pandas记录——01.csv文件的读写
系列文章目录
01.csv文件的读写
文章目录
- 系列文章目录
- 前言
- 一、csv文件读取与写入
-
- 1. read_csv()
-
- 1.1 filepath_or_buffer
- 1.2 header
- 1.3 name
- 1.4 sep
- 1.5 delimiter与delim_whitespace
- 1.6 index_col
- 1.7 usecols
- 1.8 nrows
- 1.9 dtype
- 1.10 na_values
- 2. to_csv()
-
- 2.1 path_or_buf
- 2.2 sep
- 2.3 na_rep
- 2.4 float_format
- 2.5 columns
- 2.6 header
- 2.7 index
- 参考:
前言
本系列用于记录在pandas使用过程中的遇到的各个功能。
本章节记录对于csv文件的读写。
一、csv文件读取与写入
使用pandas做数据处理的第一步就是读取数据,数据源可以来自于各种地方,csv文件便是其中之一,csv文件其实是一种纯文本文件,由于常用Excel打开,因此本文将csv归属于Excel文件进行描述。
1. read_csv()
read_csv()函数用于读取csv文件,输出内容为DataFrame格式。
本章主要介绍read_csv()以下参数内容。
1.1 filepath_or_buffer
即文件的路径、URL、以及可以是实现read方法的任意对象。
import pandas as pd
pd.read_csv("girl.csv")
结果:
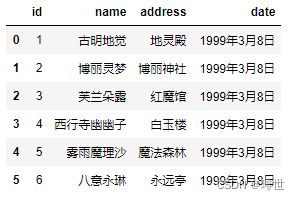
1.2 header
从现有表格中选择一行设置为DataFrame的列名称,默认为 “infer”,即自动推导。若设置为整数n,则表示将表格中的n行设置为列名称;设置为None,则表示不考虑列名称;若设置为list,则将此n行组合为列名称。
但是需要注意与1.3的name的关联关系。
pd.read_csv('girl.csv', header=1) # 不指定names,指定header为1,则选取第二行当做表头,第二行下
结果:

1.3 name
设置DataFrame的列名称,需要为list格式,list中元素个数需要与列对齐,否则会将最后“list中元素个数”行设置为名称,前面的行统一被设置为index。
name设置时会影响header的使用。
- 当names没被赋值时,header会变成0,即选取数据文件的第一行作为列名。
- 当 names 被赋值,header 没被赋值时,那么header会变成None。如果都赋值,就会实现两个参数的组合功能。
举例:
- names 没有被赋值,header 也没赋值:
pd.read_csv('girl.csv') # 我们说这种情况下,header为变成0,即选取文件的第一行作为表头
结果:
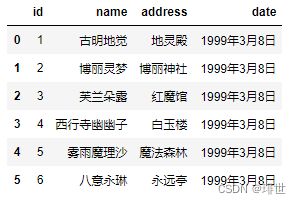
- names 没有被赋值,header 被赋值:
pd.read_csv('girl.csv', header=1) # 不指定names,指定header为1,则选取第二行当做表头,第二行下面的是数据
结果:

- names 被赋值,header 没有被赋值:
pd.read_csv('girl.csv', names=["编号", "姓名", "地址", "日期"])
结果:
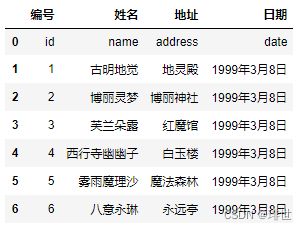
- names和header都被赋值:
pd.read_csv('girl.csv', names=["编号", "姓名", "地址", "日期"], header=0)
结果:
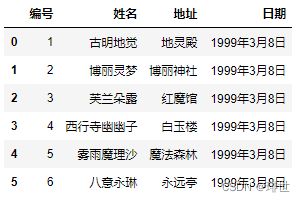
再举个例子:
pd.read_csv('girl.csv', names=["编号", "姓名", "地址", "日期"], header=3) # header=3,表示第四行当做表头,第四行下面当成数据 # 然后再把表头用names给替换掉,得到如下结果
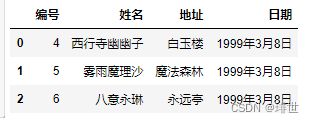
所以names和header的使用场景主要如下:
- csv文件有表头并且是第一行,那么names和header都无需指定;
- csv文件有表头、但表头不是第一行,可能从下面几行开始才是真正的表头和数据,这个时候指定header即可;
- csv文件没有表头,全部是纯数据,那么我们可以通过names手动生成表头;
- csv文件有表头、但是这个表头你不想用,这个时候同时指定names和header。先用header选出表头和数据,然后再用names将表头替换掉,其实就等价于将数据读取进来之后再对列名进行rename;
1.4 sep
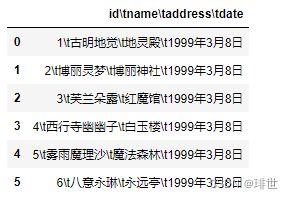
读取csv文件时指定的分隔符,默认为逗号。注意:“csv文件的分隔符” 和 “我们读取csv文件时指定的分隔符” 一定要一致。
比如:上面的girl.csv,我们将其分隔符从逗号改成"\t",如果这个时候还是用默认的逗号分隔符,那么数据读取之后便混为一体。
pd.read_csv("girl.csv")
pd.read_csv('girl.csv', sep='\t')
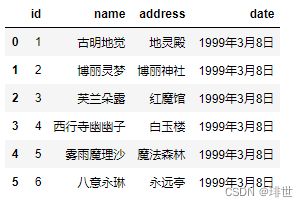
1.5 delimiter与delim_whitespace
delimiter是分隔符的另一个名字,与 sep 功能相似。
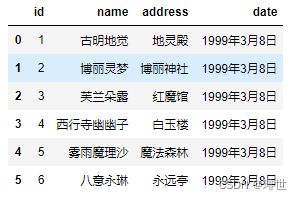
delim_whitespace是0.18 版本后新加参数,默认为 False,设置为 True 时,表示分割符为空白字符,可以是空格、"\t"等等。不管分隔符是什么,只要是空白字符,那么可以通过delim_whitespace=True进行读取。
pd.read_csv('girl.csv',delim_whitespace=True)
1.6 index_col
默认生成的DataFrame的索引默认是0 1 2 3…,也可以set_index,但是也可以在读取的时候就指定某个列为索引。
另外除了指定单个列,还可以指定多个列,比如[“id”, “name”]。并且我们除了可以输入列的名字之外,还可以输入对应的索引。比如:“id”、“name”、“address”、"date"对应的索引就分别是0、1、2、3。
pd.read_csv('girl.csv', index_col="name")
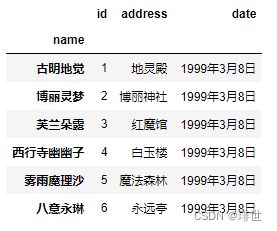
1.7 usecols
指定需要导出的列名称,当列有很多,而我们不想要全部的列、而是只要指定的列就可以使用这个参数。
pd.read_csv('girl.csv', usecols=["name", "address"])

1.8 nrows
设置一次性读入的文件行数,它在读入大文件时很有用
pd.read_csv('girl.csv', nrows=1)

1.9 dtype
用于指定某个列在输出为DataFrame的类型,避免出现类型设置错误。
pd.read_csv('girl.csv', dtype={"id": str})
此时将id列设置为str类型,否则会默认设置为int类型。
1.10 na_values
na_values 参数可以配置哪些值需要处理成 NaN,有两种方式:
- list:会识别list中的元素,将数据中所有相同的均设置为NaN,不区分列
- dict:设置列中的对应元素为NaN,区分列
pd.read_csv('girl.csv', na_values=["对", "古明地觉"])
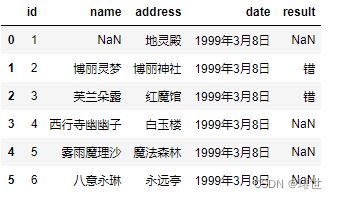
pd.read_csv('girl.csv', na_values={"name": ["古明地觉", "博丽灵梦"], "result": ["对"]})
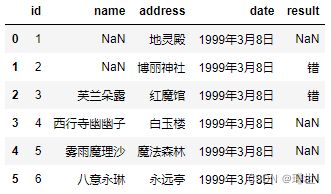
2. to_csv()
to_csv()是DataFrame类的方法,read_csv()是pandas的方法。
换句话说,to_csv()需要以DataFrame的数据为基础,而read_csv()则可以直接通过pandas使用。
import pandas as pd
data = {'a': 1, 'b': 2}
dt = pd.DateFrame(data)
2.1 path_or_buf
必须填写的内容项,需要以.csv文件为结尾。
- 若仅填写文件名,则会保存到此Python程序的地址
- 若填写绝对位置,则会按照位置,文件名称进行保存
dt.to_csv('girl.csv') #相对位置,保存在getwcd()获得的路径下
dt.to_csv('C:/Users/think/Desktop/girl.csv') #绝对位置
2.2 sep
设置csv的分隔符,默认为“,”,若需要使用其他分隔符,则可以设置。
dt.to_csv('C:/Users/think/Desktop/girl.csv', sep='.')
2.3 na_rep
替换空值,若DataFrame中有值为空,则保存时也会保存为空值,配置此参数则可以设置空值内容。
dt.to_csv('C:/Users/think/Desktop/girl.csv',na_rep='NA') #确实值保存为NA,如果不写,默认是空
2.4 float_format
针对浮点数值,设置保存的小数位数。
dt.to_csv('C:/Users/think/Desktop/girl.csv',float_format='%.2f') #保留两位小数
2.5 columns
设置保存的列,若不配置则默认保存所有列。
dt.to_csv('C:/Users/think/Desktop/girl.csv',columns=['name']) #保存索引列和name列
2.6 header
设置是否保存列名,默认保存列名为第一行,若设置0则不保存列名。
dt.to_csv('C:/Users/think/Desktop/girl.csv',header=0) #不保存列名
2.7 index
设置是否保存行索引,默认保存行索引为第一列,若设置0则不保存。
dt.to_csv('C:/Users/think/Desktop/girl.csv',index=0) #不保存行索引
参考:
详解pandas的read_csv方法