RDD----RDD创建+RDD分区+RDD转换算子+RDD行动算子+实现wordc的11种方法
目录
一、创建RDD
1、从内存中创建
2、从文件中创建RDD
二、RDD分区与分区数据匹配
1、内存分区的设定
2、内存分区数据的匹配
3、文件分区的设定
4、文件分区数据的匹配
三、RDD转换算子
1、value类型
(1)map,可以进行映射转换,可以是类型,可以是值
(2) mapPartitions 进去迭代器,返回迭代器
(3)mapPartitionsWithIndex 可以获取指定分区的数据
(4)flatMap 扁平化
(5)groupby 分组
(6)filter 过滤
(7)sample 随机抽数,放回与不放回
(8) distinct 去重
(9)coalesce 缩小分区
(10)repartition 扩大分区
(11)sortBy 默认升序排序
2、双value类型
(1)交集、并集、差集、拉链
3、key value类型
(1)partitionBy 将数据重新分配
(2)reduceByKey 相同key进行 value聚合
(3) groupByKey 相同的key的数据分到一个组中,形成一个对偶元组
(4)reduceByKey 和 groupByKey
(5)aggregateByKey 分区内,分区间计算逻辑不一致
(6)foldByKey 分区内与分区间计算逻辑一致,简化写
(7)72 一个小练习,获取相同key的平均值
(8)combineByKey
(9)74 reduceByKey、foldByKey、aggregateByKey、combineByKey的区别?
(10) join 和 leftOuterJoin
(11) cogroup 实现分组连接
四、RDD行动算子
1、什么叫行动算子?
2、行动算子
(1)reduce、collect、count、first、take、takeOrdered
(2) aggregate 计算逻辑和 aggregateByKey
(3)fold 当aggregate 分区内与分区间计算逻辑一致时,使用它进行简化
(4)countByValue 统计每个出现的次数
(5)countByKey 统计每个key出现的次数
(6)save相关算子
五、实现wordcou的11种方法
一、创建RDD
1、从内存中创建
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]): Unit = {
//准备环境
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
//创建RDD
//从内存中创建RDD,将内存中集合的数据作为处理的数据源
val seq = Seq[Int](1, 2, 3, 4)
//collect 汇总
// sc.parallelize(seq).collect().foreach(println)
// makeRDD方法在底层实现就是调用,rdd的对象parallelize 方法 !!!
sc.makeRDD(seq).collect().foreach(println)
//关闭环境
sc.stop()
}
}
2、从文件中创建RDD
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
// 从文件中创建RDD,作为处理的数据源
// path路径以当前的环境,根路径为基准,可以写绝对路径,也可以写相对路径
// 路径可以是具体文件,也可是目录,是目录就会统计目录下所有文件内容
// 路径也可是使用通配符 如:Data/Wc*
//路径也可是 hdfs路径 如: hdfs://hadoop:9000/test.txt
val rdd = sc.textFile("Data/Wcdata.txt")
rdd.collect().foreach(println)
sc.stop()
}
}
二、RDD分区与分区数据匹配
1、内存分区的设定
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
//配置分区
conf.set("spark.default.parallelism","4")
val sc = new SparkContext(conf)
//makeRDD 可以传递第二个参数,表示分区的数量
//若不写第二个参数,使用默认值:defaultParallelism
// scheduler.conf.getInt("spark.default.parallelism", totalCores)
//spark在默认情况下,从配置对象中获取参数 spark.default.parallelism
// 如果获取不到,就使用 totalCores 属性,这个属性取值为当前的环境最大可用核数
val rdd = sc.makeRDD(List(1, 2, 3, 4),2)
//saveAsTextFile将处理的数据保存成分区文件
rdd.saveAsTextFile("output")
sc.stop()
}
}
2、内存分区数据的匹配
3、文件分区的设定
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
//配置分区
conf.set("spark.default.parallelism","4")
val sc = new SparkContext(conf)
// textFile 也可以默认指定分区
//minPartitions 最小分区数量
//math.min(defaultParallelism, 2)
//若不想使用默认的分区数量,可以使用第二个分区,指定分区数
//spark 读取文件,底层使用的就是hadoop的读取方式
//分区计算方式:
/*比如指定两个分区,文件有7个字节(回车等也算)
* 文件 totalSize = 7
* 指定分区数 par =2
* goalSize = 7/2 = 3
* 那么每个分区需要存放2 还余 1 ,1占3的百分之30,
* 超过hadoop分区百分之10,就会再增加一个分区,所以最后是 3个分区
* */
val rdd = sc.textFile("Data/Wcdata.txt",3)
//saveAsTextFile将处理的数据保存成分区文件
rdd.saveAsTextFile("output")
sc.stop()
}
}
4、文件分区数据的匹配
三、RDD转换算子
1、value类型
(1)map,可以进行映射转换,可以是类型,可以是值
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
//1 2 3 4 -> 2 4 6 8
//1 写法逻辑
// def mapfunction(num:Int): Int = {
// num *2
// }
// rdd.map(mapfunction).collect().foreach(println)
//2 简易写法
// rdd.map((num: Int) => {num *2}).collect().foreach(println)
//3 将2再次简化
// 当代码逻辑只有一行,花括号可以省略
// rdd.map((num: Int) => num *2).collect().foreach(println)
// 参数类型可以自动推断出来,类型可以省略
// rdd.map((num) => num *2).collect().foreach(println)
// 如果参数列表只有一个,小括号可以省略
// rdd.map(num => num *2).collect().foreach(println)
// 参数在逻辑中只出现一次,并且按照顺序出现,可以使用下划线代替
rdd.map(_*2).collect().foreach(println)
sc.stop()
}
}
(2) mapPartitions 进去迭代器,返回迭代器
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4),2)
//1 2 3 4 -> 2 4 6 8
// mapPartitions 空间换时间,会将整个分区的数据,加载到内存中,
// 然后以分区为单位进行数据加载转换操作,处理完的数据不会被释放,所以注意内存,防止溢出
rdd.mapPartitions(num =>{num.map(_*2)}).collect().foreach(println)
//要求返回迭代器,求每个分区最大
rdd.mapPartitions(num => {
List(num.max).iterator
}).collect.foreach(println)
sc.stop()
}
}
(3)mapPartitionsWithIndex 可以获取指定分区的数据
获取第二个分区的数据
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4),2)
//1 2 3 4 -> 2 4 6 8
//需求只想获取第二个分区数据
rdd.mapPartitionsWithIndex((index,iter) => {
if (index == 1) {
iter
}
else {
//不符合返回一个空
Nil.iterator
}
})
sc.stop()
}
}
查看数据在哪个分区
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
//1 2 3 4 -> 2 4 6 8
//需求 查看数据在哪个分区
rdd.mapPartitionsWithIndex((index,inter) =>{
inter.map(num => {
(index,num)
})
}).collect().foreach(println)
sc.stop()
}
}
(4)flatMap 扁平化
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(List(1, 2), List(3, 4)))
// List(1, 2)
// List(3, 4)
// 将数据拆分成个体
rdd.flatMap(list =>{
list
}).collect().foreach(println)
// 拆分 字符串
val rdd1 = sc.makeRDD(List("hello spark", "spark hadoop"))
rdd1.flatMap(list =>{
list
}).collect().foreach(println)
// 这样打平是每个字母包括空格都打平,要进行分隔
rdd1.flatMap(list =>{
list.split(" ")
}).collect().foreach(println)
sc.stop()
}
}
模式匹配
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(List(1,2),1,2))
// 模式匹配
rdd.flatMap( data =>{
data match{
case list:List[_] => list
case dat => List(dat)
}
}).collect().foreach(println)
sc.stop()
}
}
(5)groupby 分组
分组原理
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,3,4),2)
//1分组原理
//groupBy会将数据源中每一个数据进行分区判断,根据返回的分组key进行分组
// 相同的 key值会被放在同一个组中
def groupa(num: Int): Int ={
// 取模为key
num %2
}
rdd.groupBy(groupa).collect().foreach(println)
//2
sc.stop()
}
}
根据单词的首字母进行分组
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List("hello","spark","hello","hive"),2)
rdd.groupBy(_.charAt(0)).collect().foreach(println)
sc.stop()
}
}
groupby 分组和分区没有必然联系
groupby 是一个将数据打乱重新组成的过程,所以有shuffle
(6)filter 过滤
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
// 只保留奇数
// rdd.filter(num =>{num%2!=0})
rdd.filter(_%2!=0).collect().foreach(println)
sc.stop()
}
}
当对数据进行筛选过滤后,符合规则的数据留下,不符和的舍去,分区数不变,但这很可能造成分区内数据分布的不均匀,导致数据倾斜
(7)sample 随机抽数,放回与不放回
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd =sc.makeRDD(List(1,2,3,4),1)
// 抽取数据不放回(伯努利算法)
// 具体实现:根据种子和随机算法算出一个数和第二个参数设置几率比较,小于第二个参数要,大于不要
// 第一个参数:抽取的数据是否放回,false:不放回
// 第二个参数:抽取的几率,范围在[0,1]之间,0:全不取;1:全取;
// 第三个参数:随机数种子
val dataRDD1 = rdd.sample(false, 0.5)
// 抽取数据放回(泊松算法)
// 第一个参数:抽取的数据是否放回,true:放回;false:不放回
// 第二个参数:重复数据的几率,范围大于等于0.表示每一个元素被期望抽取到的次数
// 第三个参数:随机数种子
val dataRDD2 = rdd.sample(true, 2)
sc.stop()
}
}
有啥用?
在实际开发过程中,往往会出现数据倾斜的情况。那么可以从数据倾斜的分区中抽取数据,查看数据的规则。分析后,可以进行改善处理,让数据更加均匀。
(8) distinct 去重
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,3,4,1,2),1)
// 原理 map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
val rdd1 = rdd.distinct()
val rdd2 = rdd.distinct(2)
//发现重新分为两个区
rdd2.saveAsTextFile("output")
sc.stop()
}
}
(9)coalesce 缩小分区
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,3,4,1,2),6)
//coalesce算子默认情况下无法扩大分区,因为默认情况下不会打乱数据。
// 扩大分区是没有意义的,如果就想扩大分区,那么必须使用shuffle,打乱数据。即第二个参数
val rdd1 = rdd.coalesce(2)
rdd1.saveAsTextFile("output")
sc.stop()
}
}
(10)repartition 扩大分区
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,3,4,1,2),2)
//repartition底层就是coalesce(numPartitions, shuffle = true)
val rdd1 = rdd.repartition(4)
rdd1.saveAsTextFile("output")
sc.stop()
}
}
repartition算子其实底层调用的就是coalesce算子,只不过固定使用了shuffle的操作,可以让数据更均衡一下,可以有效防止数据倾斜问题。
如果缩减分区,一般就采用coalesce,如果想扩大分区,就采用repartition
(11)sortBy 默认升序排序
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,6,4,1,2),2)
//默认升序,不改变分区,有shuffle
rdd.sortBy(num => num).collect().foreach(println)
//第二个参数 false 降序
rdd.sortBy(num => num,false).collect().foreach(println)
sc.stop()
}
}
2、双value类型
(1)交集、并集、差集、拉链
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test4 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(1, 2, 3, 4))
val rdd2 = sc.makeRDD(List(3,4,5,6))
//交集
println(rdd1.intersection(rdd2).collect().mkString(","))
//并集
println(rdd1.union(rdd2).collect().mkString(","))
//差集 站在rdd1的角度上去看和rdd2的差集 【1,2】
println(rdd1.subtract(rdd2).collect().mkString(","))
//拉链 预想结果 13 24 35 46
println(rdd1.zip(rdd2).collect().mkString(","))
sc.stop()
}
}
如果两个RDD数据类型不一致怎么办?会出错
交集并集和差集要求两个数据源数据类型保持一致
拉链操作,两个数据源类型可以不一致
但是拉链操作要求我们的两个数据源的分区数量要保持一致,并且还要保持两个数据源分区中的数据要保持一致
3、key value类型
(1)partitionBy 将数据重新分配
package com.test
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
object Test5 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
//partitionBy 将数据进行重分配 使用规则HashPartitioner
val newrdd = rdd.map(num => {
(num, 1)
}).partitionBy(new HashPartitioner(2))
newrdd.saveAsTextFile("output")
sc.stop()
}
}
(2)reduceByKey 相同key进行 value聚合
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object reduceBykey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 1), ("c", 3)))
//reduceByKey
//相同的key进行value数据的聚合(两两聚合)
//如果key的数据只有一个,是不会参与运算的!!!直接返回
rdd.reduceByKey((x,y) =>(x+y)).collect().foreach(println)
sc.stop()
}
}
(3) groupByKey 相同的key的数据分到一个组中,形成一个对偶元组
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object groupBykey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 1), ("c", 3)))
//groupByKey
//将数据源中的数据,相同的key的数据分到一个组中,形成一个对偶元组
//元组中第一个元素 是 key
//元组中第二个元素 是 相同key的value 的集合
rdd.groupByKey().collect().foreach(println)
println("-----------------------------------")
rdd.groupBy(_._1).collect().foreach(println)
sc.stop()
}
}
结果:
(a,CompactBuffer(1, 2))
(b,CompactBuffer(1))
(c,CompactBuffer(3))
-----------------------------------
(a,CompactBuffer((a,1), (a,2)))
(b,CompactBuffer((b,1)))
(c,CompactBuffer((c,3)))(4)reduceByKey 和 groupByKey
groupByKey大致原理

reduceByKey 大致原理(支持分区内预聚合,可以有效减少shuffle时的数据量,提升shuffle的性能 )
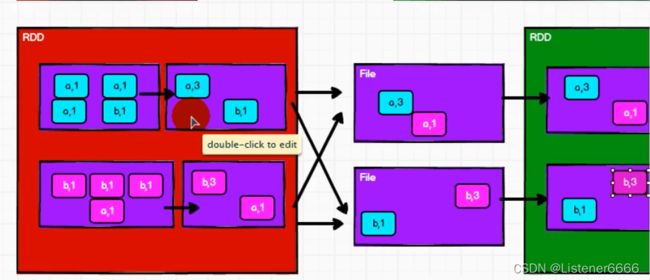
总结:
两个算子没有使用上的区别。所以使用的时候需要根据应用场景来选择。
从性能上考虑,reduceByKey存在预聚合功能,这样,在shuffle的过程中,落盘的数据量会变少,所以读写磁盘的速度会变快。性能更高
(5)aggregateByKey 分区内,分区间计算逻辑不一致
reduceByKey 支持分区内预聚合 可以有效减少shuffle落盘数据量
但是 这要求我们 使用reduceByKey 时分区内与分区间的计算规则要一样,例如统计wc
相同的key 两两之间聚合
但是当遇到计算逻辑不一致时,比如分区内求最大值,分区间求和,此时reduceByKey 就不太能满足要求。
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4)),2)
//第一个参数列表
//需要传递一个参数,表示为初始值
// 主要用于当碰见第一个key的时候,和value进行分区内的计算
//第二个参数列表
//需要两个参数,第一个参数 表示分区内计算规则
// 第二个参数 表示分区间计算规则
rdd.aggregateByKey(0)(
(x,y) => math.max(x,y),
(x,y) => x +y
).foreach(println)
sc.stop()
}
}
(6)foldByKey 分区内与分区间计算逻辑一致,简化写
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3), ("a", 4)),2)
// rdd.aggregateByKey(0)(_+_,_+_).collect().foreach(println)
//如果聚合计算时,分区内和分区间计算逻辑一致,spark提供了简化方法
rdd.foldByKey(0)(_+_).collect().foreach(println)
sc.stop()
}
}
(7)72 一个小练习,获取相同key的平均值
(8)combineByKey
一个分区下:
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test10 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4), ("b", 5), ("c", 6)
),1)
rdd.mapPartitionsWithIndex((index,partition) => {
println("----------------"+index)
partition.map(x => s"${index},${x}")
}).foreach(println)
val res = rdd.combineByKey(
(v:Int) => v + "_" , //初始化
(c:String,v:Int) => c + "@" + v , //同一分区内计算
(c1:String,c2:String) => c1 + "$" + c2 , //跨分区合并
)
println(res.collect().mkString(","))
sc.stop()
}
}
打印结果为:
----------------0
0,(a,1)
0,(a,2)
0,(a,3)
0,(b,4)
0,(b,5)
0,(c,6)
(a,1_@2@3),(b,4_@5),(c,6_)三个分区下:
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test10 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("a", 3), ("b", 4), ("b", 5), ("c", 6)
),3)
rdd.mapPartitionsWithIndex((index,partition) => {
println("----------------"+index)
partition.map(x => s"${index},${x}")
}).foreach(println)
val res = rdd.combineByKey(
(v:Int) => v + "_" , //初始化
(c:String,v:Int) => c + "@" + v , //同一分区内计算
(c1:String,c2:String) => c1 + "$" + c2 , //跨分区合并
)
println(res.collect().mkString(","))
sc.stop()
}
}
打印结果为:
----------------1
----------------0
----------------2
2,(b,5)
1,(a,3)
0,(a,1)
1,(b,4)
2,(c,6)
0,(a,2)
(c,6_),(a,1_@2$3_),(b,4_$5_)(9)74 reduceByKey、foldByKey、aggregateByKey、combineByKey的区别?
从源码的角度来讲,四个算子的底层逻辑是相同的。
aggregateByKey的算子会将初始值和第一个value使用分区内的计算规则进行计算
foldByKey的算子的分区内和分区间的计算规则相同,并且初始值和第一个value使用的规则相同
combineByKey第一个参数就是对第一个value进行处理,所以无需初始值。
reduceByKey不会对第一个value进行处理,分区内和分区间计算规则相同
上面的四个算子都支持预聚合功能。所以shuffle性能比较高
上面的四个算子都可以实现WordCount
(10) join 和 leftOuterJoin
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3),("d",0),("a",22)))
val rdd2 = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6)))
// join
// 两个不同数据源的数据,相同key的的value会连接在一起,形成元组
// 类似inner join
rdd1.join(rdd2).collect().foreach(println)
println("-------------------------------------------------")
//leftOuterJoin
rdd1.leftOuterJoin(rdd2).collect().foreach(println)
sc.stop()
}
}
打印结果:
(a,(1,4))
(a,(22,4))
(b,(2,5))
(c,(3,6))
-------------------------------------------------
(a,(1,Some(4)))
(a,(22,Some(4)))
(b,(2,Some(5)))
(c,(3,Some(6)))
(d,(0,None))(11) cogroup 实现分组连接
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3),("d",0),("a",22)))
val rdd2 = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6)))
// cogroup : connect + group
//
rdd1.cogroup(rdd2).collect().foreach(println)
sc.stop()
}
}
打印结果:
(a,(CompactBuffer(1, 22),CompactBuffer(4)))
(b,(CompactBuffer(2),CompactBuffer(5)))
(c,(CompactBuffer(3),CompactBuffer(6)))
(d,(CompactBuffer(0),CompactBuffer()))四、RDD行动算子
1、什么叫行动算子?
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
//行动算子,其实就是触发作业(job)执行的方法
//底层代码调用的是环境对象的 runJob 方法
//底层代码会创建ActiveJob,并且提交执行
rdd.collect()
sc.stop()
}
}
2、行动算子
(1)reduce、collect、count、first、take、takeOrdered
package com.test
import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
//
println(rdd.reduce(_+_))
// collect :会将不同分区的数据按照分区顺序采集到Driver端内存中,形成数组
rdd.collect().foreach(println)
// count: 获取数据源中数据的个数
println(rdd.count())
//first :获取数据源中数据的第一个
print(rdd.first())
//take : 获取数据中的 N 个数据
rdd.take(3).foreach(println)
//takeOrdered:数据排序后,取N个数据
rdd.takeOrdered(3).foreach(println)
sc.stop()
}
}
(2) aggregate 计算逻辑和 aggregateByKey
区别,它的初始值会既参与分区内计算,也参与分区间计算
package com.peizk.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("My HdfsApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,3,4),2)
println(rdd.aggregate(10)(_ + _, _ + _))
sc.stop()
}
}
(3)fold 当aggregate 分区内与分区间计算逻辑一致时,使用它进行简化
package com.peizk.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("My HdfsApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,3,4),2)
println(rdd.fold(10)(_ + _))
sc.stop()
}
}
(4)countByValue 统计每个出现的次数
package com.peizk.test
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("My HdfsApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,1,2,3,4,4,4,4),2)
//countByValue,可以统计出每个值出现的次数
println(rdd.countByValue())
sc.stop()
}
}
打印结果:
Map(4 -> 4, 2 -> 2, 1 -> 2, 3 -> 1)(5)countByKey 统计每个key出现的次数
package com.peizk.test
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("My HdfsApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(
(1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c")
))
// 统计每种key的个数
println(rdd.countByKey())
sc.stop()
}
}
(6)save相关算子
package com.peizk.test
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("My HdfsApp")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(
(1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c")
))
rdd.saveAsTextFile("output1")
rdd.saveAsObjectFile("output2")
//saveAsSequenceFile 方法要求数据的格式必须为 K -V 类型
rdd.saveAsSequenceFile("output3")
sc.stop()
}
}
五、实现wordcou的11种方法
package com.test
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
wordcount1(sc)
sc.stop()
}
//1 group by
def wordcount1(sc: SparkContext): Unit ={
val rdd = sc.makeRDD(List("Hello spark", "Hello scala"))
val word = rdd.flatMap(_.split(" "))
val group = word.groupBy(word => word)
val worcount = group.mapValues(iter => iter.size)
}
// 2 groupByKey 要有k v类型 效率不高 走shuffle
def wordcount2(sc: SparkContext): Unit ={
val rdd = sc.makeRDD(List("Hello spark", "Hello scala"))
val word = rdd.flatMap(_.split(" "))
val wordone = word.map((_, 1))
val group = wordone.groupByKey()
val worcount = group.mapValues(iter => iter.size)
}
// 3 reduceByKey 较groupByKey 效率更好点
def wordcount3(sc: SparkContext): Unit ={
val rdd = sc.makeRDD(List("Hello spark", "Hello scala"))
val word = rdd.flatMap(_.split(" "))
val wordone = word.map((_, 1))
val worcount = wordone.reduceByKey(_+_)
}
// 4 aggregateByKey
def wordcount4(sc: SparkContext): Unit ={
val rdd = sc.makeRDD(List("Hello spark", "Hello scala"))
val word = rdd.flatMap(_.split(" "))
val wordone = word.map((_, 1))
val worcount = wordone.aggregateByKey(0)(_+_,_+_)
}
// 5 foldByKey 当aggregateByKey分区内分区外规则一样时
def wordcount5(sc: SparkContext): Unit ={
val rdd = sc.makeRDD(List("Hello spark", "Hello scala"))
val word = rdd.flatMap(_.split(" "))
val wordone = word.map((_, 1))
val worcount = wordone.foldByKey(0)(_+_)
}
// 6 combineByKey 需要传三个参数
def wordcount6(sc: SparkContext): Unit ={
val rdd = sc.makeRDD(List("Hello spark", "Hello scala"))
val word = rdd.flatMap(_.split(" "))
val wordone = word.map((_, 1))
val worcount = wordone.combineByKey(
v=>v,
(x:Int,y)=>x+y,
(x:Int,y:Int)=>x+y
)
}
// 7 countByKey
def wordcount7(sc: SparkContext): Unit = {
val rdd = sc.makeRDD(List("Hello spark", "Hello scala"))
val word = rdd.flatMap(_.split(" "))
val wordone = word.map((_, 1))
val worcount = wordone.countByKey()
}
// 8 countByValue
def wordcount8(sc: SparkContext): Unit ={
val rdd = sc.makeRDD(List("Hello spark", "Hello scala"))
val word = rdd.flatMap(_.split(" "))
val worcount = word.countByValue()
}
// 9 reduce,aggregate,fold
def wordcount9(sc: SparkContext): Unit ={
val rdd = sc.makeRDD(List("Hello spark", "Hello scala"))
val word = rdd.flatMap(_.split(" "))
val mapword = word.map(
word => {
mutable.Map[String, Long]((word, 1))
}
)
val wordcount = mapword.reduce(
(map1, map2) => {
map1
}
)
}
}