【Elastic (ELK) Stack 实战教程】04、ElasticSearch 集群进阶及优化
目录
一、ES 集群故障转移
1.1 什么是故障转移
1.2 模拟节点故障
1.2.1 重新选举
1.2.2 主分片调整
1.2.3 副本分片调整
二、ES 文档路由原理
2.1 文档的创建流程
2.2 文档的读取流程
2.3 文档批量创建的流程
2.4 文档批量读取的流程
三、ES扩展集群节点
3.1 节点扩展环境准备
3.2 节点扩展 node4 配置
3.3 节点扩展 node5 配置
3.4 节点扩展检查
3.5 扩展路由节点
四、ES 集群调优建议(每台机器都需要)
4.1 内核参数优化
4.2 配置参数优化
4.3 JVM 参数优化
一、ES 集群故障转移
1.1 什么是故障转移
所谓故障转移指的是,当集群中有节点发生故障时,这个集群是如何进行自动修复的。ES集群目前是由 3 个节点组成,如下图所示,此时集群状态是 green:

1.2 模拟节点故障
假设: node1 所在机器宕机导致服务终止,此时集群会如何处理?
大体分为三个步骤:
-
重新选举
-
主分片调整
-
副本分片调整
1.2.1 重新选举
node2 和 node3 发现 node1 无法响应;一段时间后会发起 master 选举,比如这里选择 node2 为 master 节点;此时集群状态变为 Red 状态:
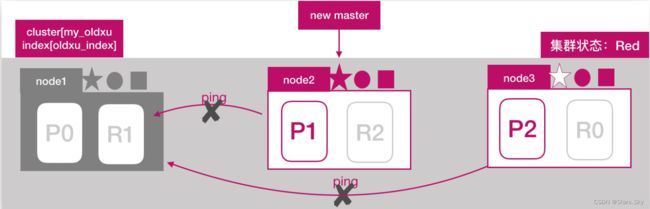
1.2.2 主分片调整
node2 发现主分片 P0 未分配,将 node3 上的 R0 提升为主分片;此时所有的主分片都正常分配,集群状态变为 Yellow状态:
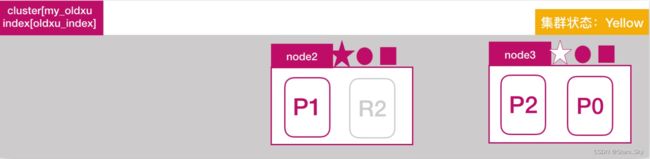
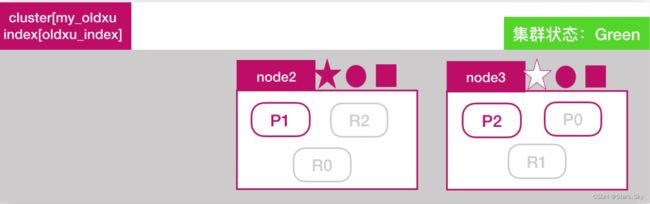
1.2.3 副本分片调整
node2 将 P0 和 P1 主分片重新生成新的副本分片 R0、R1,此时集群状态变为 Green:
二、ES 文档路由原理
ES 文档分布式存储,当一个文档存储至 ES 集群时,存储的原理是什么样的?如图所示,当我们想一个集群保存文档时,Document1 是如何存储到分片 P1 的?选择 P1 的依据是什么?
 其实是有一个文档到分片的映射算法,其目是使所有文档均匀分布在所有的分片上,那么是什么算法呢?随机还是轮询呢? 这种是不可取的,因为数据存储后,还需要读取,那这样的话如何读取呢?
其实是有一个文档到分片的映射算法,其目是使所有文档均匀分布在所有的分片上,那么是什么算法呢?随机还是轮询呢? 这种是不可取的,因为数据存储后,还需要读取,那这样的话如何读取呢?
实际上,在 ES 中,通过如下的公式计算文档对应的分片存储到哪个节点,计算公式如下:
shard = hash(routing) % number_of_primary_shards
# hash 算法保证将数据均匀分散在分片中
# routing 是一个关键参数,默认是文档id,也可以自定义。
# number_of_primary_shards 主分片数
# 注意:该算法与主分片数相关,一但确定后便不能更改主分片。因为一旦修改主分片修改后,Share 的计算就完全不一样了。2.1 文档的创建流程

2.2 文档的读取流程

2.3 文档批量创建的流程

2.4 文档批量读取的流程
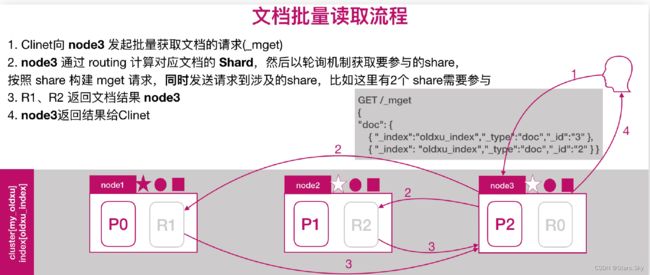 三、ES扩展集群节点
三、ES扩展集群节点
3.1 节点扩展环境准备
| 主机名称 | IP |
| es-node4 | 192.168.170.130 |
| es-node5 | 192.168.170.131 |
3.2 节点扩展 node4 配置
实际生产环境中最好是用 Oracle jdk 安装:Linux 部署 JDK+MySQL+Tomcat 详细过程_移植mysql+tomcat_Stars.Sky的博客-CSDN博客
这边省事就直接 yum 安装 java 了:
[root@es-node4 ~]# yum -y install java
[root@es-node4 ~]# rpm -ivh elasticsearch-7.8.1-x86_64.rpm
[root@es-node4 ~]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: my-es # 加入的集群名称
node.name: es-node4
node.data: true # data节点(默认,可以不写)
node.master: false # 不参与 master 选举
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.170.132", "192.168.170.133", "192.168.170.134"] # 选择要加入集群中的其中几个节点 ip 即可,不需要全部。
[root@es-node4 ~]# systemctl enable --now elasticsearch.service
3.3 节点扩展 node5 配置
[root@es-node5 ~]# yum -y install java
[root@es-node5 ~]# rpm -ivh elasticsearch-7.8.1-x86_64.rpm
[root@es-node5 ~]# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: my-es # 加入的集群名称
node.name: es-node5
node.data: true # data节点(默认,可以不写)
node.master: false # 不参与 master 选举
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.170.132", "192.168.170.133", "192.168.170.134"] # 选择要加入集群中的其中几个节点 ip 即可,不需要全部。
[root@es-node5 ~]# systemctl enable --now elasticsearch.service
3.4 节点扩展检查
通过 cerebor 检查集群扩展后的状态;如果出现集群无法加入、或者加入集群被拒绝,尝试删除该节点 /var/lib/elasticsearch/* 下的文件,然后重启 es 即可:

3.5 扩展路由节点
如果将 data 节点修改为 Coordinating 节点(如 node5);注意需要清理数据(生产环境中谨慎操作!),否则无法启动:
[root@es-node5 ~]# vim /etc/elasticsearch/elasticsearch.yml
node.data: false
[root@es-node5 ~]# systemctl stop elasticsearch.service
[root@es-node5 ~]# /usr/share/elasticsearch/bin/elasticsearch-node repurpose
[root@es-node5 ~]# systemctl restart elasticsearch.service
node5 节点就不能存储数据了:
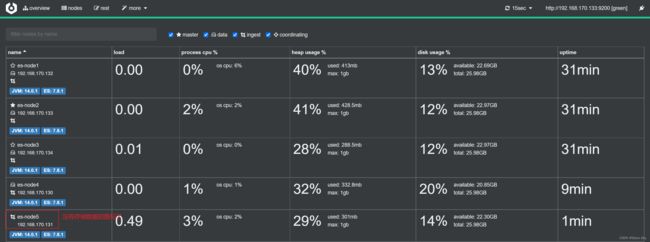
四、ES 集群调优建议(每台机器都需要)
4.1 内核参数优化
# 对于操作系统,需要调整几个内核参数
[root@es-node1 ~]# vim /etc/sysctl.conf
# 设定系统最大打开文件描述符数,建议修改为 655360 或者更高
fs.file-max=655360
# 用于限制一个进程可以拥有的虚拟内存大小,建议修改成 262144 或更高
vm.max_map_count = 262144
net.core.somaxconn = 32768
net.ipv4.tcp_tw_reuse = 1
net.ipv4.ip_local_port_range = 1000 65535
net.ipv4.tcp_max_tw_buckets = 400000
# 让配置生效
[root@es-node1 ~]# sysctl -p
# 调整最大用户进程数(nproc),调整进程最大打开文件描述符(nofile)
# 删除默认 nproc 设定文件
[root@es-node1 ~]# rm -rf /etc/security/limits.d/20-nproc.conf
[root@es-node1 ~]# vim /etc/security/limits.conf
* soft nproc 20480
* hard nproc 20480
* soft nofile 65536
* hard nofile 655364.2 配置参数优化
#1. 锁定物理内存地址,避免 es 使用 swap 交换分区,频繁的交换,会导致 IOPS 变高。
[root@es-node1 ~]# vim /etc/elasticsearch/elasticsearch.yml
bootstrap.memory_lock: true
#2. 配置 elasticsearch 启动参数
[root@es-node1 ~]# sed -i '/\[Service\]/aLimitMEMLOCK=infinity' /usr/lib/systemd/system/elasticsearch.service
[root@es-node1 ~]# systemctl daemon-reload
[root@es-node1 ~]# systemctl restart elasticsearch.service4.3 JVM 参数优化
JVM 内存具体要根据 node 要存储的数据量来估算,为了保证性能,在内存和数据量间有一个建议的比例:像一般日志类文件, 1G 内存能存储 48G~96GB 数据;jvm 堆内存最大不要超过31GB;其次就是主分片的数量,单个控制在 30-50GB。
假设总数据量为 1TB,3 个 node 节点,1 个副本;那么实际要存储的大小为 2TB,因为有一个副本的存在;2TB / 3 = 700GB,然后每个节点需要预留 20% 的空间,意味着每个 node 要存储大约 850GB 的数据;按照内存与存储数据的比率计算:
850GB/48=17GB,小于 31 GB,因为 31*48=1.4TB 及每个 Node 可以存储 1.4TB 数据,所以 3 个节点足够;850GB/30=30 个主分片,因为要尽量控制主分片的大小为 30GB;
假设总数据量为 2TB,3 个 node 节点,1 个副本;那么实际要存储的大小为 4TB,因为有一个副本的存在;4TB/3 = 1.4TB,然后每个节点需要预留 20% 的空间出来,意味着每个 node 要存储大约 1.7TB 的数据;按照内存与存储数据的比率计算:
1.7TB/48=32GB 大于 31G,因为 31*48=1.4TB 及每个 Node 最多存储 1.4TB 数据,所以至少需要 4 个节点;1.5TB/30G=50 个主分片,因为要尽量控制主分配存储的大小为 30GB。
[root@es-node1 ~]# vim /etc/elasticsearch/jvm.options
-Xms31g # 最小堆内存
-Xmx31g # 最大堆内存
#可根据服务器内存大小,修改为合适的值。一般设置为服务器物理内存的一半最佳,但最大不能超过32G
# 每天 1TB 左右的数据量的服务器配置
16C 64G 6T 3 台 ECS上一篇文章:【Elastic (ELK) Stack 实战教程】03、ElasticSearch 集群搭建_Stars.Sky的博客-CSDN博客
下一篇文章:【Elastic (ELK) Stack 实战教程】05、Filebeat 日志收集实践(上)_Stars.Sky的博客-CSDN博客