目标检测精度评价指标
在目标检测领域中,存在着很多精度评价指标,需要根据应用场景自主的选择更合适的评价指标。
有人举过一些很典型的例子:
倘若某人声称创建了一个能够识别登上飞机的恐怖分子的模型,并且准确率(accuracy)高达 99%。你相信吗?假如这么一个模型:将从美国机场起飞的所有乘客均标注为非恐怖分子。已知美国全年平均有 8 亿人次的乘客,并且在 2000-2017 年间共发现了 19 名恐怖分子,这个模型达到了接近完美的准确率——99.99%。但是这个模型并不会是我们想要的。
下面将罗列一些常见的指标。
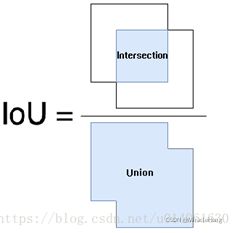
IOU
IoU用于衡量分类器预测出来的目标框与原来图片中标记的框的重合程度。计算方法即检测结果Detection Result与 Ground Truth 的交集(Intersection)比上它们的并集(Union),即为检测的准确率。
TP(true positive)、TN(true negative)、FP(false positive)、FN(false negative)
第一个字母表示本次预测的正确性,T就是正确,F就是错误;第二个字母则表示由分类器预测的类别,P代表预测为正例,N代表预测为反例。比如TP我们就可以理解为分类器预测为正例(P),而且这次预测是对的(T),FN可以理解为分类器的预测是反例(N),而且这次预测是错误的(F),正确结果是正例,即一个正样本被错误预测为负样本。
| 检测到 |
未检测到 |
|
| 正例 |
true positive |
false negative |
| 负例 |
false positive |
true negative |
精确率 Precision(==查准率)
Precision是整个测试集上,被分类器识别出来的结果中,正确分类个数所占的比率,即衡量的是分类器对数据集错分的情况。
Precision=TP/(TP+FP)
召回率 Recall(==查全率)
Recall是在在测试集中,所有正样本被正确识别的概率,即衡量的是分类器对数据集的漏检情况。
Recall=TP/(TP+FN)
F1-Score
单一的Precision和Recall均可以侧面反映分类器的性能指标,但是正如同前边例子,单一的评价指标很难宏观的表现分类器的好坏。F1 score可以联合评价精确率和召回率:

值得注意的是,对于F1 score来说,计算仅适用到Precision、Recall二者均是针对特定的confidence所计算的(如P-R曲线中的一个点,可以对应一个F1 score,这样说可能便于理解)。
P-R曲线
按confidence顺序计算,使得系统依次能够识别前K张图片,以Recall为横坐标从而得到曲线。
如果一个分类器的性能比较好,那么它应该有如下的表现:在Recall值增长的同时,Precision的值保持在一个很高的水平。而性能比较差的分类器可能会损失很多Precision值,才能换来Recall值的提高。很多文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡。
平均精度 AP
Precision-recall 曲线下面的面积,关于这点如果你看过其他博客应该已经有所了解,通常来说一个越好的分类器,AP值越高。如下图,蓝线下方的面积就是该类别的AP值。
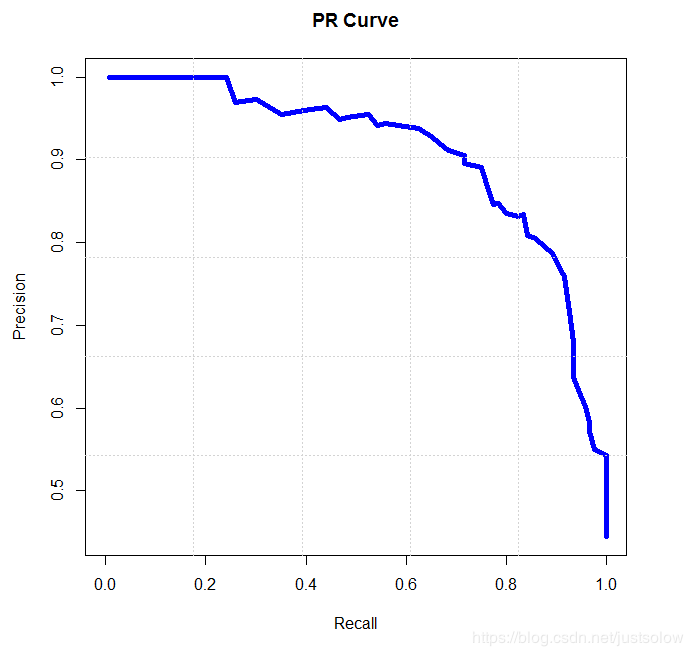
引用一个例子:
在计算时,对任意类别,通常根据confidence值对测试集上所有结果筛选,从高到低排序,根据IOU阈值判别。在P-R曲线的时候已经说过,曲线的生成是根据confidence,所以需要共同关注confidence和IOU的阈值。
目标检测中,这里假设我们算一个目标的AP。我们有以下输出(BB表示Bounding Box序号,IOU>0.5时GT=1):
先给出前提,GT共有7个,BB为GT的bounding box编号。
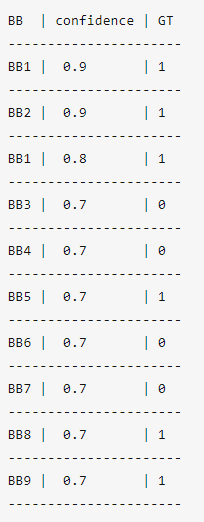
因此,我们有 TP=5 (BB1, BB2, BB5, BB8, BB9), FP=5 (重复检测到的BB1也算FP,已经检测到一个置信度高的了)。已知共有7个GT,除了表里检测到的5个GT以外,还有两个GT未检测到,因此: FN = 2. 这时我们就可以按照Confidence的顺序给出各处的PR值,如下:
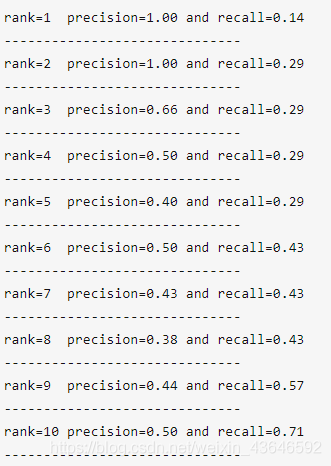
rank1为例:Precision = 1/1(检测出1个结果,正确的是1个) Recall = 1/7(共7个目标只有1个被检测到).
rank2为例:Precision = 2/2(检测出2个结果,正确的是2个) Recall = 2/7(共7个目标只有2个被检测到)。
rank3为例:Precision = 2/3(检测出3个结果,正确的是2个) Recall = 2/7(共7个目标只有2个被检测到)--如上所说已经检测到一个BB1了。
在VOC2010与VOC2007中采用了不同的标准,VOC2010根据所有的Recall来设置。在本例中,Recall分为[0.14,0.29,0.43,0.57,0.71],仅统计对应的Precision(只统计最大值)。以此分别为X与Y轴绘制P-R曲线并计算面积---AP。
再来个例子
例如,对于测试集两张图片,总目标个数为3,检测出4个结果。按confidence为0.66过滤。
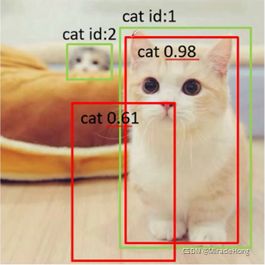

得到如下统计结果
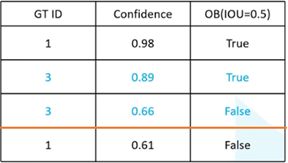
第一行数据,计算以此P-R。TP个数为1,FP个数为0个,FN个数为2个。
第二行数据,计算一次P-R。TP个数为2,FP个数为0个,FN个数为1个。
第三行数据,计算一次P-R。TP个数为2,FP个数为1个,FN个数为1个。
全类别平均精度 mAP(mean Average Precision)
是多个类别AP的平均值。得到的就是mAP的值,mAP的大小一定在[0,1]区间,越大越好。该指标是目标检测算法中最重要的一个。
TOP-N error
Top-N是指:分类结果给出的前N个可能的类别中出现正确类别的概率。主要针对于图像分类应用场景,因为对人类来说同一张图片可能存在多个类别,所以出现top-5等指标。
总结
通常情况下,采用单一的Precision以及Recall很难平衡各个场景下的分类任务。例如,当样本不均衡是,如正样本10,负样本990,这时即使模型把1000个样本全部预测为负样本,准确率(Accuracy)也有99%,显然存在问题。因为F1 score主要考虑的单点情况(ap上的一个点就对应一个F1 score),缺少全局性能的反馈,所以目前最常用的目标检测精度评价指标是mAP,均衡考虑测试集上所有类别的精确率以及召回率。并且可通过设置不同的IOU阈值,得到分类器不同精度标准下的性能指标。
另外,对于数据局集中存在的目标尺度不同的现象,还在AP的基础上有针对小、中、大不同尺度所设置的APsmall (像素面积小于32*32),APmedium (像素面积小于96*96),APlarge (像素面积大于96*96)等指标,以满足对于各个尺度目标评价的需要。
Top-N主要用于图像分类任务,分类器得到整个图像的类别,根据前N个类别是否存在正确的目标来评价分类器的性能,在目标检测任务中并不常用。
参考:
Recall, Precision, AP, mAP的计算方法(看一次就懂系列)_#苦行僧的博客-CSDN博客
目标检测mAP计算以及coco评价标准_哔哩哔哩_bilibili
准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure - stardsd - 博客园
牢记分类指标:准确率、精确率、召回率、F1 score以及ROC - 简书