对于 istio-services-dashboard,这个页面最大的优势,是可以看到 inbound(入流量)和 outbound(出流量)两个流量方向的监控信息,比如我们这里选中 reviews-v3 这个 Workload,可以看到它的 inbound 的信息,也就是 productpage-v1 这个调用端访问过来的流量;也可以看到 review-v3 访问出去的流量,流量路由到的服务是 ratings.default.svc.cluster.local。
以客户端的视角,查看服务的出流量在很多场景下也是非常重要的,很多时候我们不仅要关注其他服务调用我们服务的健康情况,也要关注我们访问其他服务的健康状况,在一些情况下二者是息息相关的。
Workload dashboard 的参数解释:
和上面讲解 Services 的 dashboard 一样,这里也简单介绍一下 Workload dashboard 的参数。
-
Namespace:这里和上面 Services dashboard 提到的 namespace 是同一个概念。
-
Workload:指的是服务的不同版本。比如 reviews 这个服务就可以选择 v1、v2、v3 三个版本。
-
Inbound Workload:指的是不同版本的调用方服务,比如 review-v3 这个服务,就可以看到 productpage-v1 这个调用方。
-
Destination Service:指的是当前版本的服务调用了哪些服务,比如 review-v3 这个服务,就可以看到 ratings.default.svc.cluster.local 这个被调方服务。
接下来我们来看几个面板展示的信息。
-
WORKLOAD: reviews-v3.default:这里包含了 review-v3 这个 workload 的一些基础信息,包含QPS、错误统计、延时等信息。
-
INBOUND WORKLOAD:展示了不同的调用方的 workload 维度的基础信息。
-
OUTBOUND SERVICES:展示了当前服务访问其他服务的监控信息。
至此,Metrics 相关的实战就讲完了,我们学习了 Isito 中的 Prometheus 和 Grafana 的相关知识。下面我们来看看 Istio 的 Log 模块。
Log 日志
1,日志的观测相对简单,我们还是访问几次 productpage 页面,通过命令查看:
$ kubectl logs productpage-v1-65576bb7bf-hj6mw -c Istio-proxy2,在终端会看到如下输出:
[2021-02-14T02:36:34.480Z] "GET /details/0 HTTP/1.1" 200 - "-" "-" 0 178 7 7 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36" "8b9abfac-215b-93d6-98b6-6c56b8eb14da" "details:9080" "172.18.0.15:9080" outbound|9080||details.default.svc.cluster.local 172.18.0.20:45544 10.110.238.95:9080 172.18.0.20:48928 - default[2021-02-14T02:36:34.493Z] "GET /reviews/0 HTTP/1.1" 200 - "-" "-" 0 379 318 316 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36" "8b9abfac-215b-93d6-98b6-6c56b8eb14da" "reviews:9080" "172.18.0.14:9080" outbound|9080|v2|reviews.default.svc.cluster.local 172.18.0.20:57886 10.107.87.91:9080 172.18.0.20:43118 - -[2021-02-14T02:36:34.473Z] "GET /productpage HTTP/1.1" 200 - "-" "-" 0 5292 344 343 "172.17.0.2" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36" "8b9abfac-215b-93d6-98b6-6c56b8eb14da" "127.0.0.1" "127.0.0.1:9080" inbound|9080|http|productpage.default.svc.cluster.local 127.0.0.1:52130 172.18.0.20:9080 172.17.0.2:0 outbound_.9080_._.productpage.default.svc.cluster.local default
你可以看到这里面包含了 Envoy 收集的访问日志,包括访问 IP、服务名、user-agent 等基本信息。当然如果要分析这些日志,仅仅通过命令查看是远远不够的,此时我们需要借助 ELK 这样的工具进行收集和分析。
下面我们继续学习 Trace 链路追踪在 Istio 中是如何实现的。
Trace 链路追踪
关于 Trace 链路追踪的原理在 10 讲“可观测性Trace...”中已经讲过了,即便利用了 Istio 这样的服务网格架构,也无法做到无侵入的接入Trace。
让我们先从代码层面看看 Istio 是如何接入 Trace 系统的。虽然网格代理 Envoy 能够自动识别 Trace 中的 header,在请求 upstream 的时候自动生成 span 并携带发送,但是如果要将整个链路追踪信息串在一起,还需要代码中额外携带一些链路追踪信息才能完成。
Istio 规定需要携带以下 header:
x-request-idx-b3-traceidx-b3-spanidx-b3-parentspanidx-b3-sampledx-b3-flagsx-ot-span-context
下面我们结合 Bookinfo 中的 productpage 这个项目代码,看是如何实现的。源码的地址为https://github.com/istio/istio/blob/master/samples/bookinfo/src/productpage/productpage.py。
1,首先我们看一下入口方法:
@app.route('/productpage')@trace()def front():product_id = 0 # TODO: replace default valueheaders = getForwardHeaders(request)user = session.get('user', '')product = getProduct(product_id)detailsStatus, details = getProductDetails(product_id, headers)
可以看到,通过 getForwardHeaders 方法,我们获取了在请求其他服务时需要传递的 header 参数,在 getProductDetails 调用的时候,传递了我们通过 getForwardHeaders 方法获得的 header 参数。
下面我们看一下上述内容如何在代码中得以体现:
def getForwardHeaders(request):headers = {}# x-b3-*** 通过 opentracing 的库直接获取span = get_current_span() # 获取 downstream header 中传递的 spancarrier = {}tracer.inject(span_context=span.context,format=Format.HTTP_HEADERS,carrier=carrier) # 将 trace header 注入 carrierheaders.update(carrier) # 更新 headers# 手动获取其他非 x-b3-*** 的 headerif 'user' in session:headers['end-user'] = session['user']# Keep this in sync with the headers in details and reviews.incoming_headers = [# All applications should propagate x-request-id. This header is# included in access log statements and is used for consistent trace# sampling and log sampling decisions in Istio.'x-request-id',# Lightstep tracing header. Propagate this if you use lightstep tracing# in Istio (see# https://istio.io/latest/docs/tasks/observability/distributed-tracing/lightstep/)# Note: this should probably be changed to use B3 or W3C TRACE_CONTEXT.# Lightstep recommends using B3 or TRACE_CONTEXT and most application# libraries from lightstep do not support x-ot-span-context.'x-ot-span-context',# Datadog tracing header. Propagate these headers if you use Datadog# tracing.'x-datadog-trace-id','x-datadog-parent-id','x-datadog-sampling-priority',# W3C Trace Context. Compatible with OpenCensusAgent and Stackdriver Istio# configurations.'traceparent','tracestate',# Cloud trace context. Compatible with OpenCensusAgent and Stackdriver Istio# configurations.'x-cloud-trace-context',# Grpc binary trace context. Compatible with OpenCensusAgent nad# Stackdriver Istio configurations.'grpc-trace-bin',# b3 trace headers. Compatible with Zipkin, OpenCensusAgent, and# Stackdriver Istio configurations. Commented out since they are# propagated by the OpenTracing tracer above.# 'x-b3-traceid',# 'x-b3-spanid',# 'x-b3-parentspanid',# 'x-b3-sampled',# 'x-b3-flags',# Application-specific headers to forward.'user-agent',]# For Zipkin, always propagate b3 headers.# For Lightstep, always propagate the x-ot-span-context header.# For Datadog, propagate the corresponding datadog headers.# For OpenCensusAgent and Stackdriver configurations, you can choose any# set of compatible headers to propagate within your application. For# example, you can propagate b3 headers or W3C trace context headers with# the same result. This can also allow you to translate between context# propagation mechanisms between different applications.# 传递其他非 b3 header 的头信息for ihdr in incoming_headers:val = request.headers.get(ihdr)if val is not None:headers[ihdr] = valreturn headers
可以看到,通过 Jaeger 的类库,自动将带有 b3 header 的数据存储到了 headers 中,其他的一些 Trace 规范,则需要通过 incoming_headers 自定义的方式自动传递。
至此,代码方面的原理告一段落,下面我们来启动 Jaeger 看看具体的效果。
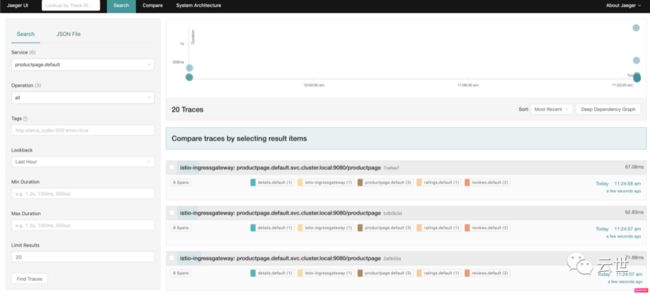
1,启动 Jaeger,通过 URL 或者 cURL 的方式多次访问 productpage:
istioctl dashboard jaeger2,选择 productpage 服务,可以看到如下页面:
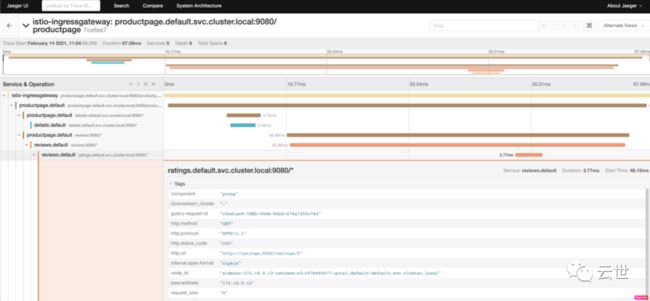
3,点击一条具体的链路,进入详情页面,可以详细展示整个微服务调用的链路,包含每个阶段耗时的详细信息,方便我们排查具体哪个环节出现了问题:
4,点击 System Architecture 页面,可以看到整个微服务的调用关系展示:

至此,整个 Trace 链路追踪的实战部分就讲解完了,下面我们做一个简单的总结。
总结
这一讲主要介绍了 Istio 中的可观测性实战,包括 Metrics、Trace、Log 三个部分。本讲内容总结如下:

今天我们学习了 Istio 的可观测性,对 Grafana 的展示页面做了详细的分析,相信你已经了解了服务要从 inbound 和 outbound 两个角度查看监控,另外我们也从代码的角度分析了 Istio 如何接入 Trace。
对于 Istio 的 Metrics Grafana 展示页面,现在只是展示了基本的黄金指标,除此之外,你觉得还有哪些监控指标需要完善,以增强服务网格的可观测性呢?
欢迎关注【云世】公众号,在评论区分享你的观点。

云世
【云世】专注微服务和云原生前沿技术和落地实践的布道。分享Spring Cloud微服务架构,及容器、Kubernetes、DevOps、Service Mesh等云原生技术干货、案例、学习实录、经验。持续发布读书笔记,好书推荐等。
公众号
今天的内容到这里就结束了,接下来我们将开始一个全新的篇章:如何自己动手用 Go 语言实现一套 Service Mesh 架构。下一讲我们一起探讨项目背景:判断选择开源产品还是自研。

云世推荐搜索 metrics指标log日志trace链路追踪prometheusGrafana