高性能MySQL(InnoDB)
目录
一、七个查询命令
二、索引
2.1 索引结构
2.1.1 B+树索引(B+Tree)
2.1.2 哈希索引
2.1.3 全文索引
三、事物
3.1、事物的四个特征
3.1.1、原子性(Atomicity)
3.1.2、一致性(Consistency)
3.1.3、隔离型(Isolation)
3.1.4、持久性(Durability)
3.2、事物隔离级别
3.3、事物实现
四、锁
4.1 锁类型
4.1.1、一致性非锁定读
4.1.2 一致性锁定读
4.2 锁的算法
五、高可用方案
六、SQL优化
一、七个查询命令
| 命令 | 说明 |
| FROM | FROM的作用是嫁给你磁盘上的表文件加载到内存中,生成一个全新的临时表或者定位内存中已经存在的命名临时表;在一个查询语句中第一个执行的命令总是from |
| WHERE | where 命令逐行操作由from命令生成的临时表数据行,将满足条件的数据行保存到一个全新的临时表;因此where条件中是可能出现聚合函数的 |
| GROUP BY | 首先对临时表中的数据进行一次排序,然后它将具有相同特征的数据行去保存到同一个临时表中,针对多字段分组,从第二个字段开始操作的是前一个分组字段生成的临时表 |
| HAVING | 负责删除group by生成的临时表中不满足条件的临时表,只能出现在group by之后 |
| SELECT | select操作的临时表由from或where提供的时候,会将指定的字段读取出来创建一个全新的临时表 如果select 由 group by或having提供的时候,select会逐个遍历每个临时表 |
| ORDER BY | 针对select生成的临时表进行排序,将排序后的内容组成全新的临时表 |
| LIMIT | 对当前临时表中的数据行进行截取 |
二、索引
索引在MySQL中也叫键是存储引擎用于快速查找记录的一种数据结构,对于表中数据量较多时,索引对于查询性能的影响夜愈发重要;了解索引对于优化SQL至关重要。
2.1 索引结构
2.1.1 B+树索引(B+Tree)
B+树所有数据都是按照键值大小顺序存在中同一层的叶子节点中,叶子节点之前油指针相连。由于B+数对索引列是顺序组织存储的,所以特别适合范围查找。
下图是一个键值为5,10,15,20,25,30,50,55,60,65,70,75,80,85,90的B+树结构
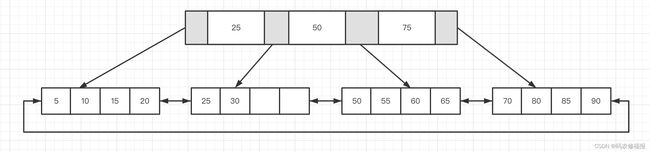
根据叶子节点是否存放一整行数据可以将B+树索引分为聚集索引和辅助索引
聚集索引
聚集索引(Clustered Index)就是按照每张表的主键构造一个B+树,同时叶子节点保存完整的行记录数据;一张表有且必须有也只能有一个聚集索引
辅助索引
辅助索引也可以称为非聚集索引,叶子结点并不包含行记录的所有数据,它除列包含键值外,包含一个指向行记录的指针
覆盖索引
如果通过辅助索引查询数据,首先是根据辅助索引找到对应的叶子节点,在根据叶子节点中的指针到聚集索引中找到对应的行记录;这个过程就叫做回表。有没有办法直接通过辅助索引查询到所需要的数据而不需要回表呢?这个时候就需要使用到覆盖索引。覆盖索引就是针对需要的查询数据列做一个联合索引(联合索引是指对标上的多列进行索引)
B+树索引查询类型
| 查询类型 | 说明 |
| 全值匹配 | 是指和索引中的键值进行匹配 |
| 最左前缀匹配 | 只使用索引的第一列 |
| 列前缀匹配 | 根据字段前缀 like匹配 |
| 覆盖索引 |
2.1.2 哈希索引
哈希索引是基于哈希表实现的一种索引,键值是索引列的哈希值,值是保存指向行记录的指针,因此哈希索引接口十分紧凑,查询速度快,但是限制也很明显
- 索引中只存储了hashCode 不能使用覆盖索引优化查询
- 哈希索引不是按照顺序组织数据,无法用于排序,不支持范围查找
- 由于hashCode 是根据全部索引列计算出来的,只能支持精确查找不支持匹配查找
在InnoDB中有一个特殊功能叫做自适用哈希索引;当InnoDB发现某些索引被频繁使用时,会在B+树索引之上创建一个哈希索引优化索引查询效率。这部分是InnoDB内部的优化是无法人工干预的。
2.1.3 全文索引
全文索引是一种特殊的索引类型,它查找的是文本中的关键词,而不是直接匹配索引的值。其语法格式是 select * from table where match(col) against(value)
三、事物
事物(Transaction)是数据库系统区别与文件系统的的重要特征之一。
3.1、事物的四个特征
事物的特征可以缩写为ACID,他们分别代表原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)
3.1.1、原子性(Atomicity)
原子性是指事物是一组不可分割的单元,要么同时成功要么同时失败
3.1.2、一致性(Consistency)
一致性是指在事物开始之前和事物结束以后数据库的完整性没有遭到破坏
3.1.3、隔离型(Isolation)
隔离性是指事物之间是相互隔离的,事物没有提交之前,对于数据的修改对于其他事务是不可见的
3.1.4、持久性(Durability)
持久性是指事物一旦提交,其结果就永久性的;即使发生宕机等事故,数据库也能将数据恢复。
3.2、事物隔离级别
ISO标准定义了数据库的四种隔离级别,分别是:
- Read Uncommitted(读未提交)
- Read Committed(读已提交)
- Repeatable Read(可重复读)
- Searializable(串行)
3.3、事物实现
事物的原子性、一致性、持久性是通过数据的redo log和undo log来完成的。redo log称为重做日志,用来保证事物的原子性和持久性;undo log 用来保证事物的一致性,事物的隔离性是通过锁来实现。
3.3.1 redo
redo log是由两部分组成:
- 内存中的重做日志缓冲区(redo log buffer)它是易失的
- 重做日志文件(redo log file),它是持久化的
InnoDB存储引擎是通过Force Log at Commit机制来保证事物的持久性;即当事物提交时,必须先将该事物的所有日志写入到日志文件中进行持久化才算事物提交完成。为了保证每次日志都写入到日志文件中,在每次将重做日志缓冲区写入到重做日志文件后,必须进行一次fsync操作。由于fsync的效率取决于磁盘性能,因此磁盘的性能决定了事物提交性能。 可以通过innodb_flush_log_at_trx_commit参数类平衡持久性和数据库性能。
| 参数值 | 含义 |
| 0 | 事物提交时不写重做人日文件,由主线程每隔1秒进行一次fsync调用 |
| 1 | 默认值,事物提交时必须进行一次fsync调用 |
| 2 | 事物提交时写入重做日志文件,但是不进行fsync调用 |
3.1.2 redo log 与 binlog
Mysql的binlog表面上看和redo log 很像,都是记录数据库的操作日志,但是本质上有很大区别
| redo log | binlog | |
| 生产层次 | InnDB存储引擎生产 | Mysql数据库生产,不管使用什么存储引擎都会有binlog |
| 内容格式 | 物理格式日志,记录的是对于数据页的修改 | 逻辑格式日志,记录的是对应的SQL语句 |
| 写入时间点 | 事物进行中不断写入 | 事物提交完成后进行一次写入 |
3.1.3 undo
事物需要回滚时候需要使用undo ,因此在对于数据库进行修改时,InnoDB存储引擎不但会产生redo log 还会产生undo。undo存在在数据库内部的一个特殊段(segment)中,因此成为undo 段。
四、锁
锁是数据库系统区别文件系统的一个主要特性,数据库是通过锁来支持对共享资源的并发访问控制以及保证数据的完整性和一致性。
4.1 锁类型
在InnoDB中支持两种级别的行锁共享锁(S Lock)和互斥锁(X Lock),除了行级别的锁外InnoDB也支持表级别的锁称之为意向锁,意向共享锁(IS Lock)和意向互斥锁(IX Lock)
| IS | IX | S | X | |
| IS | 兼容 | 兼容 | 兼容 | 不兼容 |
| IX | 兼容 | 兼容 | 不兼容 | 不兼容 |
| S | 兼容 | 不兼容 | 兼容 | 不兼通 |
| X | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
4.1.1、一致性非锁定读
一致性非锁定读是指InnoDB存储引擎通过多版本并发控制(MVCC)的方式来读取当前执行时间数据库中的数据,如果读取的行正在执行delete或update操作,这时不会等待锁释放而是读取该行的快照数据。对于不同隔离级别来将快照数据定义是不同的
| 隔离级别 | 快照数据 |
| Read Committed | 总是读取锁定行的最新一条快照数据 |
| Repeatable read | 读取事物开始时候的快照数据 |
4.1.2 一致性锁定读
一致性锁定读,InnoDB 支持两种方式
| 锁定方式 | 锁类型 |
| SELECT ... FOR UPDATE |
X 锁 |
| SELECT ... LOCK IN SHARE MODE | S 锁 |
4.2 锁的算法
InnoDB存储引擎有三种行锁算法
| 锁算法 | 说明 |
| Record Lock | 单行记录上加锁 |
| Gap Lock | 间隙锁,锁定一个不包含本身的范围 |
| Next-Key Lock | 锁定一个包含本身的范围,Gap Lock+Record Lock |