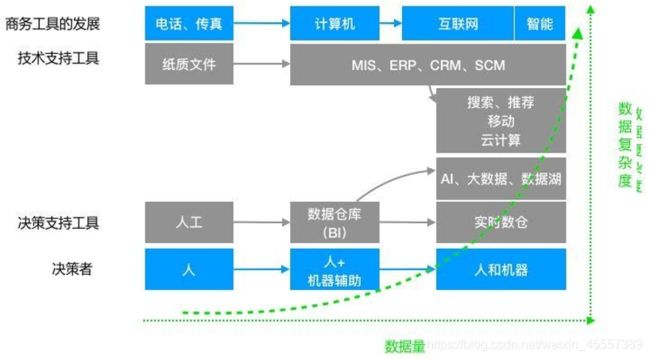
大数据架构演进
1、数仓架构演变(场景驱动)
1.1 经典数仓架构
数据仓库概念是Inmon于1990年提出并给出了完整的建设方法
1.2 离线大数据架构
随着互联网时代来临,数据量暴增,开始使用大数据工具来代替经典数仓中的传统工具
此时仅仅是工具的取代,架构上并没有根本的区别,可以把这个架构叫做离线大数据架构
1.3 Lambda架构
后来随着业务实时性要求的不断提高,人们开始在离线大数据架构基础上加了一个加速层,使用流处理技术直接完成那些实时性要求较高的指标计算,这便是Lambda架构
1.4 Kappa架构
再后来,实时的业务越来越多,事件化的数据源也越来越多,实时处理从次要部分变成了主要部分,架构也做了相应调整,出现了以实时事件处理为核心的Kappa架构
t+1,前一天的数据,第二天计算出结果,离线数仓指标大部分都是t+1
t+2,数据出结果需要等两天
2、离线大数据架构
离线大数据架构的特点:
- 数据源通过离线的方式导入到离线数仓中
- 数据处理采用MapReduce、Hive、SparkSQL等离线计算引擎

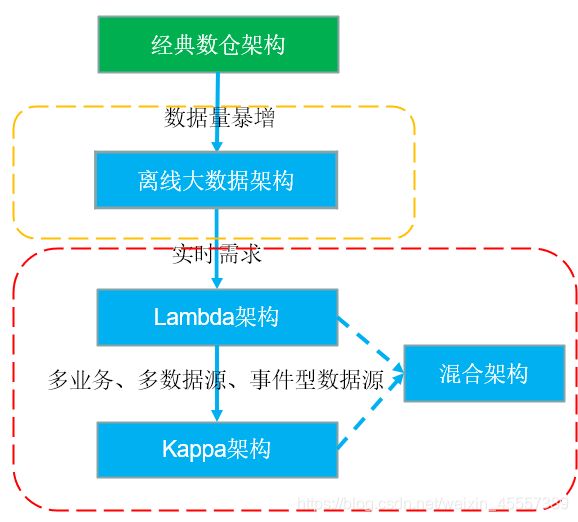
3、离线数仓分层
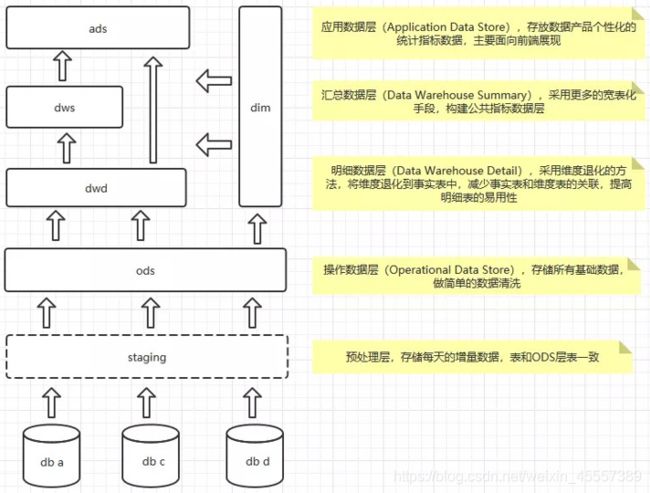
4、Lambda架构
随着大数据应用的发展,人们逐渐对系统的实时性提出了要求,为了计算一些实施指标,就在原来离线数仓的基础上增加了一个实时计算的链路,并对数据源做流式改造(即把数据发送到消息队列),实时计算去订阅消息队列,直接完成指标做增量的计算,推送到下游的数据服务中去,由数据服务层完成离线&实时结果的合并
实时计算链路内部是否分层,取决于指标的复杂度,各层之间通过消息队列交互(多半是不分层的)
流处理计算的指标批处理依然计算,最终以批处理为准,即每次批处理计算后会覆盖流处理的结果(这仅仅是流处理引擎不完善做的折中)

实时数仓的技术栈:数据采集层面,针对mysql会加一个binlog
计算层面:flink,spark streaming
数据中间分层:主要是kafka,不一定分层,分层的标准,没有离线这么严格
结果保留,中间数据:es,mysql
4.1 Lambda架构进一步理解
4.2 Lambda架构典型案例

有赞广告团,基于Druid

4.3 Lambda架构存在的问题
-
同样的需求需要开发两套一样的代码
这是Lambda架构最大的问题,两套代码不仅仅意味着开发困难(同样的需求,一个在批处理引擎上实现,一个在流处理引擎上实现,还要分别构造数据测试保证两者结果一致),后期维护更加困难,比如需求变更后需要分别更改两套代码,独立测试结果,且两个作业需要同步上线
-
资源占用增多
同样的逻辑计算两侧,整体资源占用会增多(多出实时计算这部分)
-
实时链路和离线链路数据差异容易让业务方困惑
例如业务方会发现,次日看到的数据比昨晚看到的要少。原因在于:数据在被放入Result Database时,走了两条线的计算方式:一条线是ETL按照某个口径“跑”过来,得到更为准确的批量处理结果;另一条线是通过Streaming“跑”过来,依靠Hadoop Hive或其它算法得出的实时性结果。当然它牺牲了部分的准确性。可见,这两个来自批量的和实时的数据结果是对不上的,因此大家觉得很困惑
5、Kappa架构
Lambda架构虽然满足了实时的需求,但带来了更多的开发与运维工作,其架构背景是流处理引擎还不完善,流处理的结果只作为临时的、近似的值提供参考
后来随着Flink等流处理引擎的出现,流处理技术很成熟了,这是为了解决两套代码的问题。Linkedln的Jay Kreps提出了Kappa架构
在实时计算中可以直接完成计算,也可以跟离线数仓一样分层,取决于指标的复杂度,各层之间通过消息队列交互(多半是不分层的)
Kappa架构可以认为是Lambda架构的简化版(只要移除Lambda架构中的批处理部分即可)

5.1 Kappa架构典型案例
Kappa架构来构建数仓是妥妥的实时数仓,每个需求都自己开发流处理代码比较繁琐,一个较好的办法是借助OLAP引擎,主流的引擎如下(个别的严格意义上来说不是OLAP引擎,但是具备相应功能):
| 对比项目 | Druid | Kylin | Presto | Impala | Spark SQL | ES |
|---|---|---|---|---|---|---|
| 亚秒级响应 | Y | Y | N | N | N | N |
| 百亿数据集 | Y | Y | Y | Y | Y | Y |
| SQL支持 | N(开发中) | Y | Y | Y | Y | N |
| 离线 | Y | Y | Y | Y | Y | Y |
| 实时 | Y | N(开发中) | N | N | N | Y |
| 精确去重 | N | Y | Y | Y | Y | N |
| 多表Join | N | Y | Y | Y | Y | N |
| JDBC for BI | N | Y | Y | Y | Y | N |
以Kylin为例
- Kylin3.0还没发稳定版
- Kylin3.0本身是Kappa架构,但是支持Lambda架构
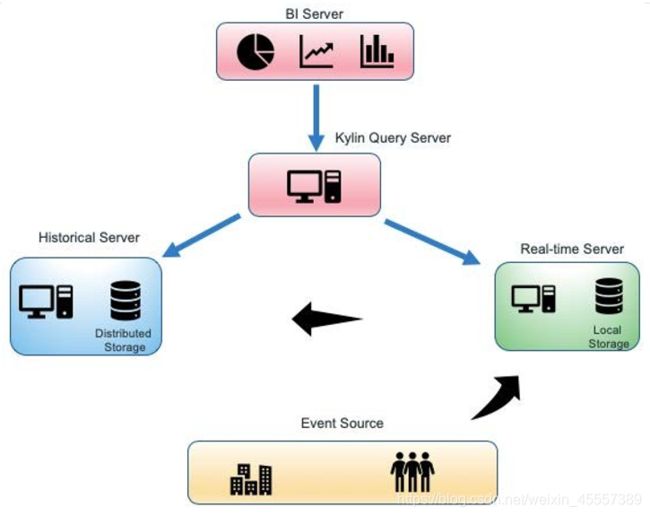
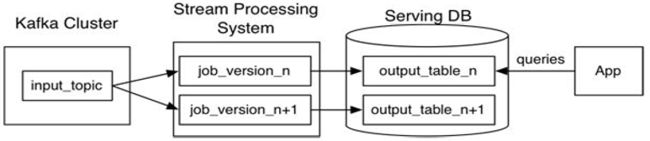
5.2 Kappa架构的重新处理过程
在Kappa架构中,即使流处理引擎再健壮,由于上游数据原因,仍然存在数据重新处理的需求
修改数据或历史数据重新处理都通过上游重放完成(从数据源拉取数据重新计算一次)
Kappa架构最大的问题是流式重新处理历史数据的吞吐能力会低于批处理,但这个可以通过增加计算资源来弥补
重新处理是人们对Kappa架构最担心的点,但实际上并不复杂:
- 选择一个具有重放功能的、能够保存历史数据并支持多消费者的消息队列,根据需求设置历史数据保存的时长,比如Kafka,可以保存全部历史数据
- 当某个或某些指标有重新处理的需求时,按照新逻辑写一个新作业,然后从上游消息队列的最开始重新消费,把结果写到一个新的下游表中
- 当新作业赶上进度后,应用切换数据源,读取2中产生的结果表
- 停止老的作业,删除老的结果表
6、Lambda架构和Kappa架构的对比
| 对比项 | Lambda | Kappa |
|---|---|---|
| 实时性 | 实时 | 实时 |
| 计算资源 | 批和流同时运行,资源消耗大 | 只有流处理,资源开销小 |
| 重新计算吞吐量 | 批式全量处理,吞吐较高 | 流式全量处理,吞吐较批式全量要低一些 |
| 开发、测试难度 | 每个需求都需要批处理和流处理两套代码,开发、测试、上线难度大一些 | 只需要实现一套代码,开发、测试、上线难度相对较小 |
| 运维成本 | 维护两套系统(引擎),运维成本大 | 维护一套系统(引擎),运维成本较小 |
7、实时数仓 VS 离线数仓
首先,从架构上,实时数仓与离线数仓有比较明显的区别,实时数仓以Kappa架构为主,而离线数仓以传统大数据架构为主。Lambda架构可以认为是两者的中间态。目前业界所说的实时数仓大多是Lambda架构,这是由需求决定的
其次,从建设方法上,实时数仓和离线数仓基本还是沿用传统的数仓主题建模理论,产出事实宽表。另外实时数仓中实时流数据的join有隐藏时间语义,在建设中需注意
最后,从数据保障看,实时数仓因为要保证实时性,所以对数据量的变化较为敏感。在大促等场景下需要提前做好压测和主备保障工作,这是与离线数据的一个较为明显的区别
实际业务中如何选择呢?
- 看具体业务需求
- 在真是的场景中,很多时候并不是完全规范的Lambda架构或Kappa架构,可以是两者的混合,比如大部分实时指标使用Kappa架构完成计算,少量关键指标(比如金融相关)使用Lambda架构用批处理重新计算,增加一次校对程
- 离线大数据架构在很多公司仍然比较实用(性价比高)
现状:混合架构大行其道
为了应对更广泛的场景,大多数公司采用混合架构
- 从架构层面来看是Lambda架构和Kappa架构混合
- 从数仓形态来说是离线数仓和实时数仓混合
通俗来讲:离线和实时数据链路都存在,根据每个业务需求选择在合适的链路上来实现
8、数仓的发展趋势
- 实时数据仓库:满足实时化&自动化决策需求
- 大数据&数据湖:支持海量、复杂数据类型(文本、图像、视频、音频)